#include <linux/types.h>#include <linux/kvm_host.h>#include <asm/kvm_host.h>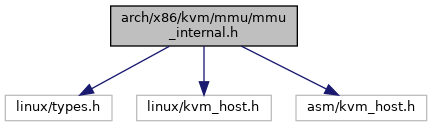
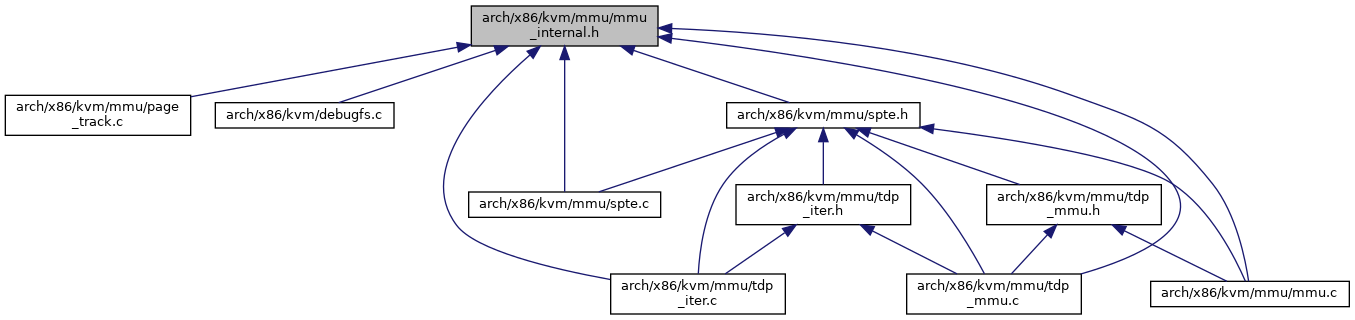
Go to the source code of this file.
Classes | |
| struct | kvm_mmu_page |
| struct | kvm_page_fault |
Macros | |
| #define | KVM_MMU_WARN_ON(x) BUILD_BUG_ON_INVALID(x) |
| #define | __PT_BASE_ADDR_MASK GENMASK_ULL(51, 12) |
| #define | __PT_LEVEL_SHIFT(level, bits_per_level) (PAGE_SHIFT + ((level) - 1) * (bits_per_level)) |
| #define | __PT_INDEX(address, level, bits_per_level) (((address) >> __PT_LEVEL_SHIFT(level, bits_per_level)) & ((1 << (bits_per_level)) - 1)) |
| #define | __PT_LVL_ADDR_MASK(base_addr_mask, level, bits_per_level) ((base_addr_mask) & ~((1ULL << (PAGE_SHIFT + (((level) - 1) * (bits_per_level)))) - 1)) |
| #define | __PT_LVL_OFFSET_MASK(base_addr_mask, level, bits_per_level) ((base_addr_mask) & ((1ULL << (PAGE_SHIFT + (((level) - 1) * (bits_per_level)))) - 1)) |
| #define | __PT_ENT_PER_PAGE(bits_per_level) (1 << (bits_per_level)) |
| #define | INVALID_PAE_ROOT 0 |
| #define | IS_VALID_PAE_ROOT(x) (!!(x)) |
Typedefs | |
| typedef u64 __rcu * | tdp_ptep_t |
Enumerations | |
| enum | { RET_PF_CONTINUE = 0 , RET_PF_RETRY , RET_PF_EMULATE , RET_PF_INVALID , RET_PF_FIXED , RET_PF_SPURIOUS } |
Functions | |
| static hpa_t | kvm_mmu_get_dummy_root (void) |
| static bool | kvm_mmu_is_dummy_root (hpa_t shadow_page) |
| static int | kvm_mmu_role_as_id (union kvm_mmu_page_role role) |
| static int | kvm_mmu_page_as_id (struct kvm_mmu_page *sp) |
| static bool | kvm_mmu_page_ad_need_write_protect (struct kvm_mmu_page *sp) |
| static gfn_t | gfn_round_for_level (gfn_t gfn, int level) |
| int | mmu_try_to_unsync_pages (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t gfn, bool can_unsync, bool prefetch) |
| void | kvm_mmu_gfn_disallow_lpage (const struct kvm_memory_slot *slot, gfn_t gfn) |
| void | kvm_mmu_gfn_allow_lpage (const struct kvm_memory_slot *slot, gfn_t gfn) |
| bool | kvm_mmu_slot_gfn_write_protect (struct kvm *kvm, struct kvm_memory_slot *slot, u64 gfn, int min_level) |
| static void | kvm_flush_remote_tlbs_gfn (struct kvm *kvm, gfn_t gfn, int level) |
| unsigned int | pte_list_count (struct kvm_rmap_head *rmap_head) |
| static bool | is_nx_huge_page_enabled (struct kvm *kvm) |
| int | kvm_tdp_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | kvm_mmu_do_page_fault (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u32 err, bool prefetch, int *emulation_type) |
| int | kvm_mmu_max_mapping_level (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t gfn, int max_level) |
| void | kvm_mmu_hugepage_adjust (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
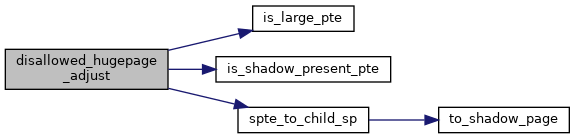
| void | disallowed_hugepage_adjust (struct kvm_page_fault *fault, u64 spte, int cur_level) |
| void * | mmu_memory_cache_alloc (struct kvm_mmu_memory_cache *mc) |
| void | track_possible_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
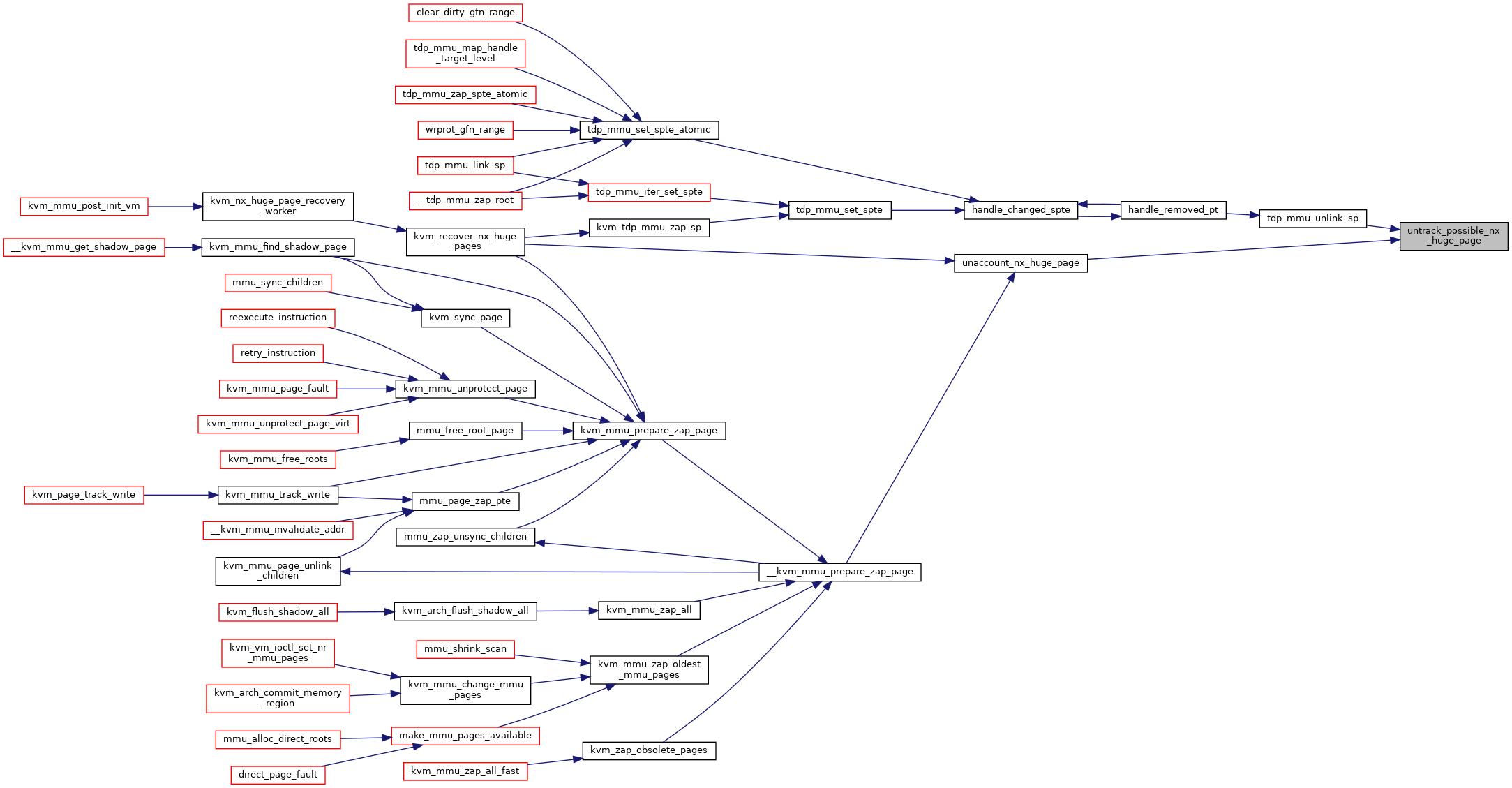
| void | untrack_possible_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
Variables | |
| struct kmem_cache * | mmu_page_header_cache |
| int | nx_huge_pages |
Macro Definition Documentation
◆ __PT_BASE_ADDR_MASK
| #define __PT_BASE_ADDR_MASK GENMASK_ULL(51, 12) |
Definition at line 16 of file mmu_internal.h.
◆ __PT_ENT_PER_PAGE
| #define __PT_ENT_PER_PAGE | ( | bits_per_level | ) | (1 << (bits_per_level)) |
Definition at line 28 of file mmu_internal.h.
◆ __PT_INDEX
| #define __PT_INDEX | ( | address, | |
| level, | |||
| bits_per_level | |||
| ) | (((address) >> __PT_LEVEL_SHIFT(level, bits_per_level)) & ((1 << (bits_per_level)) - 1)) |
Definition at line 19 of file mmu_internal.h.
◆ __PT_LEVEL_SHIFT
| #define __PT_LEVEL_SHIFT | ( | level, | |
| bits_per_level | |||
| ) | (PAGE_SHIFT + ((level) - 1) * (bits_per_level)) |
Definition at line 17 of file mmu_internal.h.
◆ __PT_LVL_ADDR_MASK
| #define __PT_LVL_ADDR_MASK | ( | base_addr_mask, | |
| level, | |||
| bits_per_level | |||
| ) | ((base_addr_mask) & ~((1ULL << (PAGE_SHIFT + (((level) - 1) * (bits_per_level)))) - 1)) |
Definition at line 22 of file mmu_internal.h.
◆ __PT_LVL_OFFSET_MASK
| #define __PT_LVL_OFFSET_MASK | ( | base_addr_mask, | |
| level, | |||
| bits_per_level | |||
| ) | ((base_addr_mask) & ((1ULL << (PAGE_SHIFT + (((level) - 1) * (bits_per_level)))) - 1)) |
Definition at line 25 of file mmu_internal.h.
◆ INVALID_PAE_ROOT
| #define INVALID_PAE_ROOT 0 |
Definition at line 37 of file mmu_internal.h.
◆ IS_VALID_PAE_ROOT
| #define IS_VALID_PAE_ROOT | ( | x | ) | (!!(x)) |
Definition at line 38 of file mmu_internal.h.
◆ KVM_MMU_WARN_ON
| #define KVM_MMU_WARN_ON | ( | x | ) | BUILD_BUG_ON_INVALID(x) |
Definition at line 12 of file mmu_internal.h.
Typedef Documentation
◆ tdp_ptep_t
| typedef u64 __rcu* tdp_ptep_t |
Definition at line 50 of file mmu_internal.h.
Enumeration Type Documentation
◆ anonymous enum
| anonymous enum |
| Enumerator | |
|---|---|
| RET_PF_CONTINUE | |
| RET_PF_RETRY | |
| RET_PF_EMULATE | |
| RET_PF_INVALID | |
| RET_PF_FIXED | |
| RET_PF_SPURIOUS | |
Definition at line 273 of file mmu_internal.h.
Function Documentation
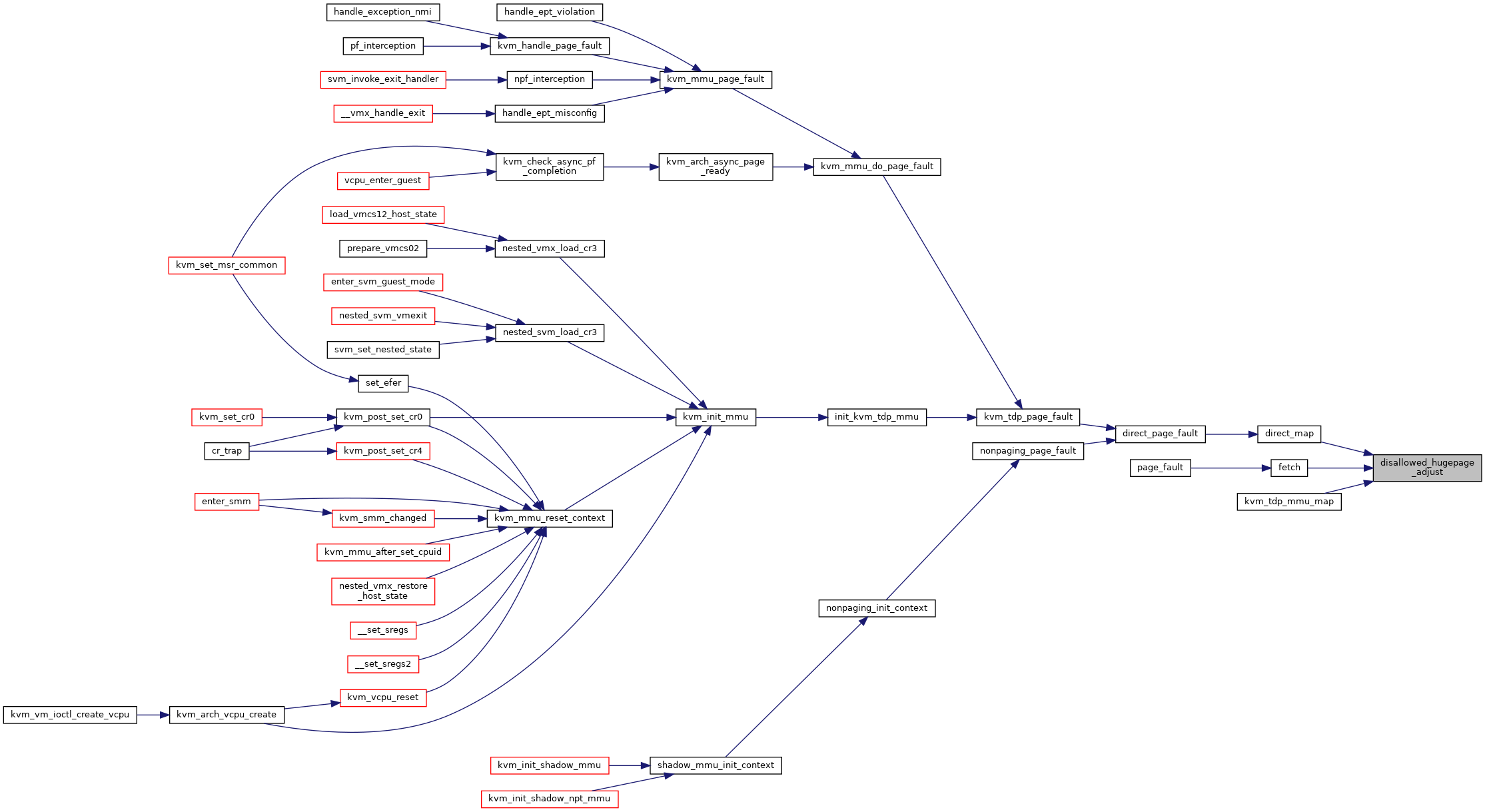
◆ disallowed_hugepage_adjust()
| void disallowed_hugepage_adjust | ( | struct kvm_page_fault * | fault, |
| u64 | spte, | ||
| int | cur_level | ||
| ) |
◆ gfn_round_for_level()
|
inlinestatic |
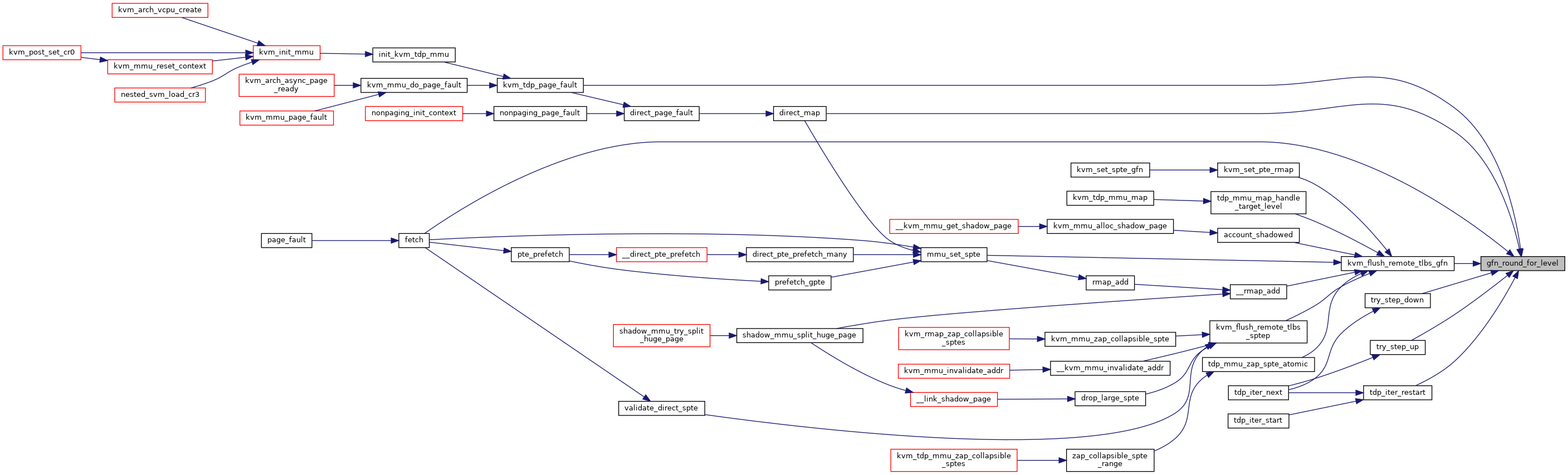
◆ is_nx_huge_page_enabled()
|
inlinestatic |

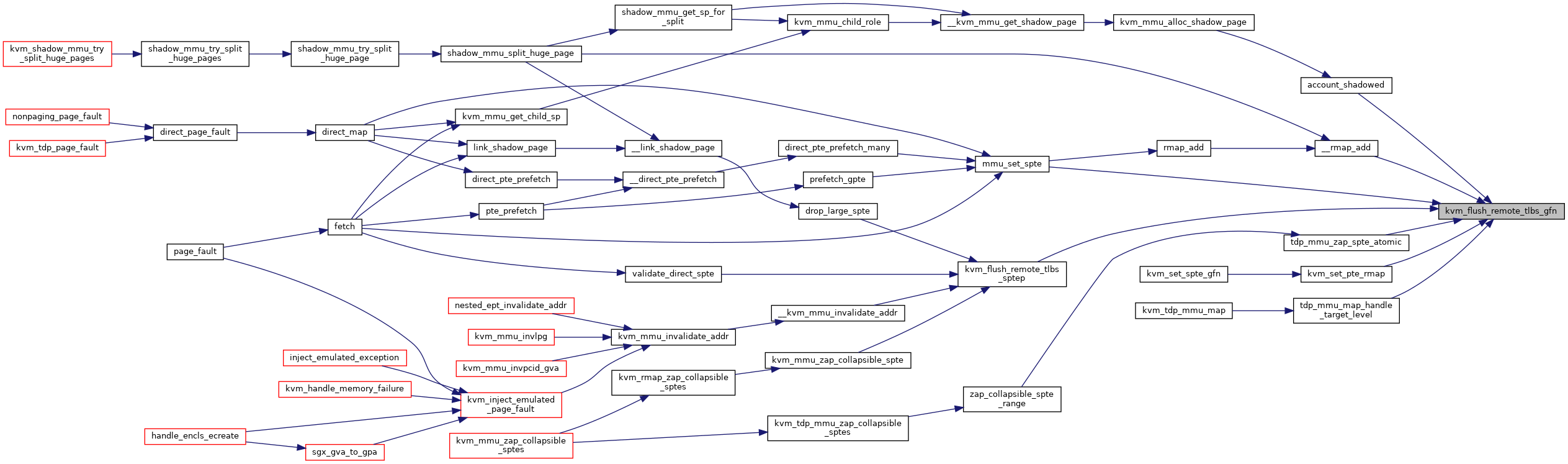
◆ kvm_flush_remote_tlbs_gfn()
|
inlinestatic |
Definition at line 176 of file mmu_internal.h.

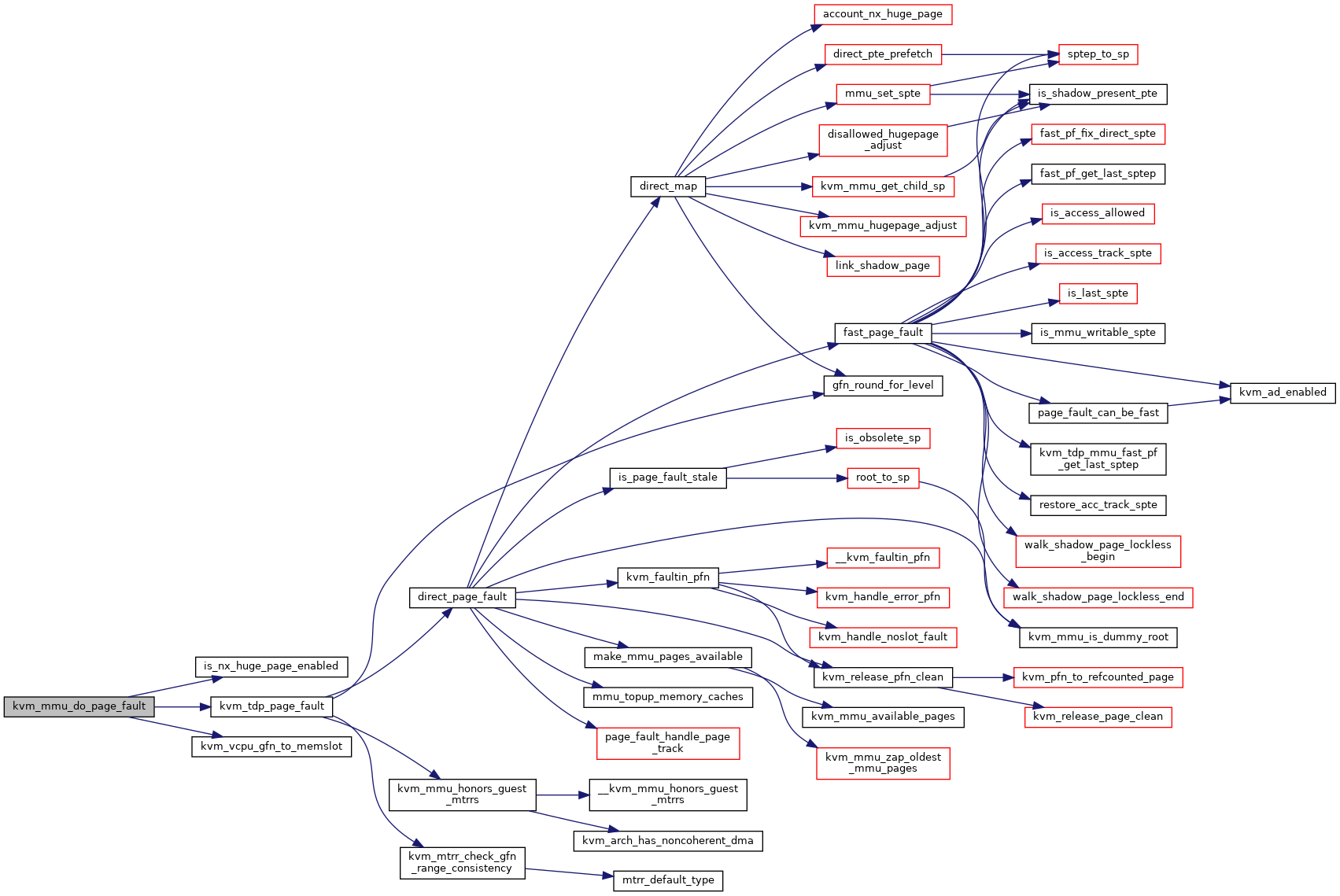
◆ kvm_mmu_do_page_fault()
|
inlinestatic |
Definition at line 282 of file mmu_internal.h.
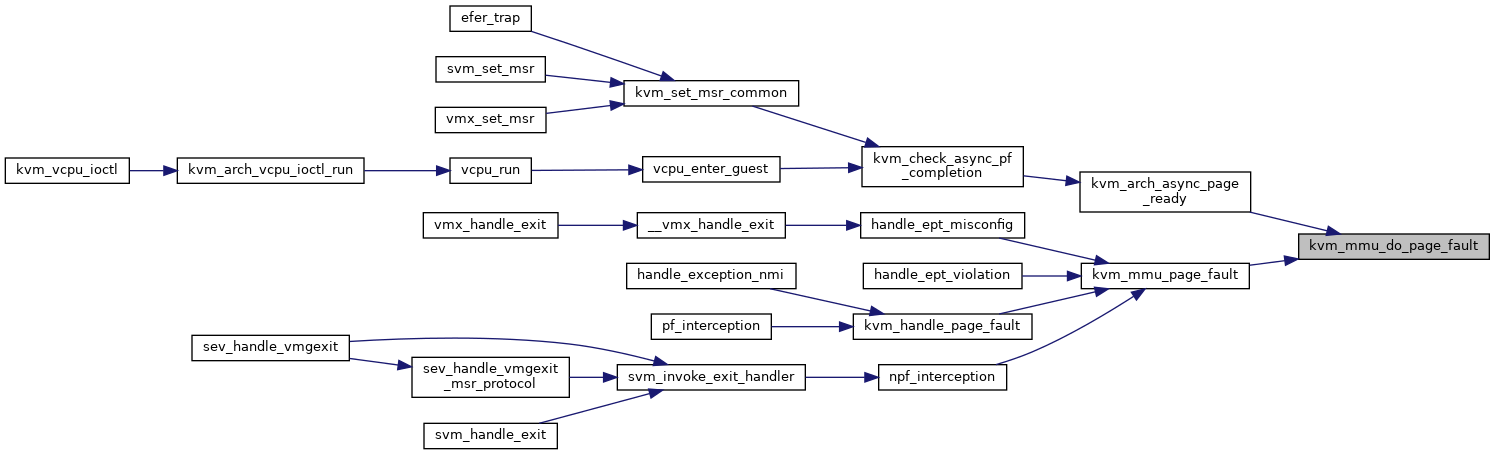
◆ kvm_mmu_get_dummy_root()
|
inlinestatic |

◆ kvm_mmu_gfn_allow_lpage()
| void kvm_mmu_gfn_allow_lpage | ( | const struct kvm_memory_slot * | slot, |
| gfn_t | gfn | ||
| ) |

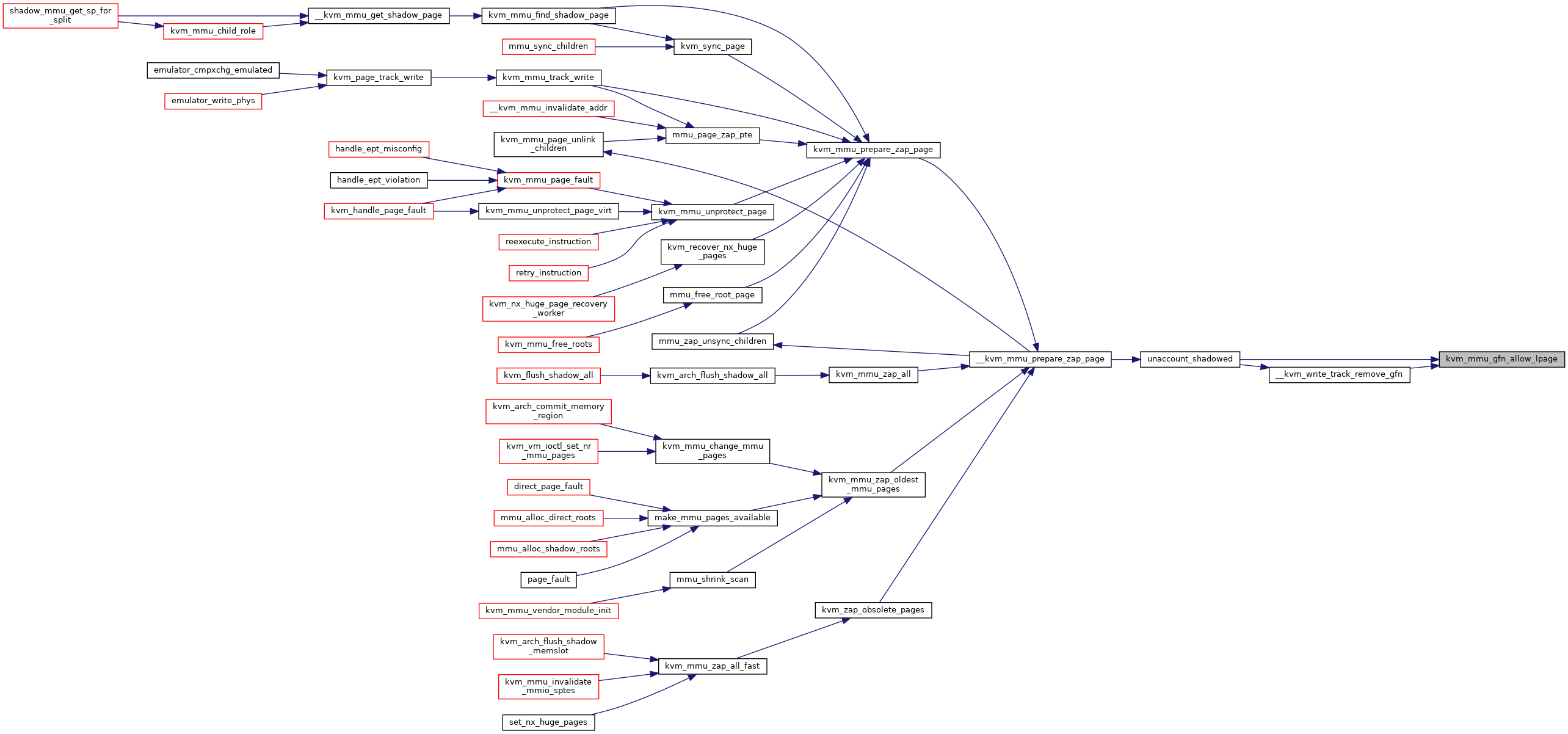
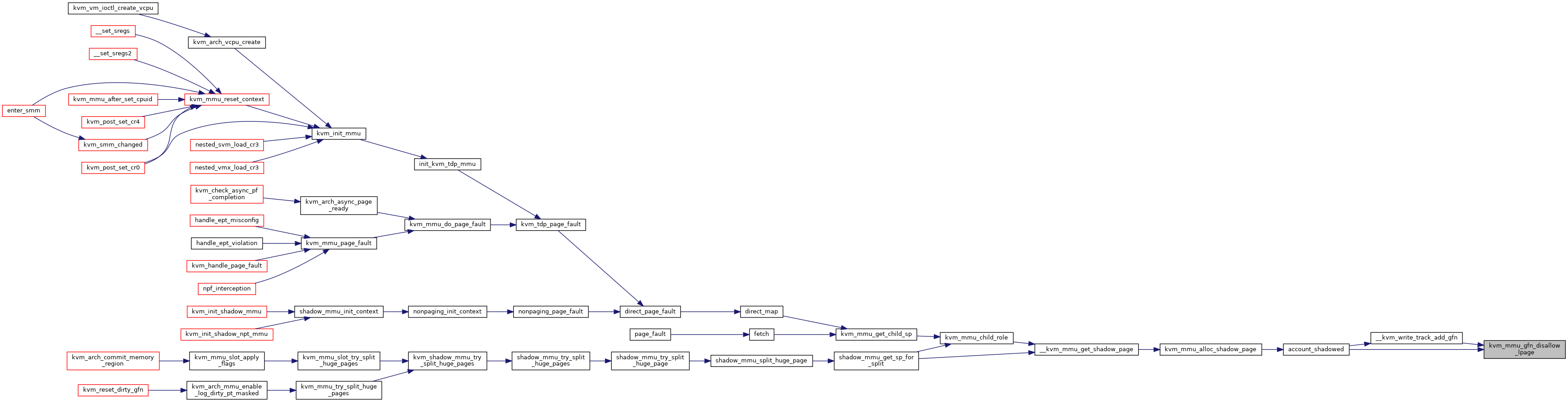
◆ kvm_mmu_gfn_disallow_lpage()
| void kvm_mmu_gfn_disallow_lpage | ( | const struct kvm_memory_slot * | slot, |
| gfn_t | gfn | ||
| ) |

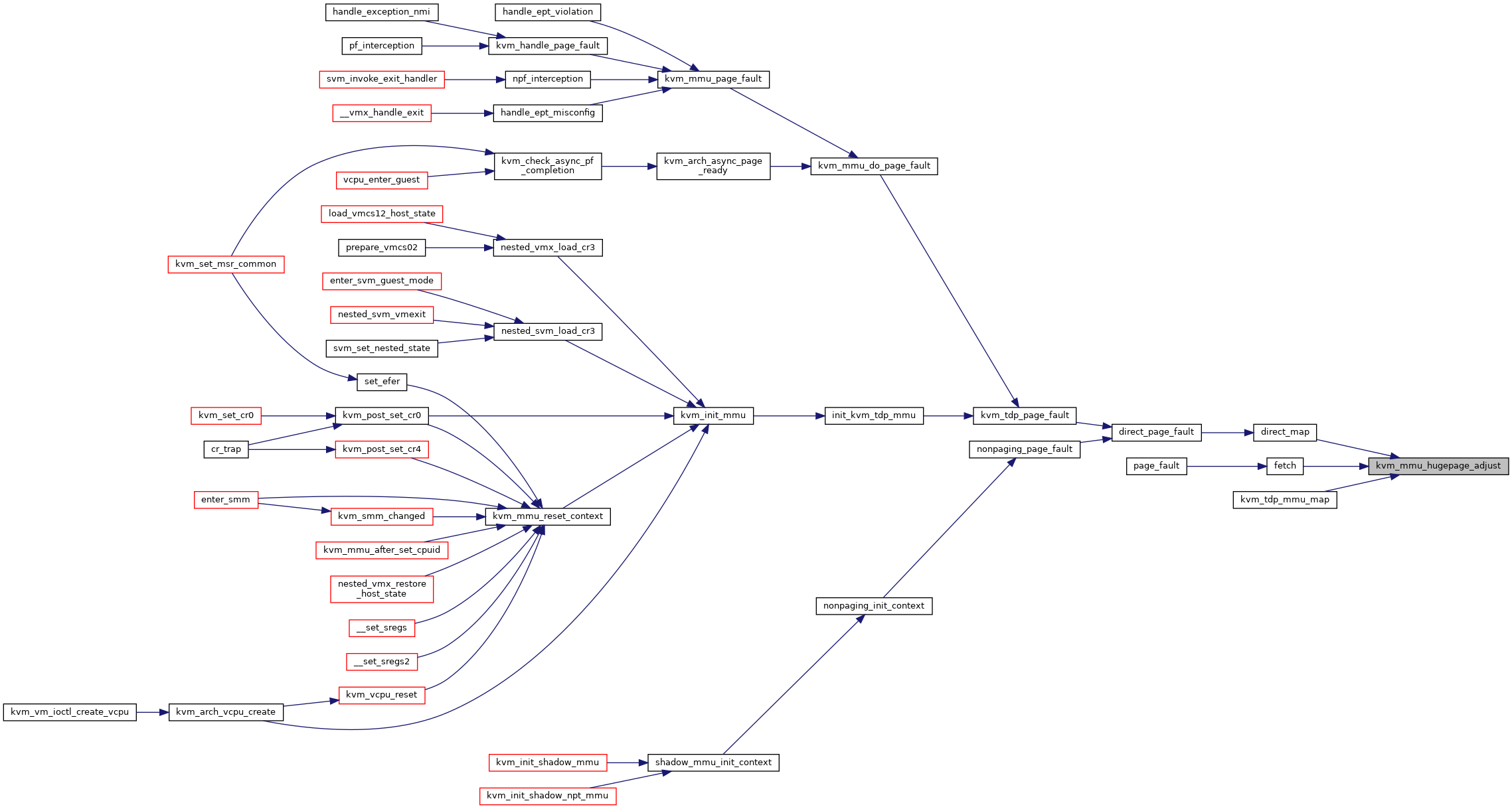
◆ kvm_mmu_hugepage_adjust()
| void kvm_mmu_hugepage_adjust | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_page_fault * | fault | ||
| ) |
Definition at line 3180 of file mmu.c.

◆ kvm_mmu_is_dummy_root()
|
inlinestatic |
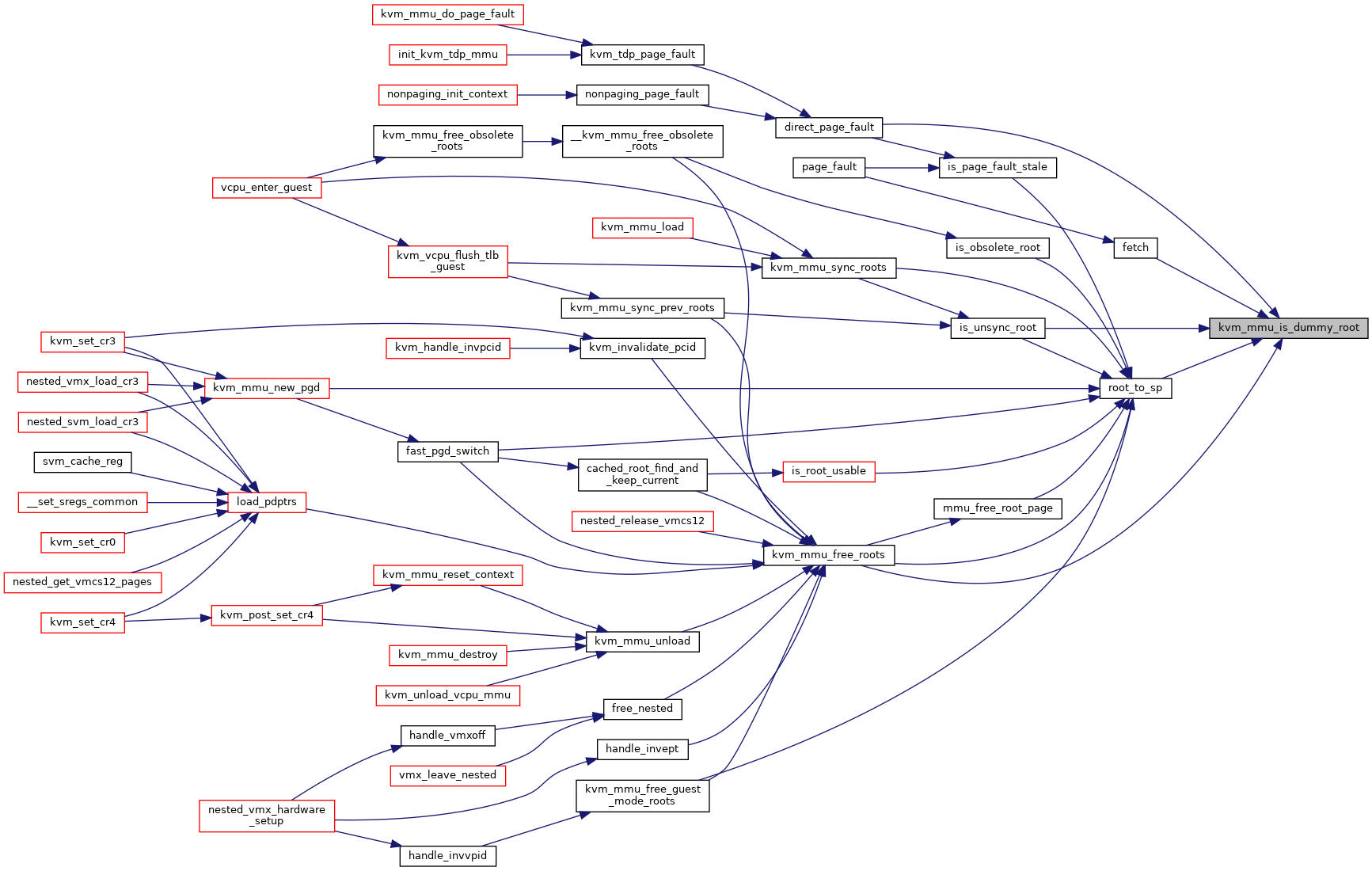
◆ kvm_mmu_max_mapping_level()
| int kvm_mmu_max_mapping_level | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| int | max_level | ||
| ) |


◆ kvm_mmu_page_ad_need_write_protect()
|
inlinestatic |
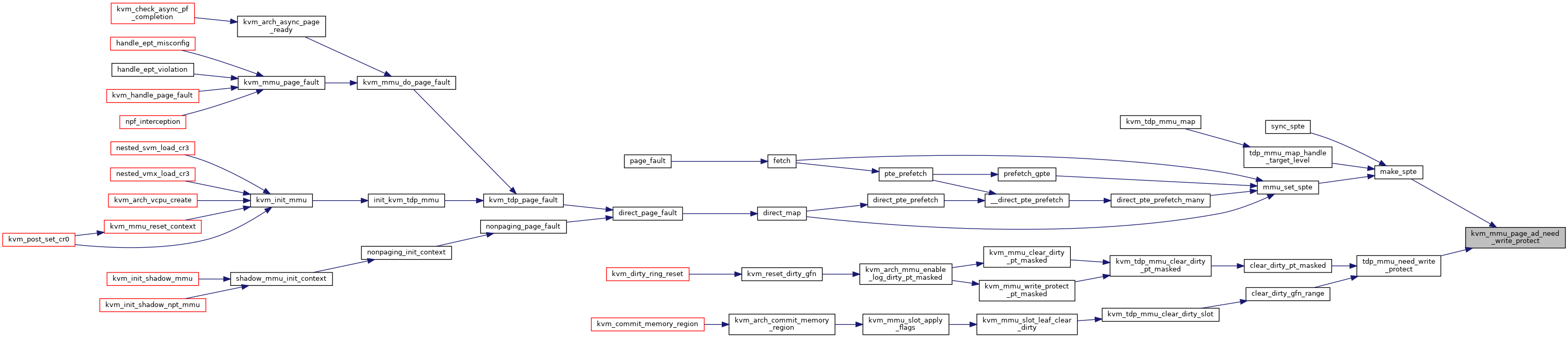
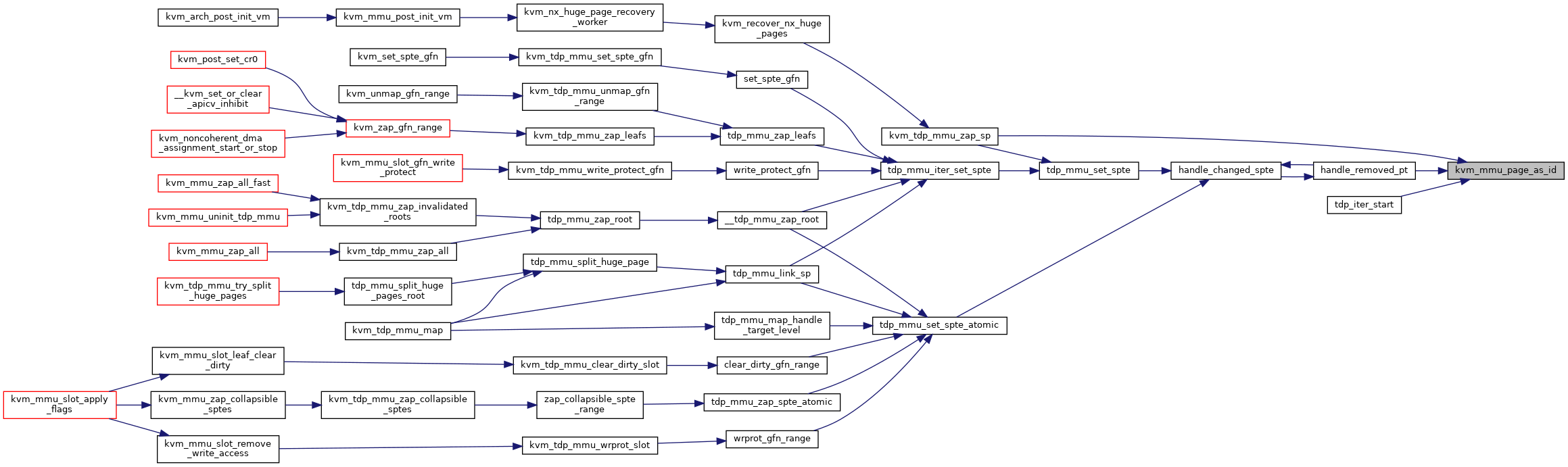
◆ kvm_mmu_page_as_id()
|
inlinestatic |
Definition at line 143 of file mmu_internal.h.

◆ kvm_mmu_role_as_id()
|
inlinestatic |
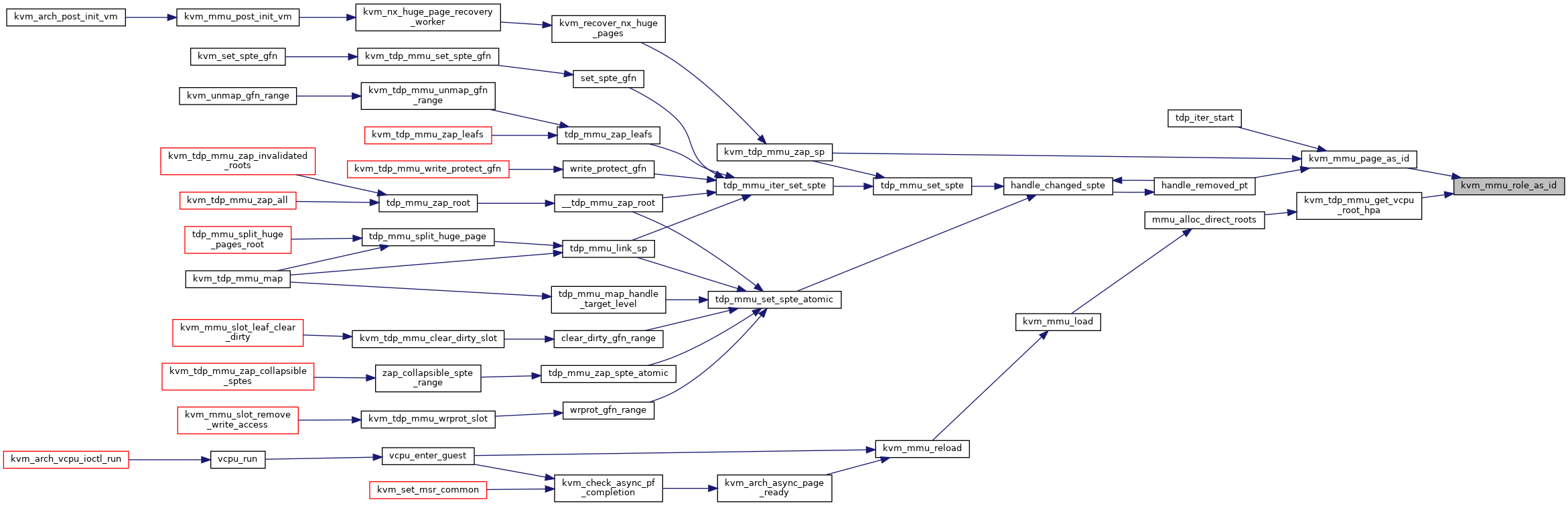
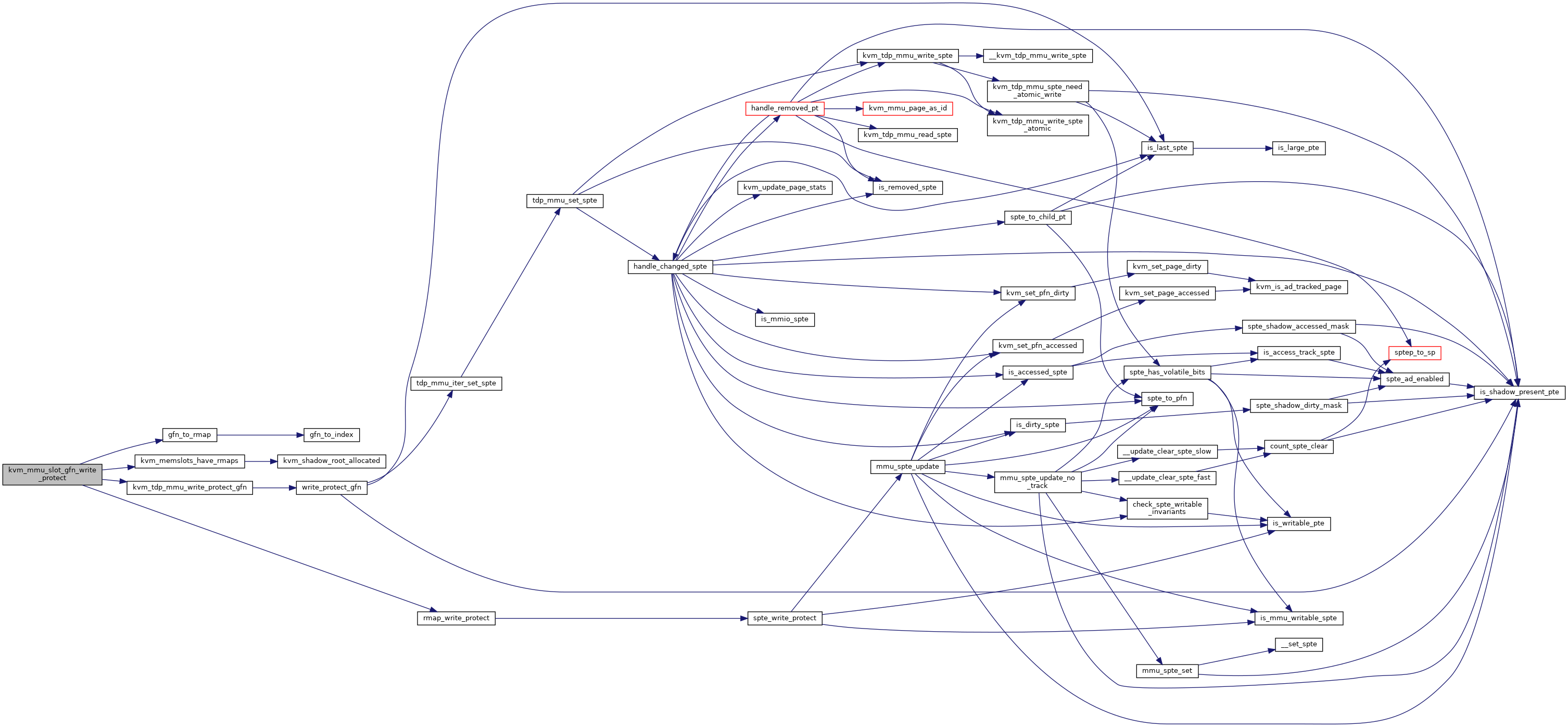
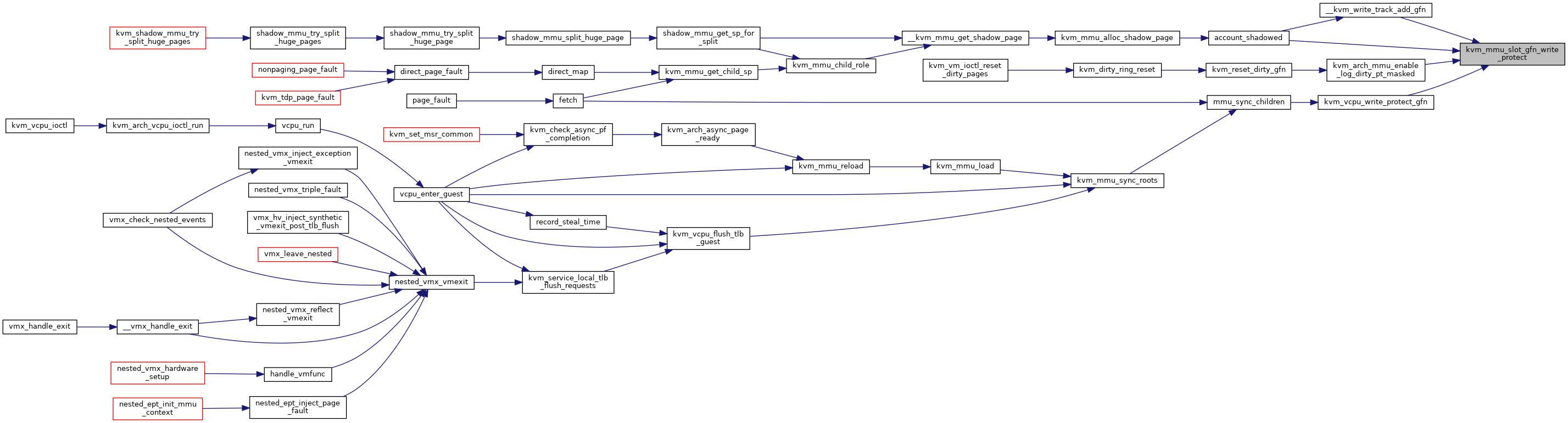
◆ kvm_mmu_slot_gfn_write_protect()
| bool kvm_mmu_slot_gfn_write_protect | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot, | ||
| u64 | gfn, | ||
| int | min_level | ||
| ) |
Definition at line 1414 of file mmu.c.
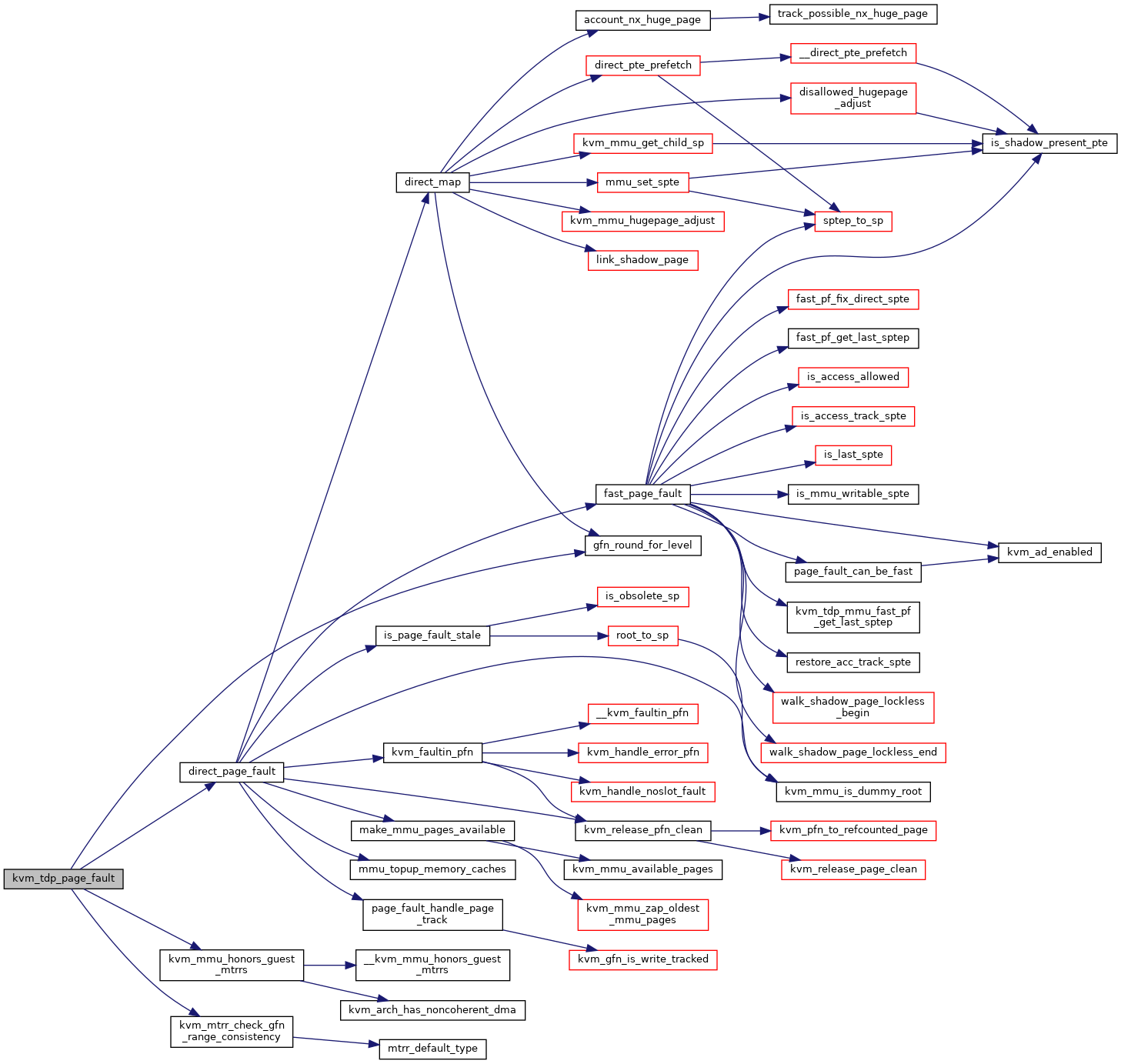
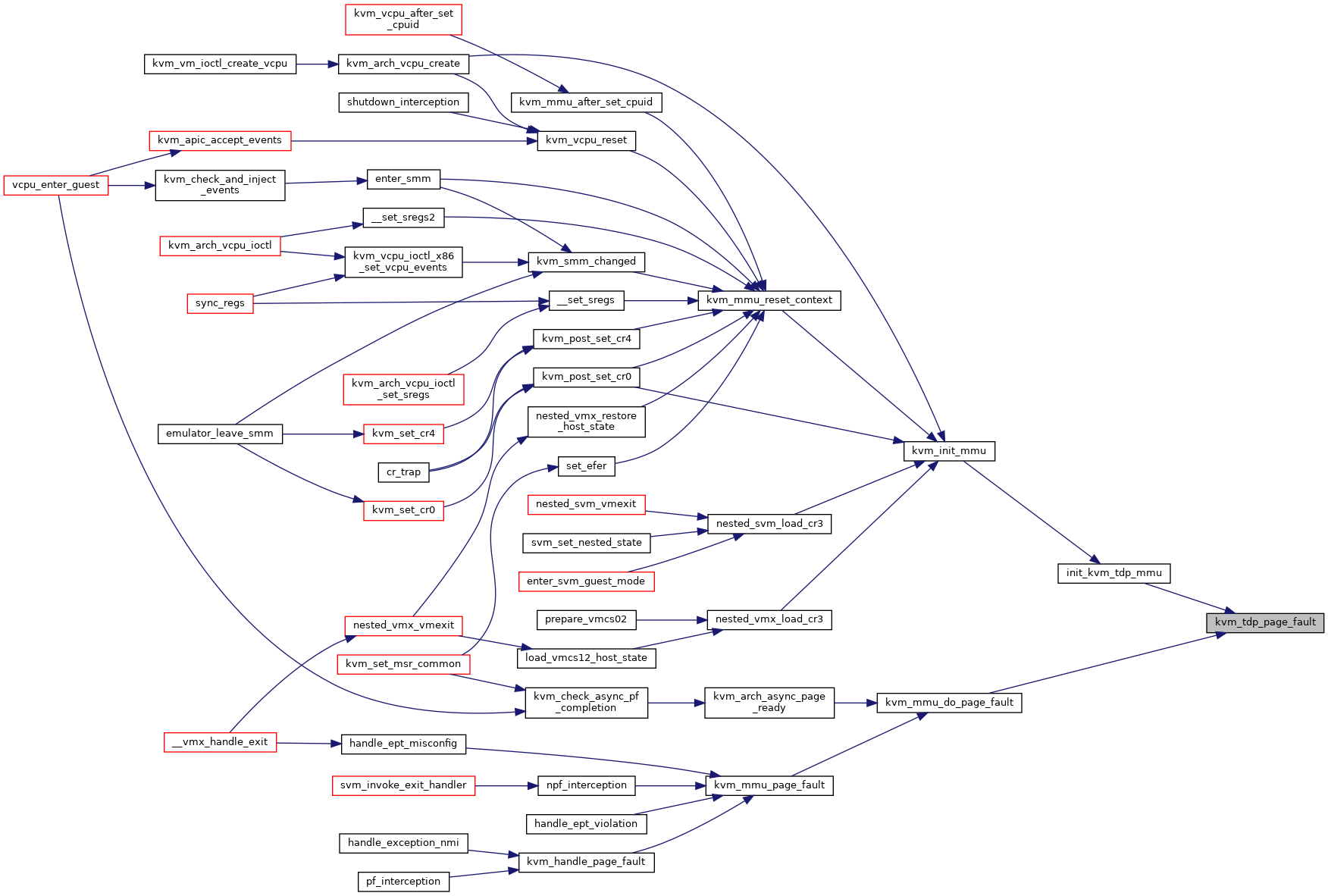
◆ kvm_tdp_page_fault()
| int kvm_tdp_page_fault | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_page_fault * | fault | ||
| ) |
Definition at line 4623 of file mmu.c.
◆ mmu_memory_cache_alloc()
| void* mmu_memory_cache_alloc | ( | struct kvm_mmu_memory_cache * | mc | ) |
◆ mmu_try_to_unsync_pages()
| int mmu_try_to_unsync_pages | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| bool | can_unsync, | ||
| bool | prefetch | ||
| ) |
Definition at line 2805 of file mmu.c.

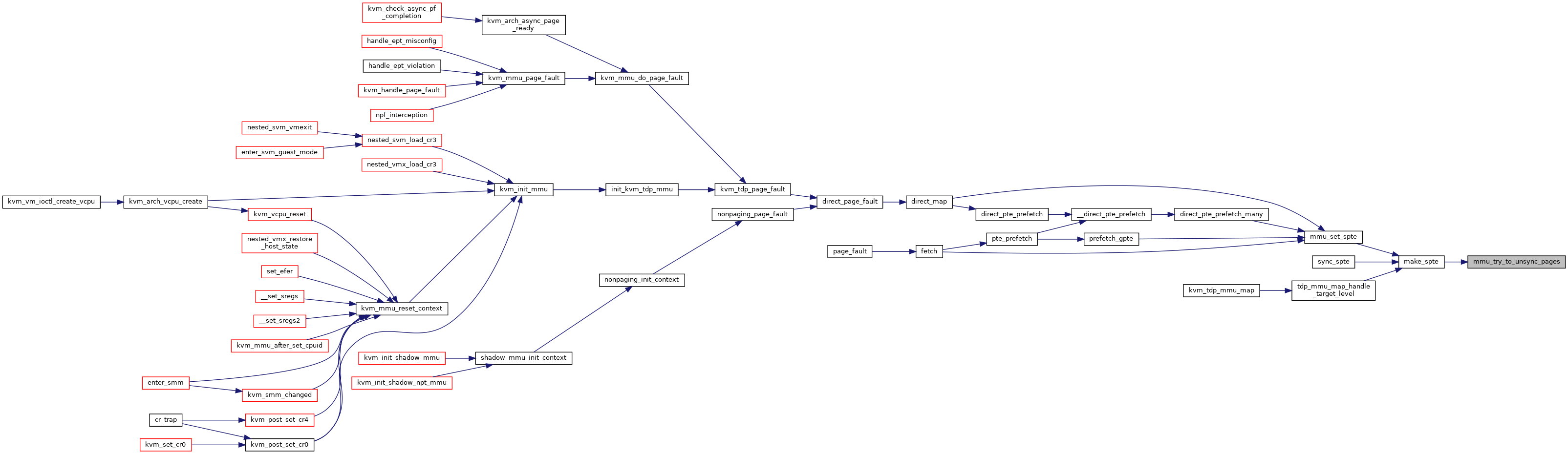
◆ pte_list_count()
| unsigned int pte_list_count | ( | struct kvm_rmap_head * | rmap_head | ) |
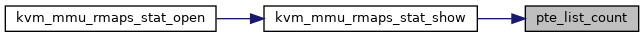
◆ track_possible_nx_huge_page()
| void track_possible_nx_huge_page | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | sp | ||
| ) |
Definition at line 848 of file mmu.c.
◆ untrack_possible_nx_huge_page()
| void untrack_possible_nx_huge_page | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | sp | ||
| ) |