#include "mmu.h"#include "mmu_internal.h"#include "mmutrace.h"#include "tdp_iter.h"#include "tdp_mmu.h"#include "spte.h"#include <asm/cmpxchg.h>#include <trace/events/kvm.h>
Go to the source code of this file.
Macros | |
| #define | pr_fmt(fmt) KBUILD_MODNAME ": " fmt |
| #define | __for_each_tdp_mmu_root_yield_safe(_kvm, _root, _as_id, _only_valid) |
| #define | for_each_valid_tdp_mmu_root_yield_safe(_kvm, _root, _as_id) __for_each_tdp_mmu_root_yield_safe(_kvm, _root, _as_id, true) |
| #define | for_each_tdp_mmu_root_yield_safe(_kvm, _root) |
| #define | for_each_tdp_mmu_root(_kvm, _root, _as_id) |
| #define | tdp_root_for_each_pte(_iter, _root, _start, _end) for_each_tdp_pte(_iter, _root, _start, _end) |
| #define | tdp_root_for_each_leaf_pte(_iter, _root, _start, _end) |
| #define | tdp_mmu_for_each_pte(_iter, _mmu, _start, _end) for_each_tdp_pte(_iter, root_to_sp(_mmu->root.hpa), _start, _end) |
Typedefs | |
| typedef bool(* | tdp_handler_t) (struct kvm *kvm, struct tdp_iter *iter, struct kvm_gfn_range *range) |
Functions | |
| void | kvm_mmu_init_tdp_mmu (struct kvm *kvm) |
| static __always_inline bool | kvm_lockdep_assert_mmu_lock_held (struct kvm *kvm, bool shared) |
| void | kvm_mmu_uninit_tdp_mmu (struct kvm *kvm) |
| static void | tdp_mmu_free_sp (struct kvm_mmu_page *sp) |
| static void | tdp_mmu_free_sp_rcu_callback (struct rcu_head *head) |
| void | kvm_tdp_mmu_put_root (struct kvm *kvm, struct kvm_mmu_page *root) |
| static struct kvm_mmu_page * | tdp_mmu_next_root (struct kvm *kvm, struct kvm_mmu_page *prev_root, bool only_valid) |
| static struct kvm_mmu_page * | tdp_mmu_alloc_sp (struct kvm_vcpu *vcpu) |
| static void | tdp_mmu_init_sp (struct kvm_mmu_page *sp, tdp_ptep_t sptep, gfn_t gfn, union kvm_mmu_page_role role) |
| static void | tdp_mmu_init_child_sp (struct kvm_mmu_page *child_sp, struct tdp_iter *iter) |
| hpa_t | kvm_tdp_mmu_get_vcpu_root_hpa (struct kvm_vcpu *vcpu) |
| static void | handle_changed_spte (struct kvm *kvm, int as_id, gfn_t gfn, u64 old_spte, u64 new_spte, int level, bool shared) |
| static void | tdp_account_mmu_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | tdp_unaccount_mmu_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | tdp_mmu_unlink_sp (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | handle_removed_pt (struct kvm *kvm, tdp_ptep_t pt, bool shared) |
| static int | tdp_mmu_set_spte_atomic (struct kvm *kvm, struct tdp_iter *iter, u64 new_spte) |
| static int | tdp_mmu_zap_spte_atomic (struct kvm *kvm, struct tdp_iter *iter) |
| static u64 | tdp_mmu_set_spte (struct kvm *kvm, int as_id, tdp_ptep_t sptep, u64 old_spte, u64 new_spte, gfn_t gfn, int level) |
| static void | tdp_mmu_iter_set_spte (struct kvm *kvm, struct tdp_iter *iter, u64 new_spte) |
| static bool __must_check | tdp_mmu_iter_cond_resched (struct kvm *kvm, struct tdp_iter *iter, bool flush, bool shared) |
| static gfn_t | tdp_mmu_max_gfn_exclusive (void) |
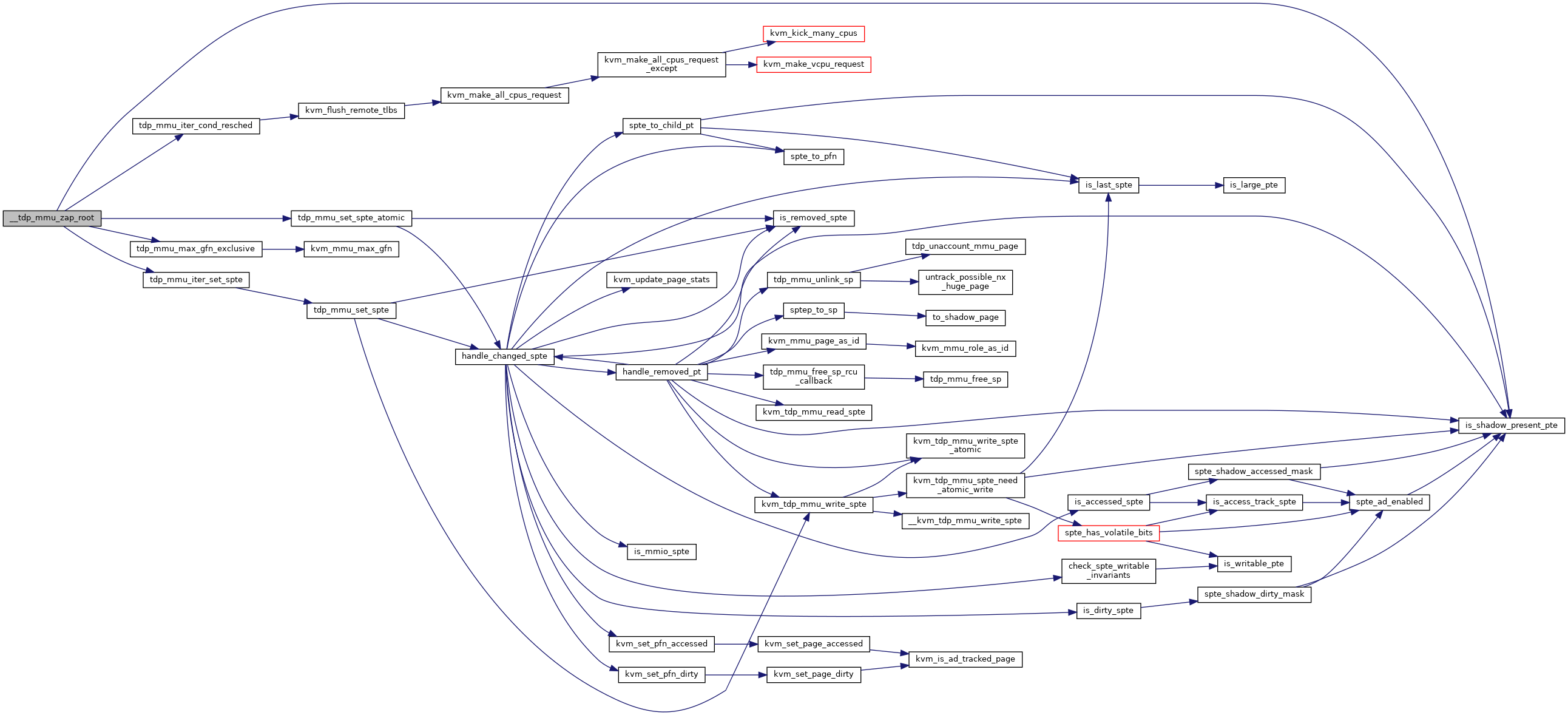
| static void | __tdp_mmu_zap_root (struct kvm *kvm, struct kvm_mmu_page *root, bool shared, int zap_level) |
| static void | tdp_mmu_zap_root (struct kvm *kvm, struct kvm_mmu_page *root, bool shared) |
| bool | kvm_tdp_mmu_zap_sp (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static bool | tdp_mmu_zap_leafs (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t start, gfn_t end, bool can_yield, bool flush) |
| bool | kvm_tdp_mmu_zap_leafs (struct kvm *kvm, gfn_t start, gfn_t end, bool flush) |
| void | kvm_tdp_mmu_zap_all (struct kvm *kvm) |
| void | kvm_tdp_mmu_zap_invalidated_roots (struct kvm *kvm) |
| void | kvm_tdp_mmu_invalidate_all_roots (struct kvm *kvm) |
| static int | tdp_mmu_map_handle_target_level (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, struct tdp_iter *iter) |
| static int | tdp_mmu_link_sp (struct kvm *kvm, struct tdp_iter *iter, struct kvm_mmu_page *sp, bool shared) |
| static int | tdp_mmu_split_huge_page (struct kvm *kvm, struct tdp_iter *iter, struct kvm_mmu_page *sp, bool shared) |
| int | kvm_tdp_mmu_map (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| bool | kvm_tdp_mmu_unmap_gfn_range (struct kvm *kvm, struct kvm_gfn_range *range, bool flush) |
| static __always_inline bool | kvm_tdp_mmu_handle_gfn (struct kvm *kvm, struct kvm_gfn_range *range, tdp_handler_t handler) |
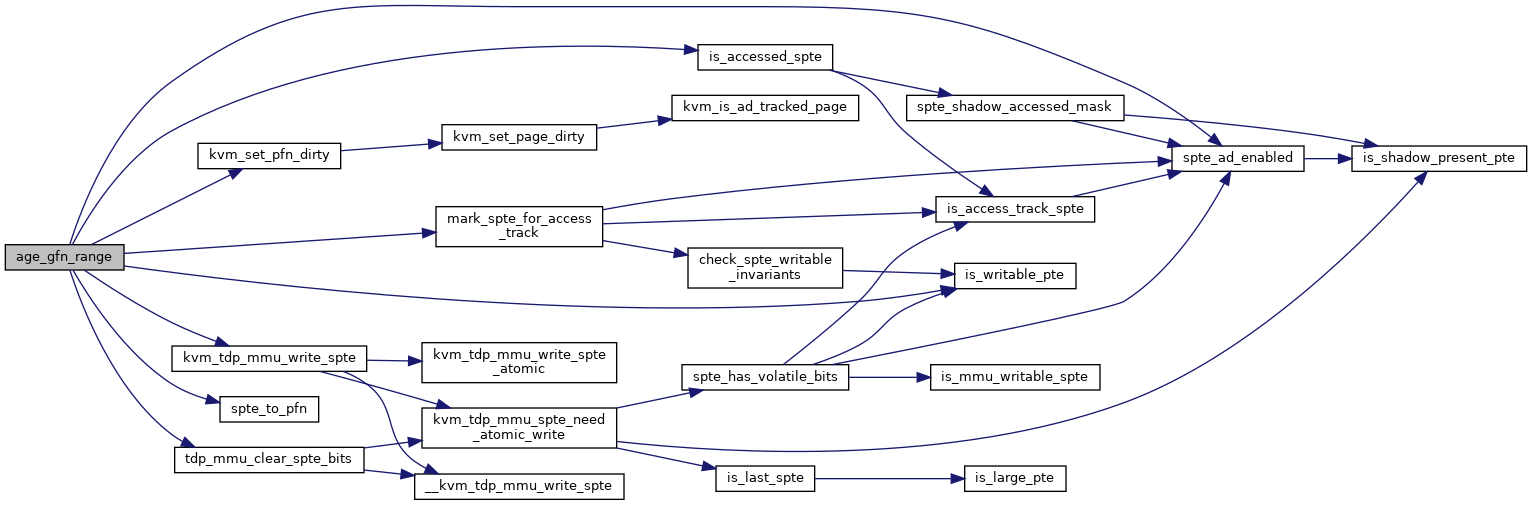
| static bool | age_gfn_range (struct kvm *kvm, struct tdp_iter *iter, struct kvm_gfn_range *range) |
| bool | kvm_tdp_mmu_age_gfn_range (struct kvm *kvm, struct kvm_gfn_range *range) |
| static bool | test_age_gfn (struct kvm *kvm, struct tdp_iter *iter, struct kvm_gfn_range *range) |
| bool | kvm_tdp_mmu_test_age_gfn (struct kvm *kvm, struct kvm_gfn_range *range) |
| static bool | set_spte_gfn (struct kvm *kvm, struct tdp_iter *iter, struct kvm_gfn_range *range) |
| bool | kvm_tdp_mmu_set_spte_gfn (struct kvm *kvm, struct kvm_gfn_range *range) |
| static bool | wrprot_gfn_range (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t start, gfn_t end, int min_level) |
| bool | kvm_tdp_mmu_wrprot_slot (struct kvm *kvm, const struct kvm_memory_slot *slot, int min_level) |
| static struct kvm_mmu_page * | __tdp_mmu_alloc_sp_for_split (gfp_t gfp) |
| static struct kvm_mmu_page * | tdp_mmu_alloc_sp_for_split (struct kvm *kvm, struct tdp_iter *iter, bool shared) |
| static int | tdp_mmu_split_huge_pages_root (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t start, gfn_t end, int target_level, bool shared) |
| void | kvm_tdp_mmu_try_split_huge_pages (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t start, gfn_t end, int target_level, bool shared) |
| static bool | tdp_mmu_need_write_protect (struct kvm_mmu_page *sp) |
| static bool | clear_dirty_gfn_range (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t start, gfn_t end) |
| bool | kvm_tdp_mmu_clear_dirty_slot (struct kvm *kvm, const struct kvm_memory_slot *slot) |
| static void | clear_dirty_pt_masked (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t gfn, unsigned long mask, bool wrprot) |
| void | kvm_tdp_mmu_clear_dirty_pt_masked (struct kvm *kvm, struct kvm_memory_slot *slot, gfn_t gfn, unsigned long mask, bool wrprot) |
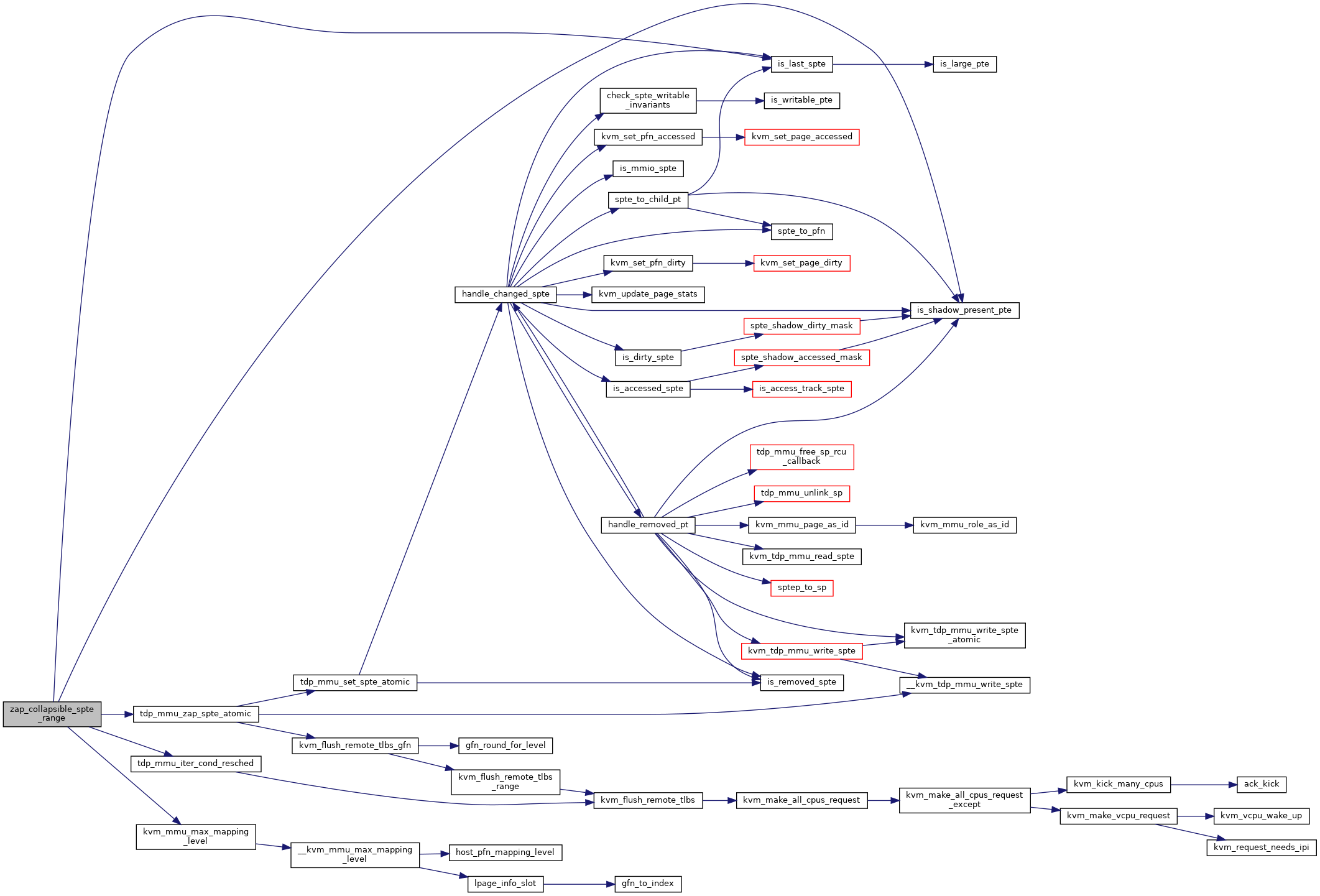
| static void | zap_collapsible_spte_range (struct kvm *kvm, struct kvm_mmu_page *root, const struct kvm_memory_slot *slot) |
| void | kvm_tdp_mmu_zap_collapsible_sptes (struct kvm *kvm, const struct kvm_memory_slot *slot) |
| static bool | write_protect_gfn (struct kvm *kvm, struct kvm_mmu_page *root, gfn_t gfn, int min_level) |
| bool | kvm_tdp_mmu_write_protect_gfn (struct kvm *kvm, struct kvm_memory_slot *slot, gfn_t gfn, int min_level) |
| int | kvm_tdp_mmu_get_walk (struct kvm_vcpu *vcpu, u64 addr, u64 *sptes, int *root_level) |
| u64 * | kvm_tdp_mmu_fast_pf_get_last_sptep (struct kvm_vcpu *vcpu, u64 addr, u64 *spte) |
Macro Definition Documentation
◆ __for_each_tdp_mmu_root_yield_safe
| #define __for_each_tdp_mmu_root_yield_safe | ( | _kvm, | |
| _root, | |||
| _as_id, | |||
| _only_valid | |||
| ) |
◆ for_each_tdp_mmu_root
| #define for_each_tdp_mmu_root | ( | _kvm, | |
| _root, | |||
| _as_id | |||
| ) |
◆ for_each_tdp_mmu_root_yield_safe
| #define for_each_tdp_mmu_root_yield_safe | ( | _kvm, | |
| _root | |||
| ) |
◆ for_each_valid_tdp_mmu_root_yield_safe
| #define for_each_valid_tdp_mmu_root_yield_safe | ( | _kvm, | |
| _root, | |||
| _as_id | |||
| ) | __for_each_tdp_mmu_root_yield_safe(_kvm, _root, _as_id, true) |
◆ pr_fmt
◆ tdp_mmu_for_each_pte
| #define tdp_mmu_for_each_pte | ( | _iter, | |
| _mmu, | |||
| _start, | |||
| _end | |||
| ) | for_each_tdp_pte(_iter, root_to_sp(_mmu->root.hpa), _start, _end) |
◆ tdp_root_for_each_leaf_pte
| #define tdp_root_for_each_leaf_pte | ( | _iter, | |
| _root, | |||
| _start, | |||
| _end | |||
| ) |
◆ tdp_root_for_each_pte
| #define tdp_root_for_each_pte | ( | _iter, | |
| _root, | |||
| _start, | |||
| _end | |||
| ) | for_each_tdp_pte(_iter, _root, _start, _end) |
Typedef Documentation
◆ tdp_handler_t
| typedef bool(* tdp_handler_t) (struct kvm *kvm, struct tdp_iter *iter, struct kvm_gfn_range *range) |
Function Documentation
◆ __tdp_mmu_alloc_sp_for_split()
|
static |
Definition at line 1315 of file tdp_mmu.c.

◆ __tdp_mmu_zap_root()
|
static |
Definition at line 690 of file tdp_mmu.c.

◆ age_gfn_range()
|
static |
Definition at line 1161 of file tdp_mmu.c.

◆ clear_dirty_gfn_range()
|
static |
Definition at line 1518 of file tdp_mmu.c.

◆ clear_dirty_pt_masked()
|
static |
Definition at line 1581 of file tdp_mmu.c.

◆ handle_changed_spte()
|
static |
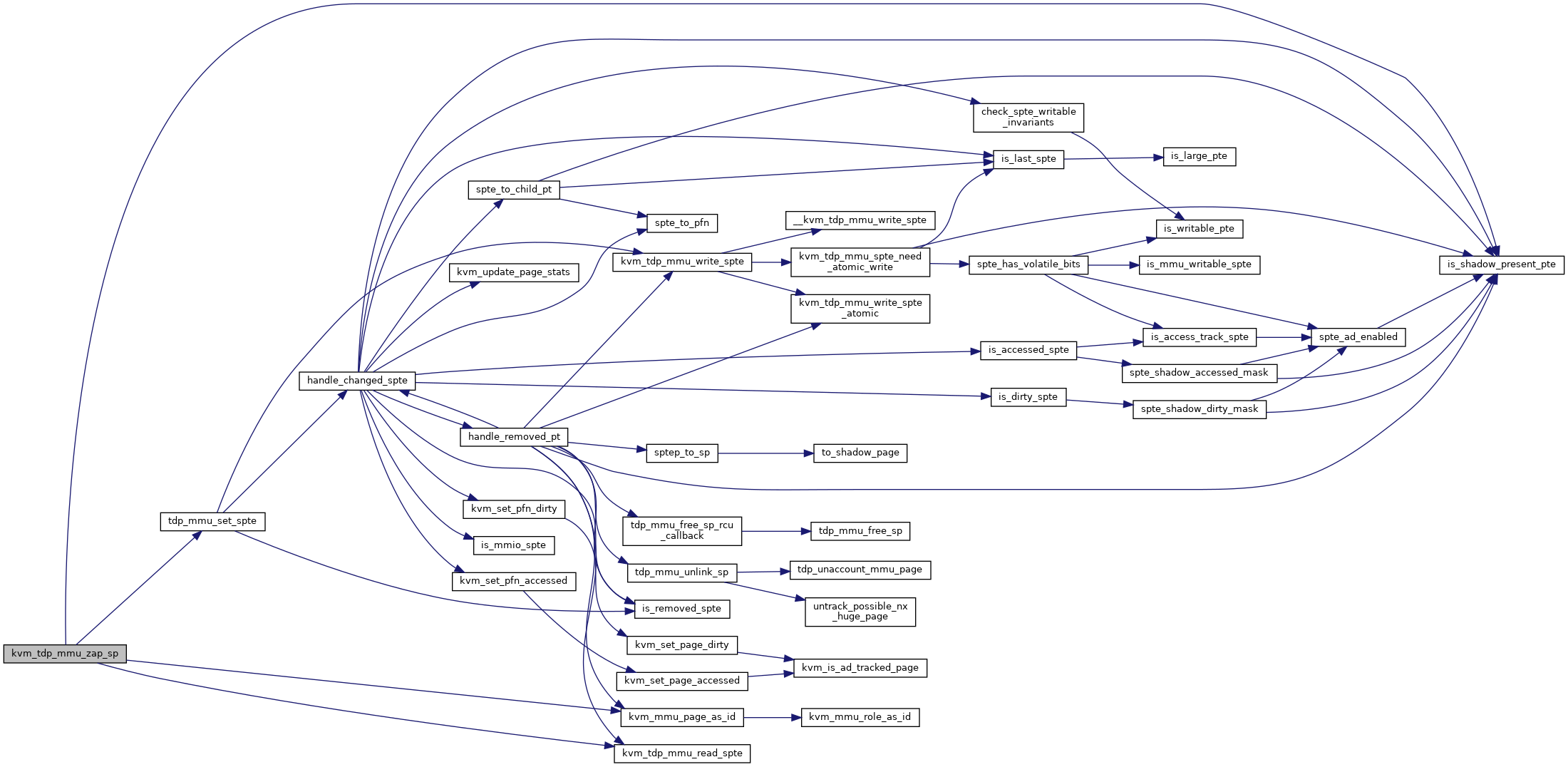
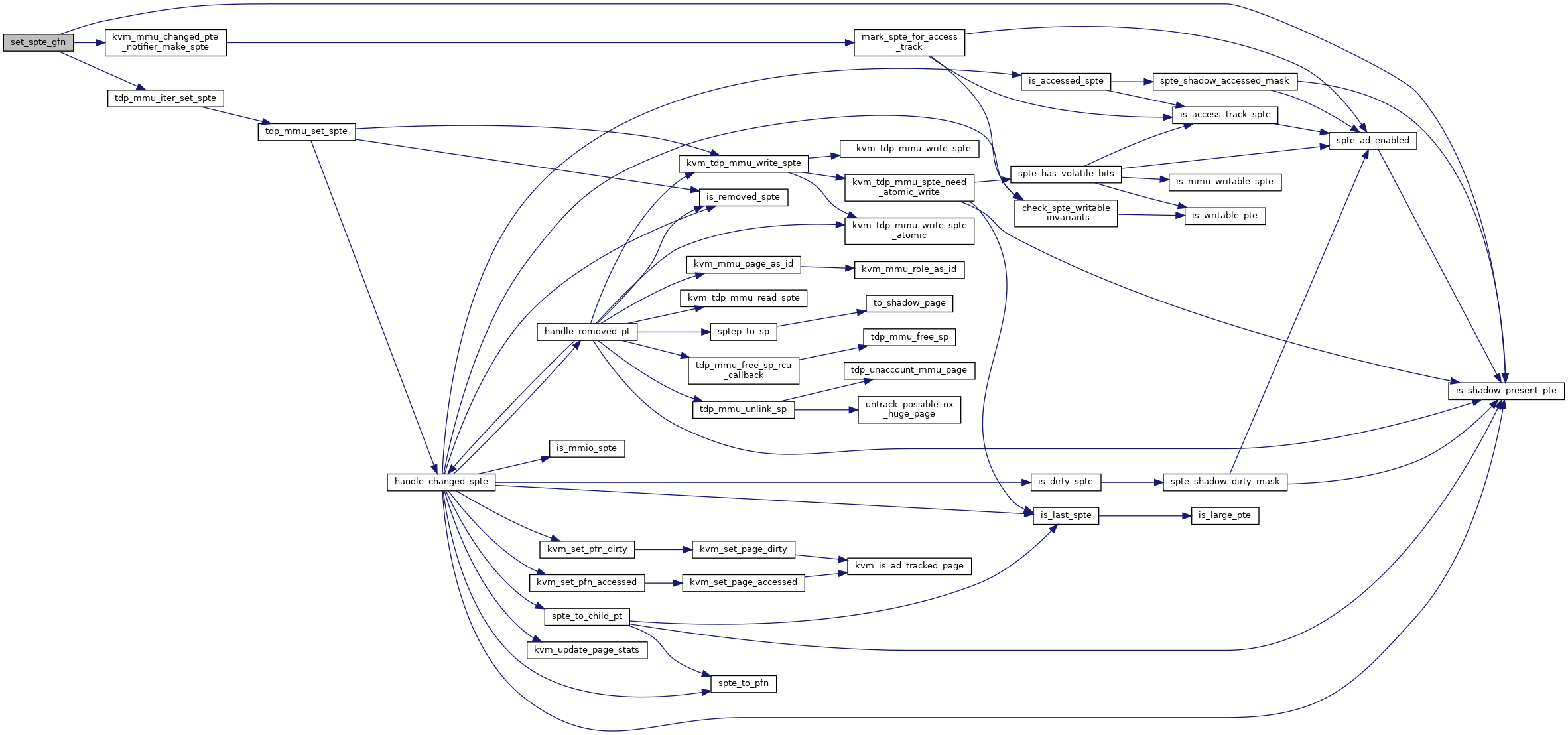
handle_changed_spte - handle bookkeeping associated with an SPTE change @kvm: kvm instance @as_id: the address space of the paging structure the SPTE was a part of @gfn: the base GFN that was mapped by the SPTE @old_spte: The value of the SPTE before the change @new_spte: The value of the SPTE after the change @level: the level of the PT the SPTE is part of in the paging structure @shared: This operation may not be running under the exclusive use of the MMU lock and the operation must synchronize with other threads that might be modifying SPTEs.
Handle bookkeeping that might result from the modification of a SPTE. Note, dirty logging updates are handled in common code, not here (see make_spte() and fast_pf_fix_direct_spte()).
Definition at line 408 of file tdp_mmu.c.
◆ handle_removed_pt()
|
static |
handle_removed_pt() - handle a page table removed from the TDP structure
@kvm: kvm instance @pt: the page removed from the paging structure @shared: This operation may not be running under the exclusive use of the MMU lock and the operation must synchronize with other threads that might be modifying SPTEs.
Given a page table that has been removed from the TDP paging structure, iterates through the page table to clear SPTEs and free child page tables.
Note that pt is passed in as a tdp_ptep_t, but it does not need RCU protection. Since this thread removed it from the paging structure, this thread will be responsible for ensuring the page is freed. Hence the early rcu_dereferences in the function.
Definition at line 309 of file tdp_mmu.c.
◆ kvm_lockdep_assert_mmu_lock_held()
|
static |

◆ kvm_mmu_init_tdp_mmu()
| void kvm_mmu_init_tdp_mmu | ( | struct kvm * | kvm | ) |
◆ kvm_mmu_uninit_tdp_mmu()
| void kvm_mmu_uninit_tdp_mmu | ( | struct kvm * | kvm | ) |
Definition at line 33 of file tdp_mmu.c.
◆ kvm_tdp_mmu_age_gfn_range()
| bool kvm_tdp_mmu_age_gfn_range | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1195 of file tdp_mmu.c.

◆ kvm_tdp_mmu_clear_dirty_pt_masked()
| void kvm_tdp_mmu_clear_dirty_pt_masked | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| unsigned long | mask, | ||
| bool | wrprot | ||
| ) |
Definition at line 1629 of file tdp_mmu.c.

◆ kvm_tdp_mmu_clear_dirty_slot()
| bool kvm_tdp_mmu_clear_dirty_slot | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot | ||
| ) |
Definition at line 1560 of file tdp_mmu.c.

◆ kvm_tdp_mmu_fast_pf_get_last_sptep()
| u64* kvm_tdp_mmu_fast_pf_get_last_sptep | ( | struct kvm_vcpu * | vcpu, |
| u64 | addr, | ||
| u64 * | spte | ||
| ) |
Definition at line 1795 of file tdp_mmu.c.
◆ kvm_tdp_mmu_get_vcpu_root_hpa()
| hpa_t kvm_tdp_mmu_get_vcpu_root_hpa | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 219 of file tdp_mmu.c.

◆ kvm_tdp_mmu_get_walk()
| int kvm_tdp_mmu_get_walk | ( | struct kvm_vcpu * | vcpu, |
| u64 | addr, | ||
| u64 * | sptes, | ||
| int * | root_level | ||
| ) |

◆ kvm_tdp_mmu_handle_gfn()
|
static |
◆ kvm_tdp_mmu_invalidate_all_roots()
| void kvm_tdp_mmu_invalidate_all_roots | ( | struct kvm * | kvm | ) |
Definition at line 901 of file tdp_mmu.c.

◆ kvm_tdp_mmu_map()
| int kvm_tdp_mmu_map | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_page_fault * | fault | ||
| ) |
Definition at line 1032 of file tdp_mmu.c.
◆ kvm_tdp_mmu_put_root()
| void kvm_tdp_mmu_put_root | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | root | ||
| ) |

◆ kvm_tdp_mmu_set_spte_gfn()
| bool kvm_tdp_mmu_set_spte_gfn | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1247 of file tdp_mmu.c.

◆ kvm_tdp_mmu_test_age_gfn()
| bool kvm_tdp_mmu_test_age_gfn | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1206 of file tdp_mmu.c.


◆ kvm_tdp_mmu_try_split_huge_pages()
| void kvm_tdp_mmu_try_split_huge_pages | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| gfn_t | start, | ||
| gfn_t | end, | ||
| int | target_level, | ||
| bool | shared | ||
| ) |
Definition at line 1483 of file tdp_mmu.c.

◆ kvm_tdp_mmu_unmap_gfn_range()
| bool kvm_tdp_mmu_unmap_gfn_range | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range, | ||
| bool | flush | ||
| ) |
Definition at line 1114 of file tdp_mmu.c.

◆ kvm_tdp_mmu_write_protect_gfn()
| bool kvm_tdp_mmu_write_protect_gfn | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| int | min_level | ||
| ) |
Definition at line 1746 of file tdp_mmu.c.
◆ kvm_tdp_mmu_wrprot_slot()
| bool kvm_tdp_mmu_wrprot_slot | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| int | min_level | ||
| ) |
Definition at line 1300 of file tdp_mmu.c.

◆ kvm_tdp_mmu_zap_all()
| void kvm_tdp_mmu_zap_all | ( | struct kvm * | kvm | ) |
Definition at line 831 of file tdp_mmu.c.
◆ kvm_tdp_mmu_zap_collapsible_sptes()
| void kvm_tdp_mmu_zap_collapsible_sptes | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot | ||
| ) |
Definition at line 1695 of file tdp_mmu.c.

◆ kvm_tdp_mmu_zap_invalidated_roots()
| void kvm_tdp_mmu_zap_invalidated_roots | ( | struct kvm * | kvm | ) |

◆ kvm_tdp_mmu_zap_leafs()
| bool kvm_tdp_mmu_zap_leafs | ( | struct kvm * | kvm, |
| gfn_t | start, | ||
| gfn_t | end, | ||
| bool | flush | ||
| ) |
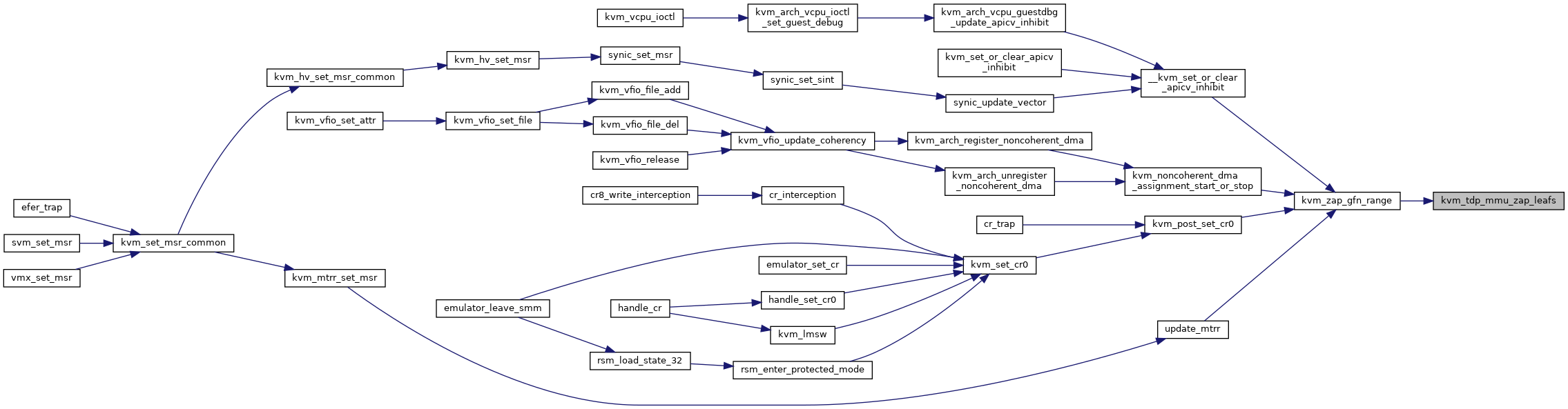
◆ kvm_tdp_mmu_zap_sp()
| bool kvm_tdp_mmu_zap_sp | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | sp | ||
| ) |
Definition at line 752 of file tdp_mmu.c.

◆ set_spte_gfn()
|
static |
Definition at line 1211 of file tdp_mmu.c.
◆ tdp_account_mmu_page()
|
static |

◆ tdp_mmu_alloc_sp()
|
static |

◆ tdp_mmu_alloc_sp_for_split()
|
static |
Definition at line 1334 of file tdp_mmu.c.

◆ tdp_mmu_free_sp()
|
static |
◆ tdp_mmu_free_sp_rcu_callback()
|
static |

◆ tdp_mmu_init_child_sp()
|
static |


◆ tdp_mmu_init_sp()
|
static |
Definition at line 190 of file tdp_mmu.c.

◆ tdp_mmu_iter_cond_resched()
|
inlinestatic |

◆ tdp_mmu_iter_set_spte()
|
inlinestatic |
◆ tdp_mmu_link_sp()
|
static |
Definition at line 1006 of file tdp_mmu.c.

◆ tdp_mmu_map_handle_target_level()
|
static |
Definition at line 943 of file tdp_mmu.c.

◆ tdp_mmu_max_gfn_exclusive()
|
inlinestatic |

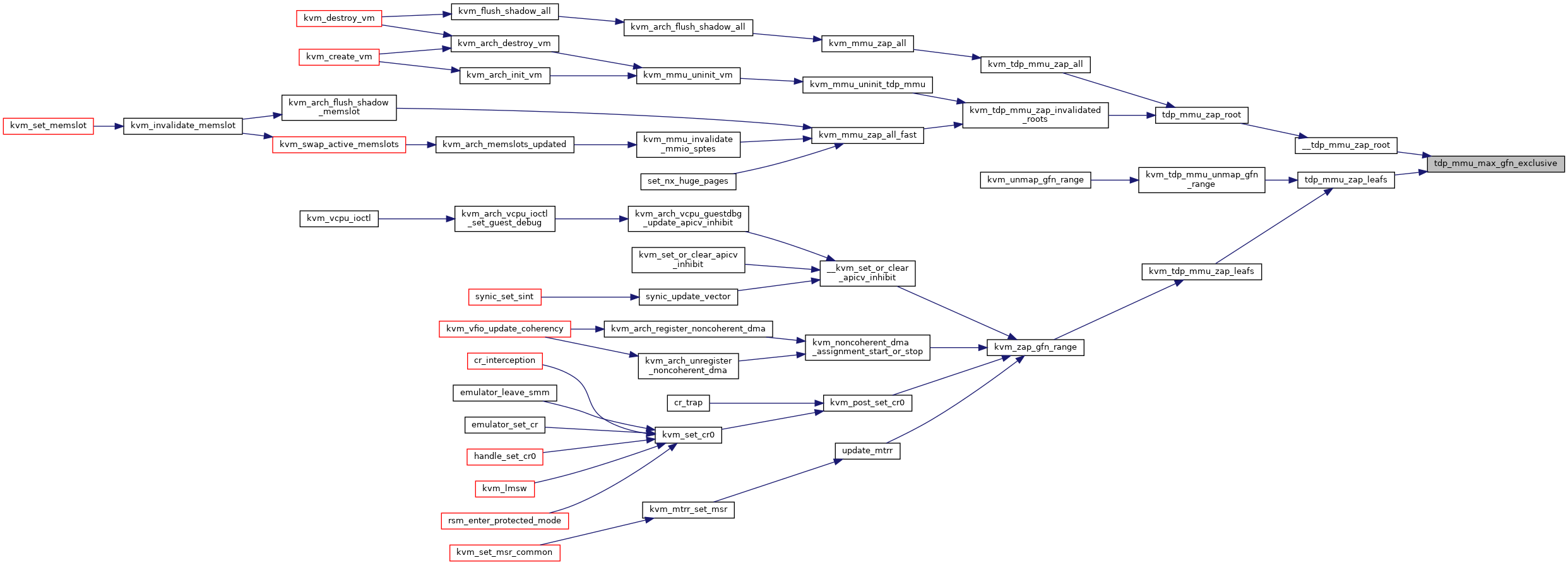
◆ tdp_mmu_need_write_protect()
|
static |
Definition at line 1501 of file tdp_mmu.c.
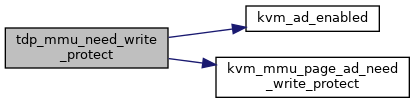

◆ tdp_mmu_next_root()
|
static |

◆ tdp_mmu_set_spte()
|
static |
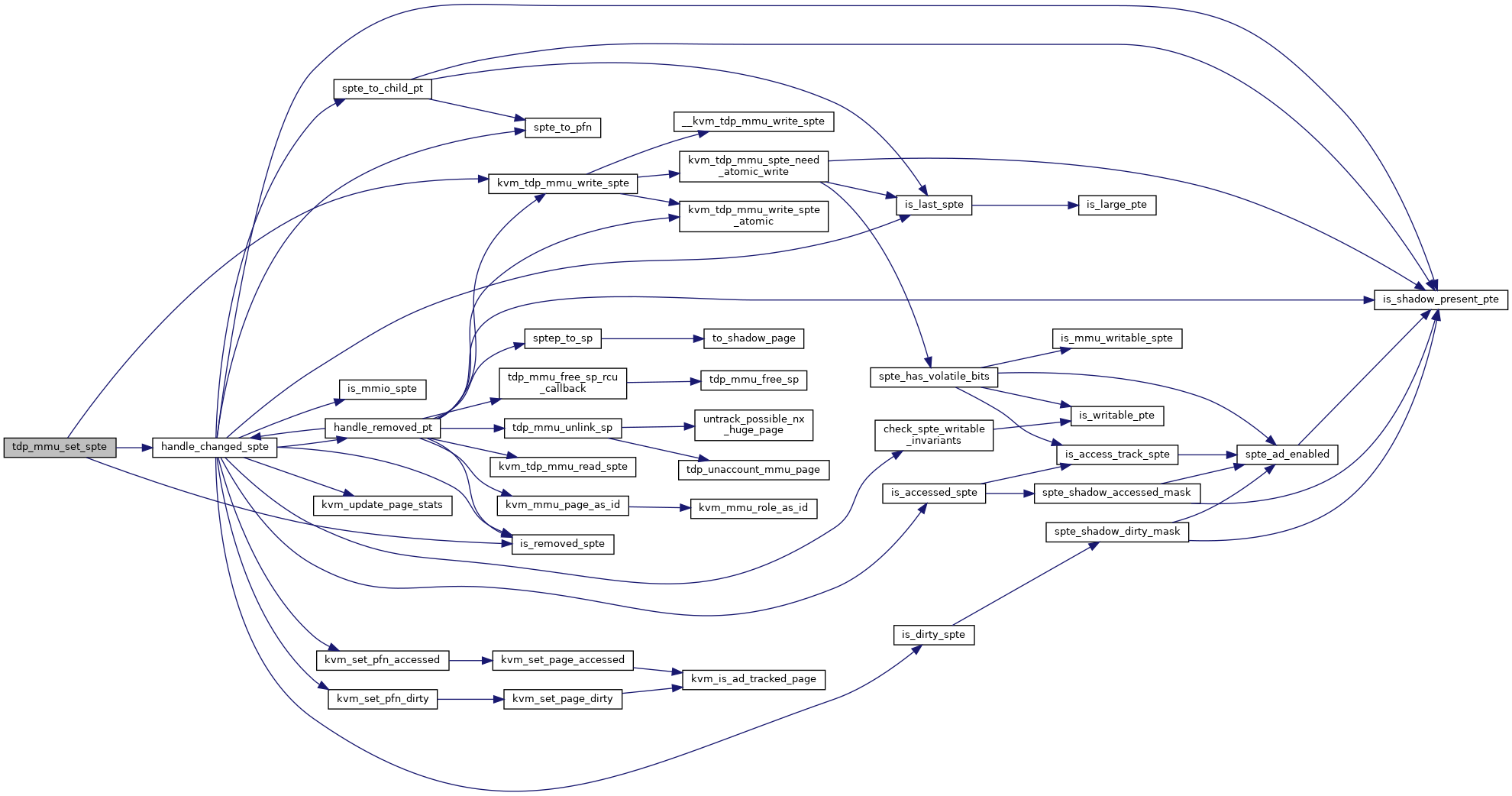
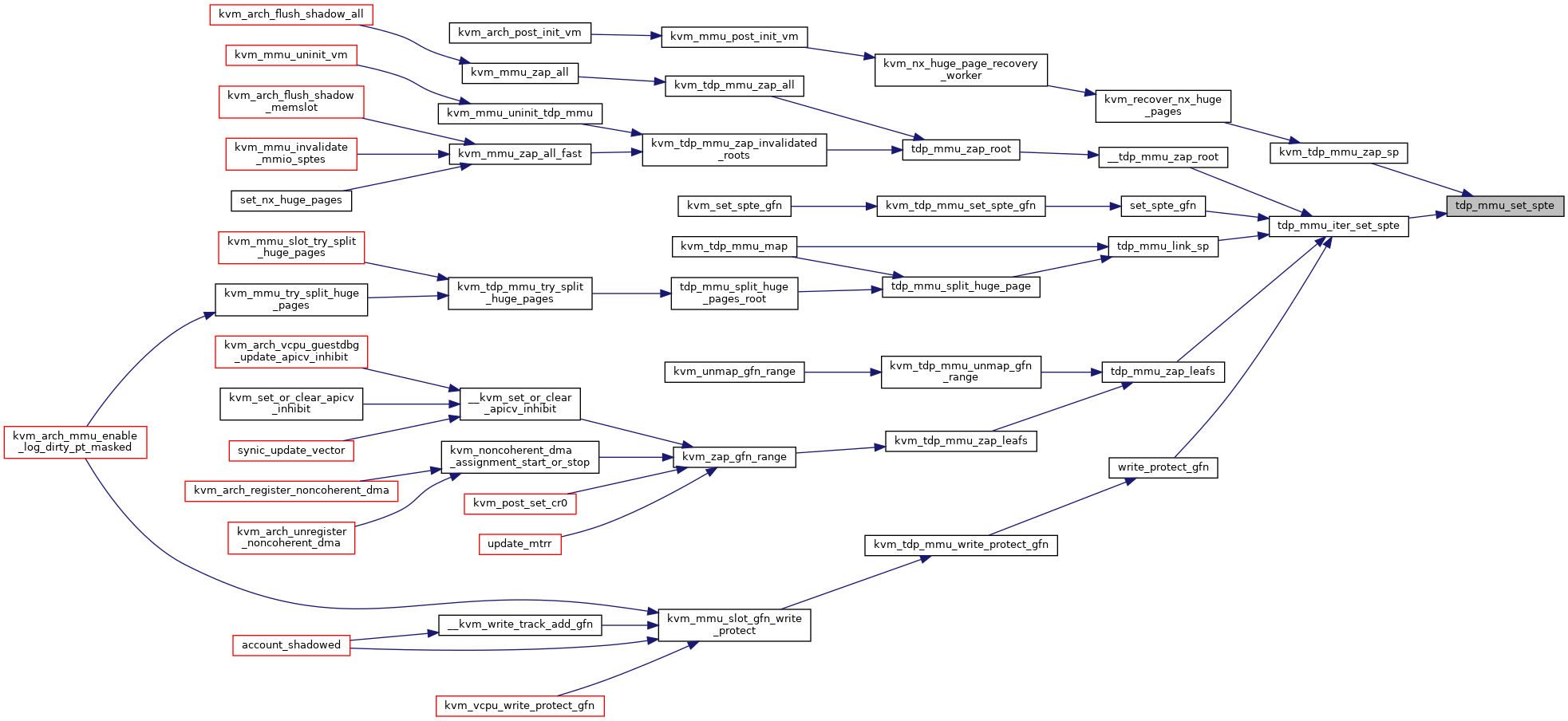
◆ tdp_mmu_set_spte_atomic()
|
inlinestatic |

◆ tdp_mmu_split_huge_page()
|
static |
Definition at line 1376 of file tdp_mmu.c.

◆ tdp_mmu_split_huge_pages_root()
|
static |
Definition at line 1414 of file tdp_mmu.c.

◆ tdp_mmu_unlink_sp()
|
static |
tdp_mmu_unlink_sp() - Remove a shadow page from the list of used pages
@kvm: kvm instance @sp: the page to be removed
Definition at line 279 of file tdp_mmu.c.
◆ tdp_mmu_zap_leafs()
|
static |
◆ tdp_mmu_zap_root()
|
static |
Definition at line 716 of file tdp_mmu.c.

◆ tdp_mmu_zap_spte_atomic()
|
inlinestatic |
Definition at line 549 of file tdp_mmu.c.

◆ tdp_unaccount_mmu_page()
|
static |
◆ test_age_gfn()
|
static |

◆ write_protect_gfn()
|
static |
◆ wrprot_gfn_range()
|
static |

◆ zap_collapsible_spte_range()
|
static |
Definition at line 1640 of file tdp_mmu.c.