#include "irq.h"#include "ioapic.h"#include "mmu.h"#include "mmu_internal.h"#include "tdp_mmu.h"#include "x86.h"#include "kvm_cache_regs.h"#include "smm.h"#include "kvm_emulate.h"#include "page_track.h"#include "cpuid.h"#include "spte.h"#include <linux/kvm_host.h>#include <linux/types.h>#include <linux/string.h>#include <linux/mm.h>#include <linux/highmem.h>#include <linux/moduleparam.h>#include <linux/export.h>#include <linux/swap.h>#include <linux/hugetlb.h>#include <linux/compiler.h>#include <linux/srcu.h>#include <linux/slab.h>#include <linux/sched/signal.h>#include <linux/uaccess.h>#include <linux/hash.h>#include <linux/kern_levels.h>#include <linux/kstrtox.h>#include <linux/kthread.h>#include <asm/page.h>#include <asm/memtype.h>#include <asm/cmpxchg.h>#include <asm/io.h>#include <asm/set_memory.h>#include <asm/vmx.h>#include "trace.h"#include <trace/events/kvm.h>#include "mmutrace.h"#include "paging_tmpl.h"
Go to the source code of this file.
Classes | |
| struct | pte_list_desc |
| struct | kvm_shadow_walk_iterator |
| struct | kvm_mmu_role_regs |
| union | split_spte |
| struct | rmap_iterator |
| struct | slot_rmap_walk_iterator |
| struct | kvm_mmu_pages |
| struct | kvm_mmu_pages::mmu_page_and_offset |
| struct | mmu_page_path |
| struct | shadow_page_caches |
Macros | |
| #define | pr_fmt(fmt) KBUILD_MODNAME ": " fmt |
| #define | PTE_PREFETCH_NUM 8 |
| #define | PTE_LIST_EXT 14 |
| #define | for_each_shadow_entry_using_root(_vcpu, _root, _addr, _walker) |
| #define | for_each_shadow_entry(_vcpu, _addr, _walker) |
| #define | for_each_shadow_entry_lockless(_vcpu, _addr, _walker, spte) |
| #define | CREATE_TRACE_POINTS |
| #define | BUILD_MMU_ROLE_REGS_ACCESSOR(reg, name, flag) |
| #define | BUILD_MMU_ROLE_ACCESSOR(base_or_ext, reg, name) |
| #define | KVM_LPAGE_MIXED_FLAG BIT(31) |
| #define | for_each_rmap_spte(_rmap_head_, _iter_, _spte_) |
| #define | for_each_slot_rmap_range(_slot_, _start_level_, _end_level_, _start_gfn, _end_gfn, _iter_) |
| #define | RMAP_RECYCLE_THRESHOLD 1000 |
| #define | KVM_PAGE_ARRAY_NR 16 |
| #define | INVALID_INDEX (-1) |
| #define | for_each_valid_sp(_kvm, _sp, _list) |
| #define | for_each_gfn_valid_sp_with_gptes(_kvm, _sp, _gfn) |
| #define | for_each_sp(pvec, sp, parents, i) |
| #define | PTTYPE_EPT 18 /* arbitrary */ |
| #define | PTTYPE PTTYPE_EPT |
| #define | PTTYPE 64 |
| #define | PTTYPE 32 |
| #define | BYTE_MASK(access) |
| #define | BATCH_ZAP_PAGES 10 |
Typedefs | |
| typedef bool(* | rmap_handler_t) (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t pte) |
| typedef bool(* | slot_rmaps_handler) (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
Functions | |
| static int | get_nx_huge_pages (char *buffer, const struct kernel_param *kp) |
| static int | set_nx_huge_pages (const char *val, const struct kernel_param *kp) |
| static int | set_nx_huge_pages_recovery_param (const char *val, const struct kernel_param *kp) |
| module_param_cb (nx_huge_pages, &nx_huge_pages_ops, &nx_huge_pages, 0644) | |
| __MODULE_PARM_TYPE (nx_huge_pages, "bool") | |
| module_param_cb (nx_huge_pages_recovery_ratio, &nx_huge_pages_recovery_param_ops, &nx_huge_pages_recovery_ratio, 0644) | |
| __MODULE_PARM_TYPE (nx_huge_pages_recovery_ratio, "uint") | |
| module_param_cb (nx_huge_pages_recovery_period_ms, &nx_huge_pages_recovery_param_ops, &nx_huge_pages_recovery_period_ms, 0644) | |
| __MODULE_PARM_TYPE (nx_huge_pages_recovery_period_ms, "uint") | |
| module_param_named (flush_on_reuse, force_flush_and_sync_on_reuse, bool, 0644) | |
| static void | mmu_spte_set (u64 *sptep, u64 spte) |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr0, pg, X86_CR0_PG) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr0, wp, X86_CR0_WP) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, pse, X86_CR4_PSE) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, pae, X86_CR4_PAE) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, smep, X86_CR4_SMEP) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, smap, X86_CR4_SMAP) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, pke, X86_CR4_PKE) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (cr4, la57, X86_CR4_LA57) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (efer, nx, EFER_NX) | |
| BUILD_MMU_ROLE_REGS_ACCESSOR (efer, lma, EFER_LMA) | |
| BUILD_MMU_ROLE_ACCESSOR (base, cr0, wp) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, cr4, pse) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, cr4, smep) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, cr4, smap) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, cr4, pke) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, cr4, la57) | |
| BUILD_MMU_ROLE_ACCESSOR (base, efer, nx) | |
| BUILD_MMU_ROLE_ACCESSOR (ext, efer, lma) | |
| static bool | is_cr0_pg (struct kvm_mmu *mmu) |
| static bool | is_cr4_pae (struct kvm_mmu *mmu) |
| static struct kvm_mmu_role_regs | vcpu_to_role_regs (struct kvm_vcpu *vcpu) |
| static unsigned long | get_guest_cr3 (struct kvm_vcpu *vcpu) |
| static unsigned long | kvm_mmu_get_guest_pgd (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu) |
| static bool | kvm_available_flush_remote_tlbs_range (void) |
| static gfn_t | kvm_mmu_page_get_gfn (struct kvm_mmu_page *sp, int index) |
| static void | kvm_flush_remote_tlbs_sptep (struct kvm *kvm, u64 *sptep) |
| static void | mark_mmio_spte (struct kvm_vcpu *vcpu, u64 *sptep, u64 gfn, unsigned int access) |
| static gfn_t | get_mmio_spte_gfn (u64 spte) |
| static unsigned | get_mmio_spte_access (u64 spte) |
| static bool | check_mmio_spte (struct kvm_vcpu *vcpu, u64 spte) |
| static int | is_cpuid_PSE36 (void) |
| static void | count_spte_clear (u64 *sptep, u64 spte) |
| static void | __set_spte (u64 *sptep, u64 spte) |
| static void | __update_clear_spte_fast (u64 *sptep, u64 spte) |
| static u64 | __update_clear_spte_slow (u64 *sptep, u64 spte) |
| static u64 | __get_spte_lockless (u64 *sptep) |
| static u64 | mmu_spte_update_no_track (u64 *sptep, u64 new_spte) |
| static bool | mmu_spte_update (u64 *sptep, u64 new_spte) |
| static u64 | mmu_spte_clear_track_bits (struct kvm *kvm, u64 *sptep) |
| static void | mmu_spte_clear_no_track (u64 *sptep) |
| static u64 | mmu_spte_get_lockless (u64 *sptep) |
| static bool | mmu_spte_age (u64 *sptep) |
| static bool | is_tdp_mmu_active (struct kvm_vcpu *vcpu) |
| static void | walk_shadow_page_lockless_begin (struct kvm_vcpu *vcpu) |
| static void | walk_shadow_page_lockless_end (struct kvm_vcpu *vcpu) |
| static int | mmu_topup_memory_caches (struct kvm_vcpu *vcpu, bool maybe_indirect) |
| static void | mmu_free_memory_caches (struct kvm_vcpu *vcpu) |
| static void | mmu_free_pte_list_desc (struct pte_list_desc *pte_list_desc) |
| static bool | sp_has_gptes (struct kvm_mmu_page *sp) |
| static u32 | kvm_mmu_page_get_access (struct kvm_mmu_page *sp, int index) |
| static void | kvm_mmu_page_set_translation (struct kvm_mmu_page *sp, int index, gfn_t gfn, unsigned int access) |
| static void | kvm_mmu_page_set_access (struct kvm_mmu_page *sp, int index, unsigned int access) |
| static struct kvm_lpage_info * | lpage_info_slot (gfn_t gfn, const struct kvm_memory_slot *slot, int level) |
| static void | update_gfn_disallow_lpage_count (const struct kvm_memory_slot *slot, gfn_t gfn, int count) |
| void | kvm_mmu_gfn_disallow_lpage (const struct kvm_memory_slot *slot, gfn_t gfn) |
| void | kvm_mmu_gfn_allow_lpage (const struct kvm_memory_slot *slot, gfn_t gfn) |
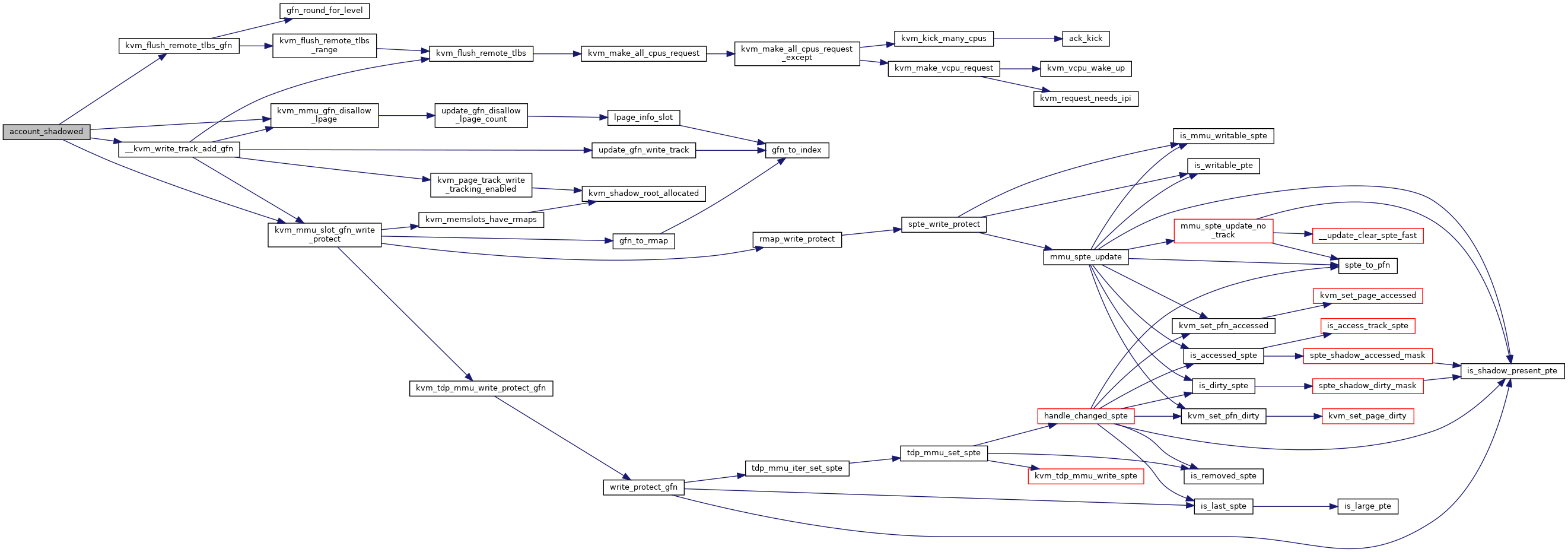
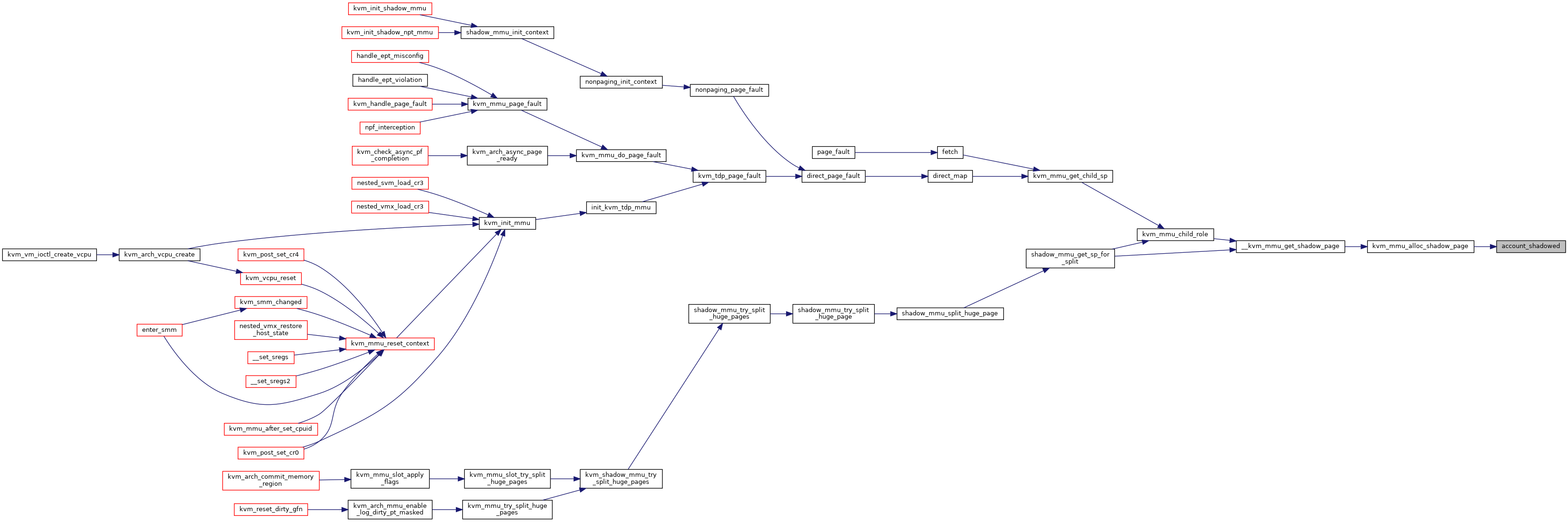
| static void | account_shadowed (struct kvm *kvm, struct kvm_mmu_page *sp) |
| void | track_possible_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | account_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp, bool nx_huge_page_possible) |
| static void | unaccount_shadowed (struct kvm *kvm, struct kvm_mmu_page *sp) |
| void | untrack_possible_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | unaccount_nx_huge_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static struct kvm_memory_slot * | gfn_to_memslot_dirty_bitmap (struct kvm_vcpu *vcpu, gfn_t gfn, bool no_dirty_log) |
| static int | pte_list_add (struct kvm_mmu_memory_cache *cache, u64 *spte, struct kvm_rmap_head *rmap_head) |
| static void | pte_list_desc_remove_entry (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct pte_list_desc *desc, int i) |
| static void | pte_list_remove (struct kvm *kvm, u64 *spte, struct kvm_rmap_head *rmap_head) |
| static void | kvm_zap_one_rmap_spte (struct kvm *kvm, struct kvm_rmap_head *rmap_head, u64 *sptep) |
| static bool | kvm_zap_all_rmap_sptes (struct kvm *kvm, struct kvm_rmap_head *rmap_head) |
| unsigned int | pte_list_count (struct kvm_rmap_head *rmap_head) |
| static struct kvm_rmap_head * | gfn_to_rmap (gfn_t gfn, int level, const struct kvm_memory_slot *slot) |
| static void | rmap_remove (struct kvm *kvm, u64 *spte) |
| static u64 * | rmap_get_first (struct kvm_rmap_head *rmap_head, struct rmap_iterator *iter) |
| static u64 * | rmap_get_next (struct rmap_iterator *iter) |
| static void | drop_spte (struct kvm *kvm, u64 *sptep) |
| static void | drop_large_spte (struct kvm *kvm, u64 *sptep, bool flush) |
| static bool | spte_write_protect (u64 *sptep, bool pt_protect) |
| static bool | rmap_write_protect (struct kvm_rmap_head *rmap_head, bool pt_protect) |
| static bool | spte_clear_dirty (u64 *sptep) |
| static bool | spte_wrprot_for_clear_dirty (u64 *sptep) |
| static bool | __rmap_clear_dirty (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
| static void | kvm_mmu_write_protect_pt_masked (struct kvm *kvm, struct kvm_memory_slot *slot, gfn_t gfn_offset, unsigned long mask) |
| static void | kvm_mmu_clear_dirty_pt_masked (struct kvm *kvm, struct kvm_memory_slot *slot, gfn_t gfn_offset, unsigned long mask) |
| void | kvm_arch_mmu_enable_log_dirty_pt_masked (struct kvm *kvm, struct kvm_memory_slot *slot, gfn_t gfn_offset, unsigned long mask) |
| int | kvm_cpu_dirty_log_size (void) |
| bool | kvm_mmu_slot_gfn_write_protect (struct kvm *kvm, struct kvm_memory_slot *slot, u64 gfn, int min_level) |
| static bool | kvm_vcpu_write_protect_gfn (struct kvm_vcpu *vcpu, u64 gfn) |
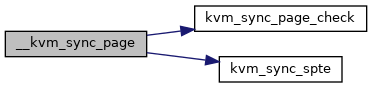
| static bool | __kvm_zap_rmap (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
| static bool | kvm_zap_rmap (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t unused) |
| static bool | kvm_set_pte_rmap (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t pte) |
| static void | rmap_walk_init_level (struct slot_rmap_walk_iterator *iterator, int level) |
| static void | slot_rmap_walk_init (struct slot_rmap_walk_iterator *iterator, const struct kvm_memory_slot *slot, int start_level, int end_level, gfn_t start_gfn, gfn_t end_gfn) |
| static bool | slot_rmap_walk_okay (struct slot_rmap_walk_iterator *iterator) |
| static void | slot_rmap_walk_next (struct slot_rmap_walk_iterator *iterator) |
| static __always_inline bool | kvm_handle_gfn_range (struct kvm *kvm, struct kvm_gfn_range *range, rmap_handler_t handler) |
| bool | kvm_unmap_gfn_range (struct kvm *kvm, struct kvm_gfn_range *range) |
| bool | kvm_set_spte_gfn (struct kvm *kvm, struct kvm_gfn_range *range) |
| static bool | kvm_age_rmap (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t unused) |
| static bool | kvm_test_age_rmap (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t unused) |
| static void | __rmap_add (struct kvm *kvm, struct kvm_mmu_memory_cache *cache, const struct kvm_memory_slot *slot, u64 *spte, gfn_t gfn, unsigned int access) |
| static void | rmap_add (struct kvm_vcpu *vcpu, const struct kvm_memory_slot *slot, u64 *spte, gfn_t gfn, unsigned int access) |
| bool | kvm_age_gfn (struct kvm *kvm, struct kvm_gfn_range *range) |
| bool | kvm_test_age_gfn (struct kvm *kvm, struct kvm_gfn_range *range) |
| static void | kvm_mmu_check_sptes_at_free (struct kvm_mmu_page *sp) |
| static void | kvm_mod_used_mmu_pages (struct kvm *kvm, long nr) |
| static void | kvm_account_mmu_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | kvm_unaccount_mmu_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static void | kvm_mmu_free_shadow_page (struct kvm_mmu_page *sp) |
| static unsigned | kvm_page_table_hashfn (gfn_t gfn) |
| static void | mmu_page_add_parent_pte (struct kvm_mmu_memory_cache *cache, struct kvm_mmu_page *sp, u64 *parent_pte) |
| static void | mmu_page_remove_parent_pte (struct kvm *kvm, struct kvm_mmu_page *sp, u64 *parent_pte) |
| static void | drop_parent_pte (struct kvm *kvm, struct kvm_mmu_page *sp, u64 *parent_pte) |
| static void | mark_unsync (u64 *spte) |
| static void | kvm_mmu_mark_parents_unsync (struct kvm_mmu_page *sp) |
| static int | mmu_pages_add (struct kvm_mmu_pages *pvec, struct kvm_mmu_page *sp, int idx) |
| static void | clear_unsync_child_bit (struct kvm_mmu_page *sp, int idx) |
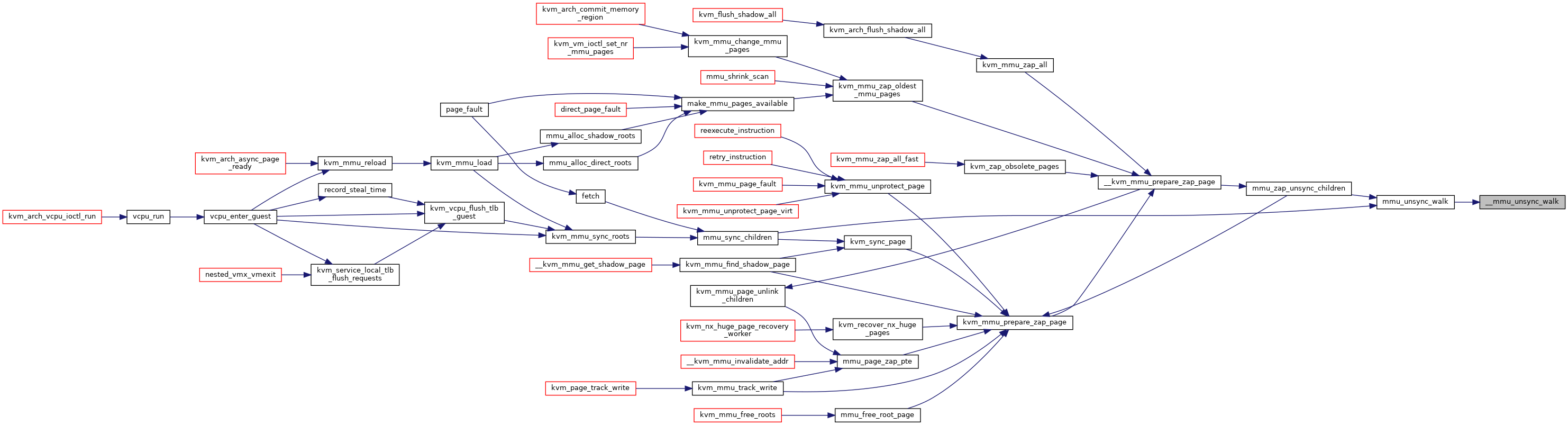
| static int | __mmu_unsync_walk (struct kvm_mmu_page *sp, struct kvm_mmu_pages *pvec) |
| static int | mmu_unsync_walk (struct kvm_mmu_page *sp, struct kvm_mmu_pages *pvec) |
| static void | kvm_unlink_unsync_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
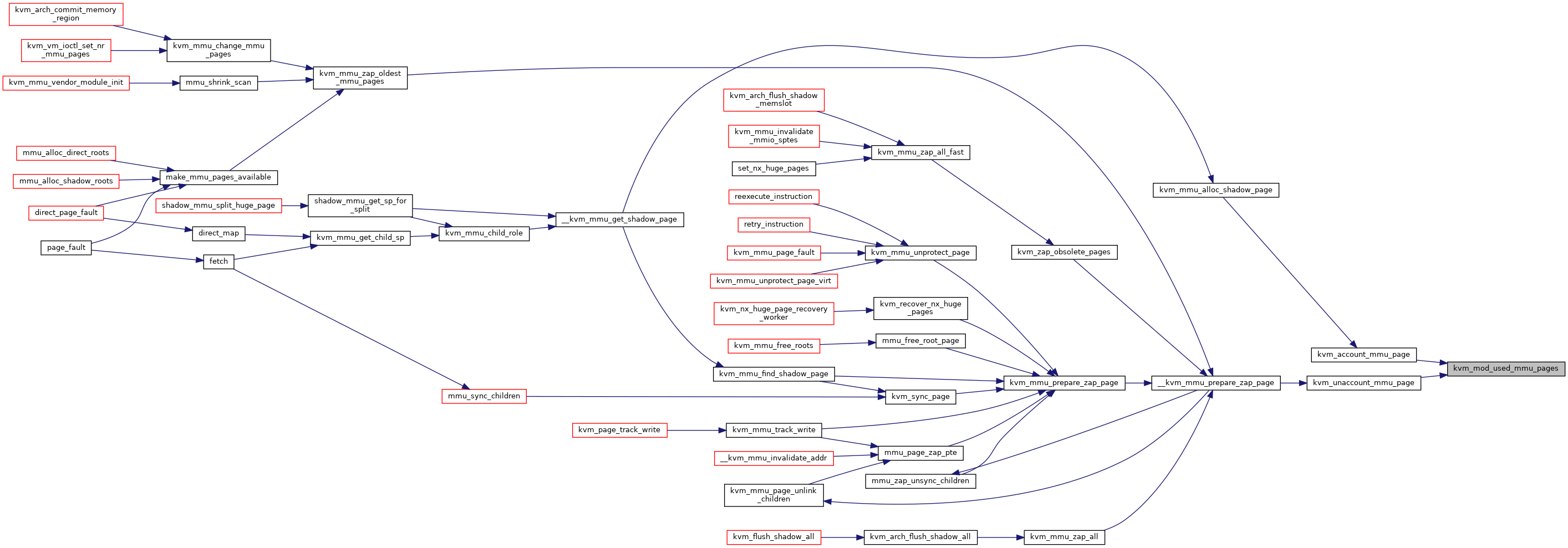
| static bool | kvm_mmu_prepare_zap_page (struct kvm *kvm, struct kvm_mmu_page *sp, struct list_head *invalid_list) |
| static void | kvm_mmu_commit_zap_page (struct kvm *kvm, struct list_head *invalid_list) |
| static bool | kvm_sync_page_check (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp) |
| static int | kvm_sync_spte (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp, int i) |
| static int | __kvm_sync_page (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp) |
| static int | kvm_sync_page (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp, struct list_head *invalid_list) |
| static bool | kvm_mmu_remote_flush_or_zap (struct kvm *kvm, struct list_head *invalid_list, bool remote_flush) |
| static bool | is_obsolete_sp (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static int | mmu_pages_next (struct kvm_mmu_pages *pvec, struct mmu_page_path *parents, int i) |
| static int | mmu_pages_first (struct kvm_mmu_pages *pvec, struct mmu_page_path *parents) |
| static void | mmu_pages_clear_parents (struct mmu_page_path *parents) |
| static int | mmu_sync_children (struct kvm_vcpu *vcpu, struct kvm_mmu_page *parent, bool can_yield) |
| static void | __clear_sp_write_flooding_count (struct kvm_mmu_page *sp) |
| static void | clear_sp_write_flooding_count (u64 *spte) |
| static struct kvm_mmu_page * | kvm_mmu_find_shadow_page (struct kvm *kvm, struct kvm_vcpu *vcpu, gfn_t gfn, struct hlist_head *sp_list, union kvm_mmu_page_role role) |
| static struct kvm_mmu_page * | kvm_mmu_alloc_shadow_page (struct kvm *kvm, struct shadow_page_caches *caches, gfn_t gfn, struct hlist_head *sp_list, union kvm_mmu_page_role role) |
| static struct kvm_mmu_page * | __kvm_mmu_get_shadow_page (struct kvm *kvm, struct kvm_vcpu *vcpu, struct shadow_page_caches *caches, gfn_t gfn, union kvm_mmu_page_role role) |
| static struct kvm_mmu_page * | kvm_mmu_get_shadow_page (struct kvm_vcpu *vcpu, gfn_t gfn, union kvm_mmu_page_role role) |
| static union kvm_mmu_page_role | kvm_mmu_child_role (u64 *sptep, bool direct, unsigned int access) |
| static struct kvm_mmu_page * | kvm_mmu_get_child_sp (struct kvm_vcpu *vcpu, u64 *sptep, gfn_t gfn, bool direct, unsigned int access) |
| static void | shadow_walk_init_using_root (struct kvm_shadow_walk_iterator *iterator, struct kvm_vcpu *vcpu, hpa_t root, u64 addr) |
| static void | shadow_walk_init (struct kvm_shadow_walk_iterator *iterator, struct kvm_vcpu *vcpu, u64 addr) |
| static bool | shadow_walk_okay (struct kvm_shadow_walk_iterator *iterator) |
| static void | __shadow_walk_next (struct kvm_shadow_walk_iterator *iterator, u64 spte) |
| static void | shadow_walk_next (struct kvm_shadow_walk_iterator *iterator) |
| static void | __link_shadow_page (struct kvm *kvm, struct kvm_mmu_memory_cache *cache, u64 *sptep, struct kvm_mmu_page *sp, bool flush) |
| static void | link_shadow_page (struct kvm_vcpu *vcpu, u64 *sptep, struct kvm_mmu_page *sp) |
| static void | validate_direct_spte (struct kvm_vcpu *vcpu, u64 *sptep, unsigned direct_access) |
| static int | mmu_page_zap_pte (struct kvm *kvm, struct kvm_mmu_page *sp, u64 *spte, struct list_head *invalid_list) |
| static int | kvm_mmu_page_unlink_children (struct kvm *kvm, struct kvm_mmu_page *sp, struct list_head *invalid_list) |
| static void | kvm_mmu_unlink_parents (struct kvm *kvm, struct kvm_mmu_page *sp) |
| static int | mmu_zap_unsync_children (struct kvm *kvm, struct kvm_mmu_page *parent, struct list_head *invalid_list) |
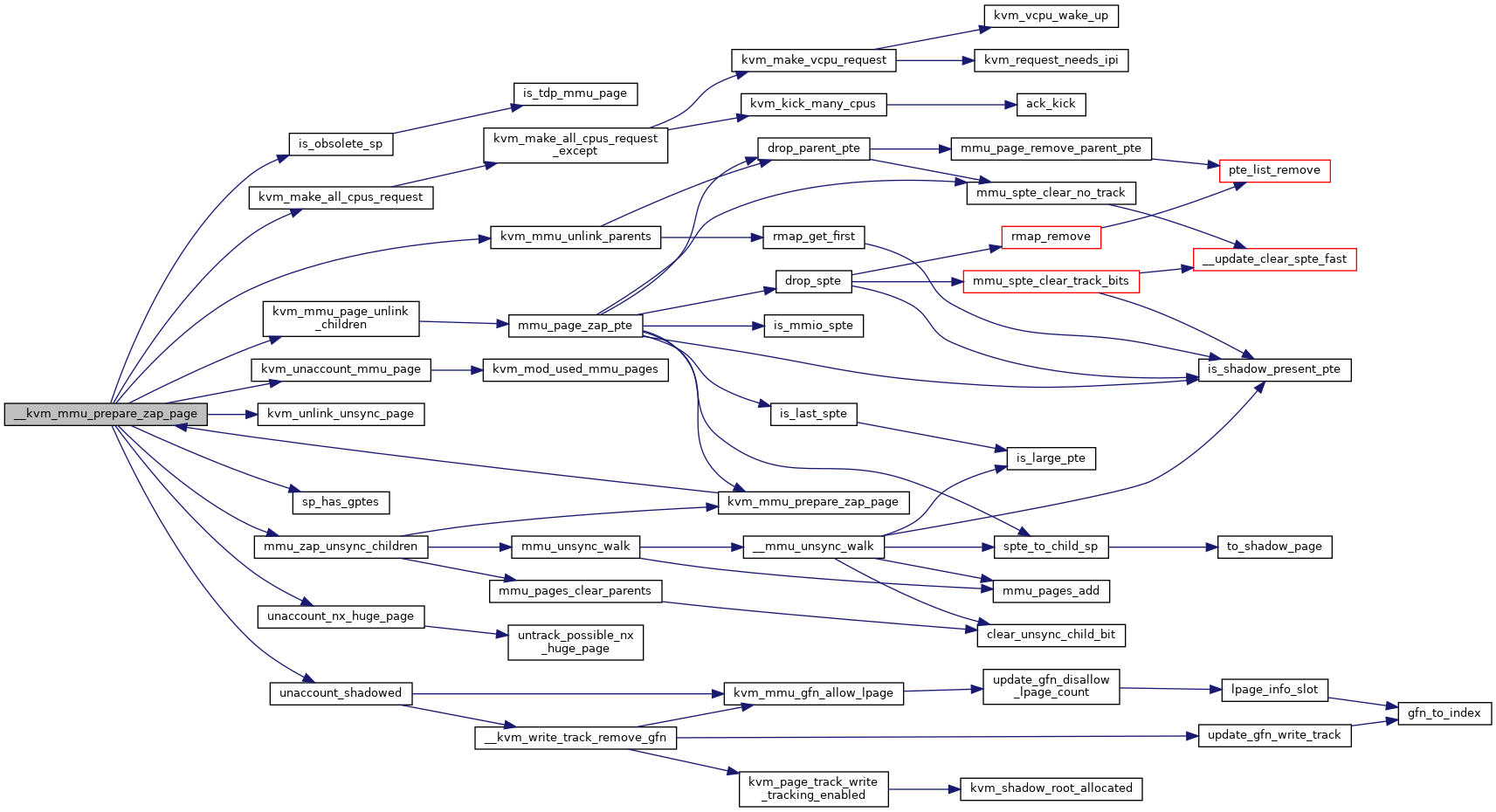
| static bool | __kvm_mmu_prepare_zap_page (struct kvm *kvm, struct kvm_mmu_page *sp, struct list_head *invalid_list, int *nr_zapped) |
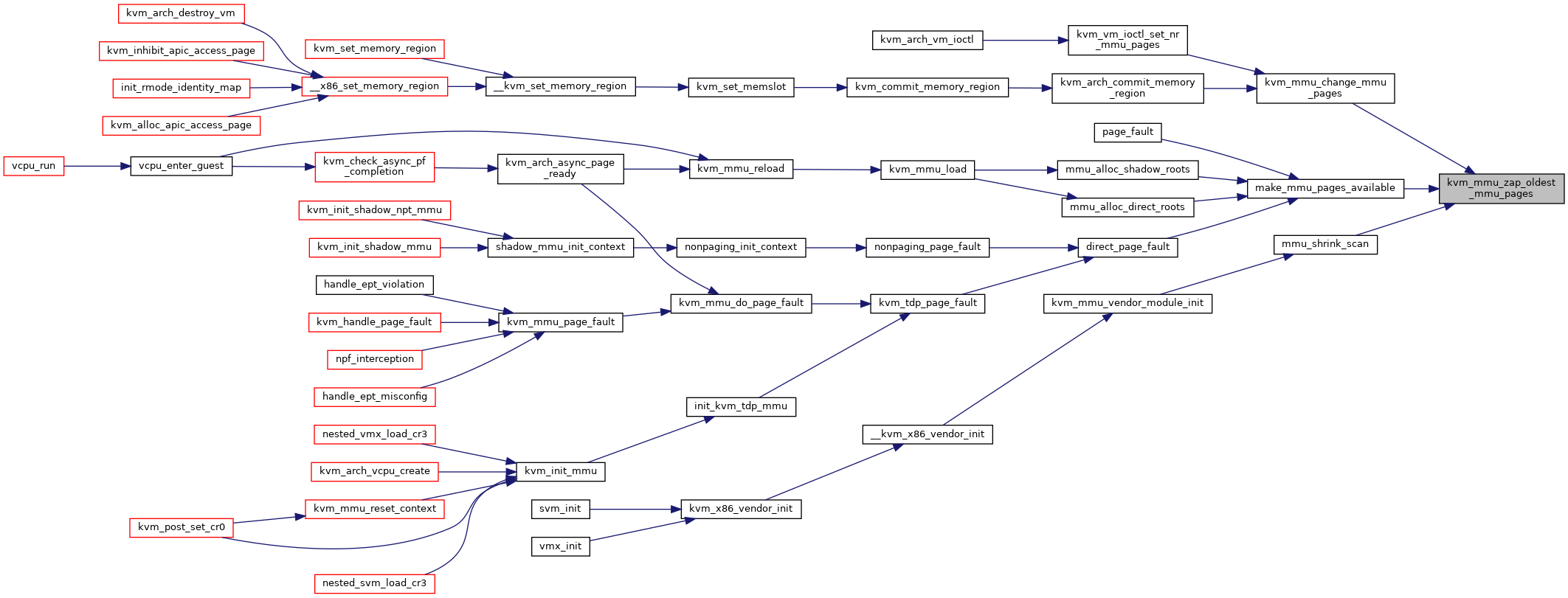
| static unsigned long | kvm_mmu_zap_oldest_mmu_pages (struct kvm *kvm, unsigned long nr_to_zap) |
| static unsigned long | kvm_mmu_available_pages (struct kvm *kvm) |
| static int | make_mmu_pages_available (struct kvm_vcpu *vcpu) |
| void | kvm_mmu_change_mmu_pages (struct kvm *kvm, unsigned long goal_nr_mmu_pages) |
| int | kvm_mmu_unprotect_page (struct kvm *kvm, gfn_t gfn) |
| static int | kvm_mmu_unprotect_page_virt (struct kvm_vcpu *vcpu, gva_t gva) |
| static void | kvm_unsync_page (struct kvm *kvm, struct kvm_mmu_page *sp) |
| int | mmu_try_to_unsync_pages (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t gfn, bool can_unsync, bool prefetch) |
| static int | mmu_set_spte (struct kvm_vcpu *vcpu, struct kvm_memory_slot *slot, u64 *sptep, unsigned int pte_access, gfn_t gfn, kvm_pfn_t pfn, struct kvm_page_fault *fault) |
| static int | direct_pte_prefetch_many (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp, u64 *start, u64 *end) |
| static void | __direct_pte_prefetch (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp, u64 *sptep) |
| static void | direct_pte_prefetch (struct kvm_vcpu *vcpu, u64 *sptep) |
| static int | host_pfn_mapping_level (struct kvm *kvm, gfn_t gfn, const struct kvm_memory_slot *slot) |
| static int | __kvm_mmu_max_mapping_level (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t gfn, int max_level, bool is_private) |
| int | kvm_mmu_max_mapping_level (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t gfn, int max_level) |
| void | kvm_mmu_hugepage_adjust (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| void | disallowed_hugepage_adjust (struct kvm_page_fault *fault, u64 spte, int cur_level) |
| static int | direct_map (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static void | kvm_send_hwpoison_signal (struct kvm_memory_slot *slot, gfn_t gfn) |
| static int | kvm_handle_error_pfn (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | kvm_handle_noslot_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, unsigned int access) |
| static bool | page_fault_can_be_fast (struct kvm_page_fault *fault) |
| static bool | fast_pf_fix_direct_spte (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, u64 *sptep, u64 old_spte, u64 new_spte) |
| static bool | is_access_allowed (struct kvm_page_fault *fault, u64 spte) |
| static u64 * | fast_pf_get_last_sptep (struct kvm_vcpu *vcpu, gpa_t gpa, u64 *spte) |
| static int | fast_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static void | mmu_free_root_page (struct kvm *kvm, hpa_t *root_hpa, struct list_head *invalid_list) |
| void | kvm_mmu_free_roots (struct kvm *kvm, struct kvm_mmu *mmu, ulong roots_to_free) |
| EXPORT_SYMBOL_GPL (kvm_mmu_free_roots) | |
| void | kvm_mmu_free_guest_mode_roots (struct kvm *kvm, struct kvm_mmu *mmu) |
| EXPORT_SYMBOL_GPL (kvm_mmu_free_guest_mode_roots) | |
| static hpa_t | mmu_alloc_root (struct kvm_vcpu *vcpu, gfn_t gfn, int quadrant, u8 level) |
| static int | mmu_alloc_direct_roots (struct kvm_vcpu *vcpu) |
| static int | mmu_first_shadow_root_alloc (struct kvm *kvm) |
| static int | mmu_alloc_shadow_roots (struct kvm_vcpu *vcpu) |
| static int | mmu_alloc_special_roots (struct kvm_vcpu *vcpu) |
| static bool | is_unsync_root (hpa_t root) |
| void | kvm_mmu_sync_roots (struct kvm_vcpu *vcpu) |
| void | kvm_mmu_sync_prev_roots (struct kvm_vcpu *vcpu) |
| static gpa_t | nonpaging_gva_to_gpa (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu, gpa_t vaddr, u64 access, struct x86_exception *exception) |
| static bool | mmio_info_in_cache (struct kvm_vcpu *vcpu, u64 addr, bool direct) |
| static int | get_walk (struct kvm_vcpu *vcpu, u64 addr, u64 *sptes, int *root_level) |
| static bool | get_mmio_spte (struct kvm_vcpu *vcpu, u64 addr, u64 *sptep) |
| static int | handle_mmio_page_fault (struct kvm_vcpu *vcpu, u64 addr, bool direct) |
| static bool | page_fault_handle_page_track (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static void | shadow_page_table_clear_flood (struct kvm_vcpu *vcpu, gva_t addr) |
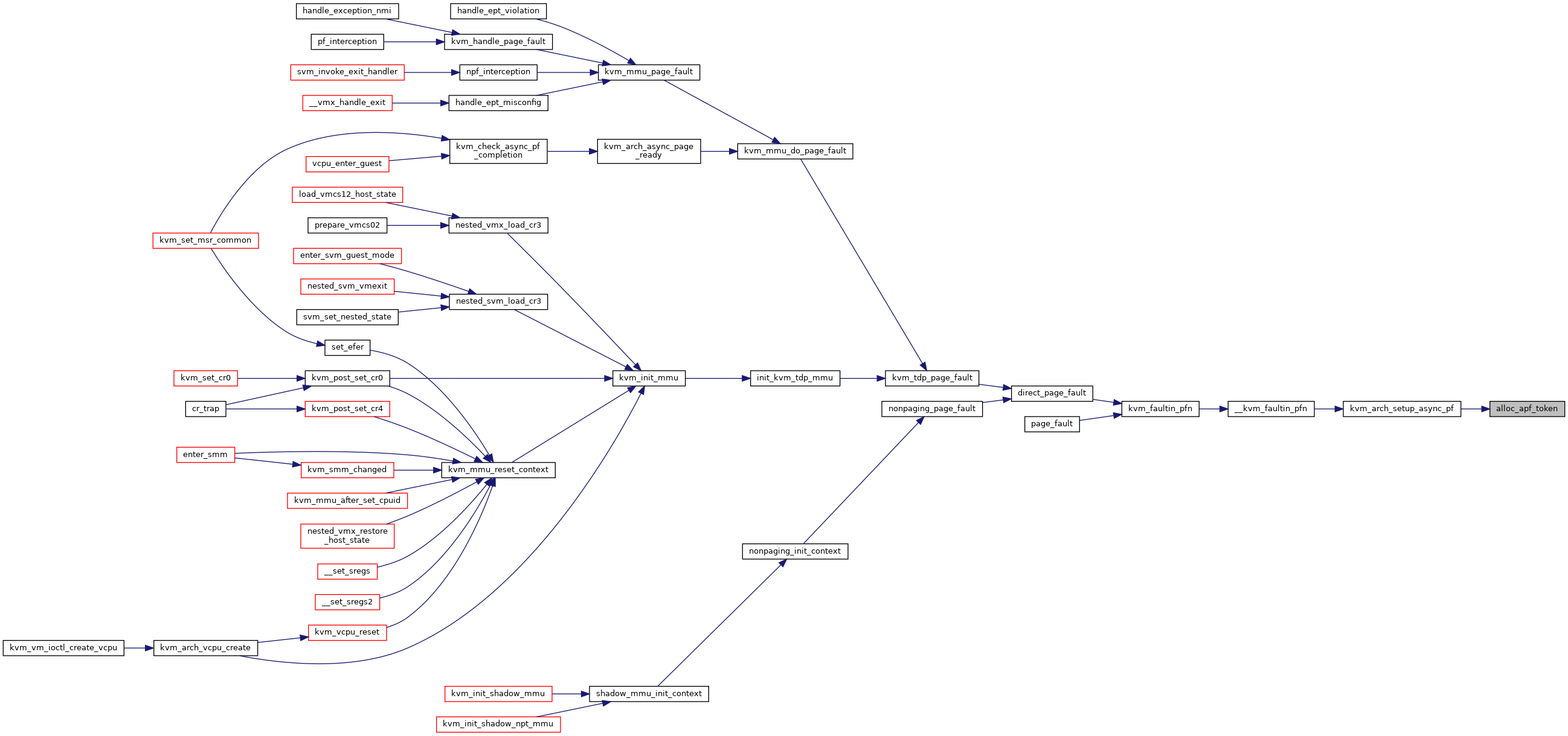
| static u32 | alloc_apf_token (struct kvm_vcpu *vcpu) |
| static bool | kvm_arch_setup_async_pf (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, gfn_t gfn) |
| void | kvm_arch_async_page_ready (struct kvm_vcpu *vcpu, struct kvm_async_pf *work) |
| static u8 | kvm_max_level_for_order (int order) |
| static void | kvm_mmu_prepare_memory_fault_exit (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | kvm_faultin_pfn_private (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | __kvm_faultin_pfn (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | kvm_faultin_pfn (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, unsigned int access) |
| static bool | is_page_fault_stale (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | direct_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static int | nonpaging_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| int | kvm_handle_page_fault (struct kvm_vcpu *vcpu, u64 error_code, u64 fault_address, char *insn, int insn_len) |
| EXPORT_SYMBOL_GPL (kvm_handle_page_fault) | |
| bool | __kvm_mmu_honors_guest_mtrrs (bool vm_has_noncoherent_dma) |
| int | kvm_tdp_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) |
| static void | nonpaging_init_context (struct kvm_mmu *context) |
| static bool | is_root_usable (struct kvm_mmu_root_info *root, gpa_t pgd, union kvm_mmu_page_role role) |
| static bool | cached_root_find_and_keep_current (struct kvm *kvm, struct kvm_mmu *mmu, gpa_t new_pgd, union kvm_mmu_page_role new_role) |
| static bool | cached_root_find_without_current (struct kvm *kvm, struct kvm_mmu *mmu, gpa_t new_pgd, union kvm_mmu_page_role new_role) |
| static bool | fast_pgd_switch (struct kvm *kvm, struct kvm_mmu *mmu, gpa_t new_pgd, union kvm_mmu_page_role new_role) |
| void | kvm_mmu_new_pgd (struct kvm_vcpu *vcpu, gpa_t new_pgd) |
| EXPORT_SYMBOL_GPL (kvm_mmu_new_pgd) | |
| static bool | sync_mmio_spte (struct kvm_vcpu *vcpu, u64 *sptep, gfn_t gfn, unsigned int access) |
| static void | __reset_rsvds_bits_mask (struct rsvd_bits_validate *rsvd_check, u64 pa_bits_rsvd, int level, bool nx, bool gbpages, bool pse, bool amd) |
| static void | reset_guest_rsvds_bits_mask (struct kvm_vcpu *vcpu, struct kvm_mmu *context) |
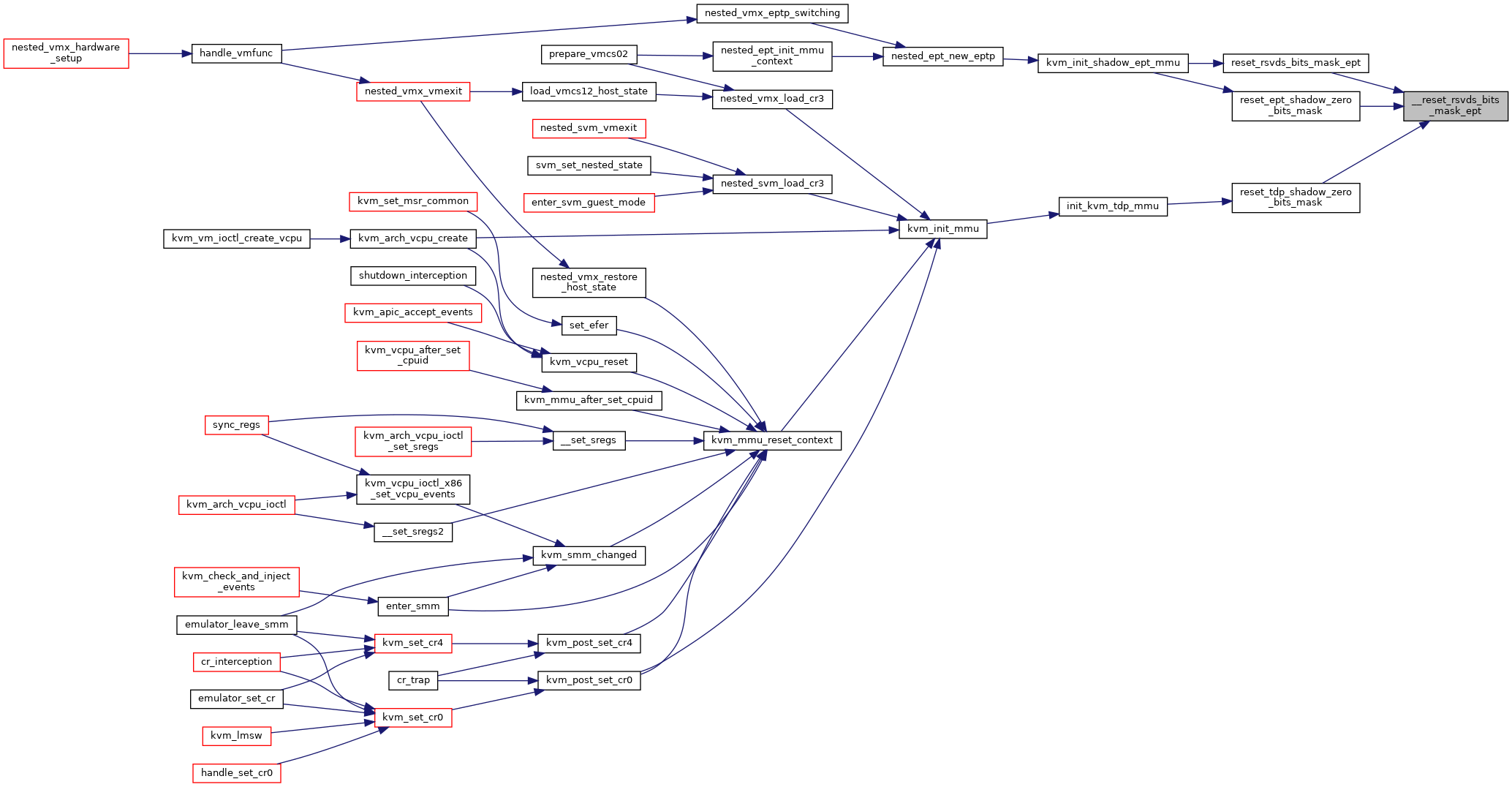
| static void | __reset_rsvds_bits_mask_ept (struct rsvd_bits_validate *rsvd_check, u64 pa_bits_rsvd, bool execonly, int huge_page_level) |
| static void | reset_rsvds_bits_mask_ept (struct kvm_vcpu *vcpu, struct kvm_mmu *context, bool execonly, int huge_page_level) |
| static u64 | reserved_hpa_bits (void) |
| static void | reset_shadow_zero_bits_mask (struct kvm_vcpu *vcpu, struct kvm_mmu *context) |
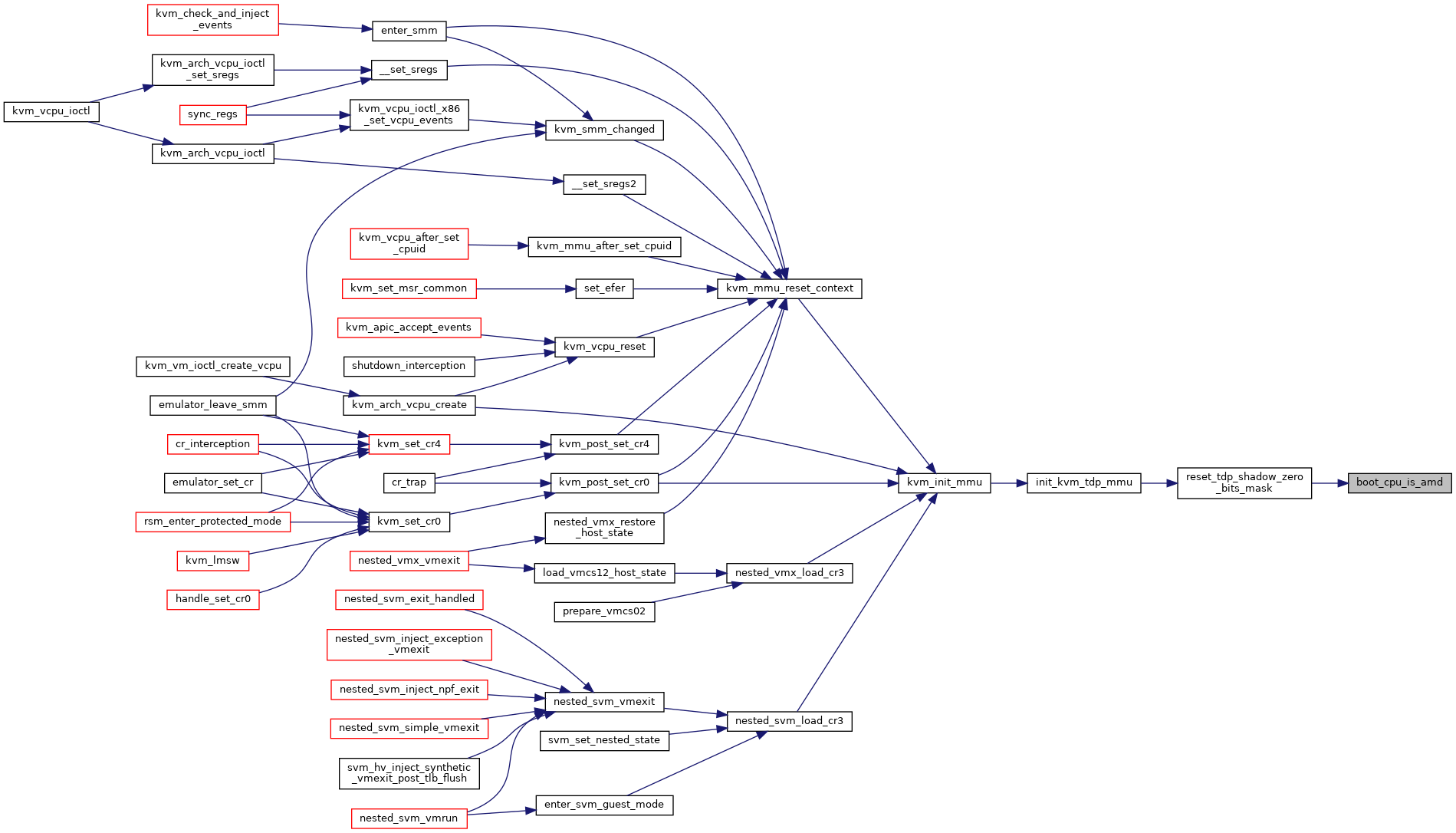
| static bool | boot_cpu_is_amd (void) |
| static void | reset_tdp_shadow_zero_bits_mask (struct kvm_mmu *context) |
| static void | reset_ept_shadow_zero_bits_mask (struct kvm_mmu *context, bool execonly) |
| static void | update_permission_bitmask (struct kvm_mmu *mmu, bool ept) |
| static void | update_pkru_bitmask (struct kvm_mmu *mmu) |
| static void | reset_guest_paging_metadata (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu) |
| static void | paging64_init_context (struct kvm_mmu *context) |
| static void | paging32_init_context (struct kvm_mmu *context) |
| static union kvm_cpu_role | kvm_calc_cpu_role (struct kvm_vcpu *vcpu, const struct kvm_mmu_role_regs *regs) |
| void | __kvm_mmu_refresh_passthrough_bits (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu) |
| static int | kvm_mmu_get_tdp_level (struct kvm_vcpu *vcpu) |
| static union kvm_mmu_page_role | kvm_calc_tdp_mmu_root_page_role (struct kvm_vcpu *vcpu, union kvm_cpu_role cpu_role) |
| static void | init_kvm_tdp_mmu (struct kvm_vcpu *vcpu, union kvm_cpu_role cpu_role) |
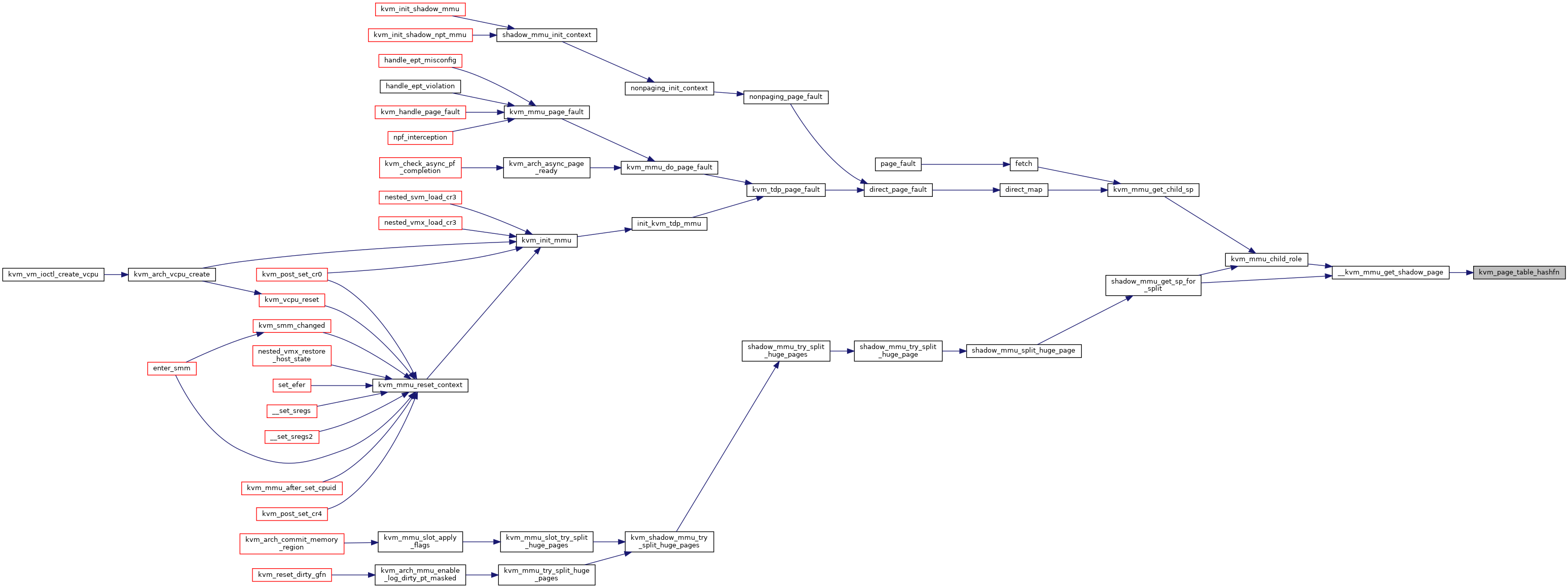
| static void | shadow_mmu_init_context (struct kvm_vcpu *vcpu, struct kvm_mmu *context, union kvm_cpu_role cpu_role, union kvm_mmu_page_role root_role) |
| static void | kvm_init_shadow_mmu (struct kvm_vcpu *vcpu, union kvm_cpu_role cpu_role) |
| void | kvm_init_shadow_npt_mmu (struct kvm_vcpu *vcpu, unsigned long cr0, unsigned long cr4, u64 efer, gpa_t nested_cr3) |
| EXPORT_SYMBOL_GPL (kvm_init_shadow_npt_mmu) | |
| static union kvm_cpu_role | kvm_calc_shadow_ept_root_page_role (struct kvm_vcpu *vcpu, bool accessed_dirty, bool execonly, u8 level) |
| void | kvm_init_shadow_ept_mmu (struct kvm_vcpu *vcpu, bool execonly, int huge_page_level, bool accessed_dirty, gpa_t new_eptp) |
| EXPORT_SYMBOL_GPL (kvm_init_shadow_ept_mmu) | |
| static void | init_kvm_softmmu (struct kvm_vcpu *vcpu, union kvm_cpu_role cpu_role) |
| static void | init_kvm_nested_mmu (struct kvm_vcpu *vcpu, union kvm_cpu_role new_mode) |
| void | kvm_init_mmu (struct kvm_vcpu *vcpu) |
| EXPORT_SYMBOL_GPL (kvm_init_mmu) | |
| void | kvm_mmu_after_set_cpuid (struct kvm_vcpu *vcpu) |
| void | kvm_mmu_reset_context (struct kvm_vcpu *vcpu) |
| EXPORT_SYMBOL_GPL (kvm_mmu_reset_context) | |
| int | kvm_mmu_load (struct kvm_vcpu *vcpu) |
| void | kvm_mmu_unload (struct kvm_vcpu *vcpu) |
| static bool | is_obsolete_root (struct kvm *kvm, hpa_t root_hpa) |
| static void | __kvm_mmu_free_obsolete_roots (struct kvm *kvm, struct kvm_mmu *mmu) |
| void | kvm_mmu_free_obsolete_roots (struct kvm_vcpu *vcpu) |
| static u64 | mmu_pte_write_fetch_gpte (struct kvm_vcpu *vcpu, gpa_t *gpa, int *bytes) |
| static bool | detect_write_flooding (struct kvm_mmu_page *sp) |
| static bool | detect_write_misaligned (struct kvm_mmu_page *sp, gpa_t gpa, int bytes) |
| static u64 * | get_written_sptes (struct kvm_mmu_page *sp, gpa_t gpa, int *nspte) |
| void | kvm_mmu_track_write (struct kvm_vcpu *vcpu, gpa_t gpa, const u8 *new, int bytes) |
| int noinline | kvm_mmu_page_fault (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u64 error_code, void *insn, int insn_len) |
| EXPORT_SYMBOL_GPL (kvm_mmu_page_fault) | |
| static void | __kvm_mmu_invalidate_addr (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu, u64 addr, hpa_t root_hpa) |
| void | kvm_mmu_invalidate_addr (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu, u64 addr, unsigned long roots) |
| EXPORT_SYMBOL_GPL (kvm_mmu_invalidate_addr) | |
| void | kvm_mmu_invlpg (struct kvm_vcpu *vcpu, gva_t gva) |
| EXPORT_SYMBOL_GPL (kvm_mmu_invlpg) | |
| void | kvm_mmu_invpcid_gva (struct kvm_vcpu *vcpu, gva_t gva, unsigned long pcid) |
| void | kvm_configure_mmu (bool enable_tdp, int tdp_forced_root_level, int tdp_max_root_level, int tdp_huge_page_level) |
| EXPORT_SYMBOL_GPL (kvm_configure_mmu) | |
| static __always_inline bool | __walk_slot_rmaps (struct kvm *kvm, const struct kvm_memory_slot *slot, slot_rmaps_handler fn, int start_level, int end_level, gfn_t start_gfn, gfn_t end_gfn, bool flush_on_yield, bool flush) |
| static __always_inline bool | walk_slot_rmaps (struct kvm *kvm, const struct kvm_memory_slot *slot, slot_rmaps_handler fn, int start_level, int end_level, bool flush_on_yield) |
| static __always_inline bool | walk_slot_rmaps_4k (struct kvm *kvm, const struct kvm_memory_slot *slot, slot_rmaps_handler fn, bool flush_on_yield) |
| static void | free_mmu_pages (struct kvm_mmu *mmu) |
| static int | __kvm_mmu_create (struct kvm_vcpu *vcpu, struct kvm_mmu *mmu) |
| int | kvm_mmu_create (struct kvm_vcpu *vcpu) |
| static void | kvm_zap_obsolete_pages (struct kvm *kvm) |
| static void | kvm_mmu_zap_all_fast (struct kvm *kvm) |
| static bool | kvm_has_zapped_obsolete_pages (struct kvm *kvm) |
| void | kvm_mmu_init_vm (struct kvm *kvm) |
| static void | mmu_free_vm_memory_caches (struct kvm *kvm) |
| void | kvm_mmu_uninit_vm (struct kvm *kvm) |
| static bool | kvm_rmap_zap_gfn_range (struct kvm *kvm, gfn_t gfn_start, gfn_t gfn_end) |
| void | kvm_zap_gfn_range (struct kvm *kvm, gfn_t gfn_start, gfn_t gfn_end) |
| static bool | slot_rmap_write_protect (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
| void | kvm_mmu_slot_remove_write_access (struct kvm *kvm, const struct kvm_memory_slot *memslot, int start_level) |
| static bool | need_topup (struct kvm_mmu_memory_cache *cache, int min) |
| static bool | need_topup_split_caches_or_resched (struct kvm *kvm) |
| static int | topup_split_caches (struct kvm *kvm) |
| static struct kvm_mmu_page * | shadow_mmu_get_sp_for_split (struct kvm *kvm, u64 *huge_sptep) |
| static void | shadow_mmu_split_huge_page (struct kvm *kvm, const struct kvm_memory_slot *slot, u64 *huge_sptep) |
| static int | shadow_mmu_try_split_huge_page (struct kvm *kvm, const struct kvm_memory_slot *slot, u64 *huge_sptep) |
| static bool | shadow_mmu_try_split_huge_pages (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
| static void | kvm_shadow_mmu_try_split_huge_pages (struct kvm *kvm, const struct kvm_memory_slot *slot, gfn_t start, gfn_t end, int target_level) |
| void | kvm_mmu_try_split_huge_pages (struct kvm *kvm, const struct kvm_memory_slot *memslot, u64 start, u64 end, int target_level) |
| void | kvm_mmu_slot_try_split_huge_pages (struct kvm *kvm, const struct kvm_memory_slot *memslot, int target_level) |
| static bool | kvm_mmu_zap_collapsible_spte (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
| static void | kvm_rmap_zap_collapsible_sptes (struct kvm *kvm, const struct kvm_memory_slot *slot) |
| void | kvm_mmu_zap_collapsible_sptes (struct kvm *kvm, const struct kvm_memory_slot *slot) |
| void | kvm_mmu_slot_leaf_clear_dirty (struct kvm *kvm, const struct kvm_memory_slot *memslot) |
| static void | kvm_mmu_zap_all (struct kvm *kvm) |
| void | kvm_arch_flush_shadow_all (struct kvm *kvm) |
| void | kvm_arch_flush_shadow_memslot (struct kvm *kvm, struct kvm_memory_slot *slot) |
| void | kvm_mmu_invalidate_mmio_sptes (struct kvm *kvm, u64 gen) |
| static unsigned long | mmu_shrink_scan (struct shrinker *shrink, struct shrink_control *sc) |
| static unsigned long | mmu_shrink_count (struct shrinker *shrink, struct shrink_control *sc) |
| static void | mmu_destroy_caches (void) |
| static bool | get_nx_auto_mode (void) |
| static void | __set_nx_huge_pages (bool val) |
| void __init | kvm_mmu_x86_module_init (void) |
| int | kvm_mmu_vendor_module_init (void) |
| void | kvm_mmu_destroy (struct kvm_vcpu *vcpu) |
| void | kvm_mmu_vendor_module_exit (void) |
| static bool | calc_nx_huge_pages_recovery_period (uint *period) |
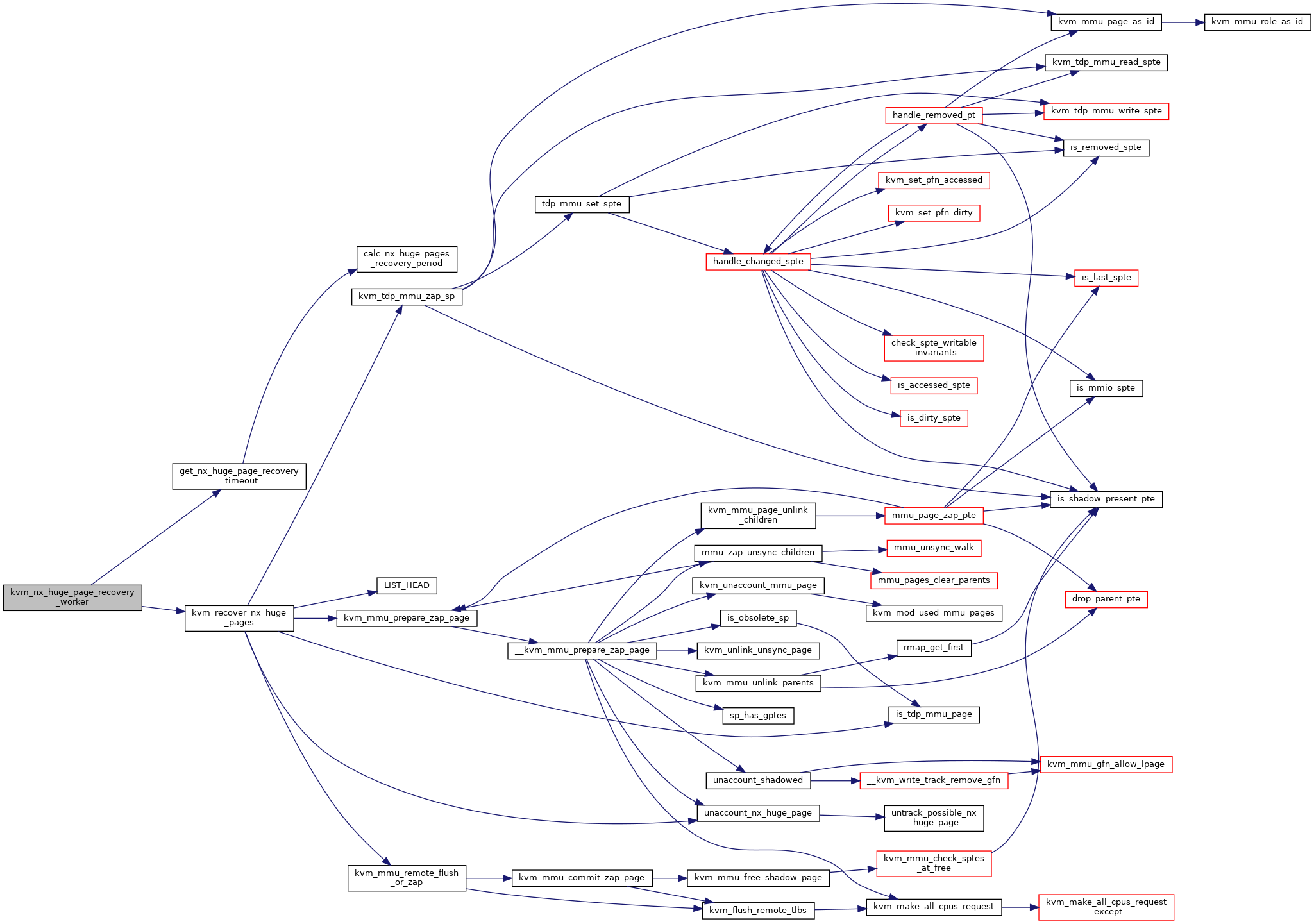
| static void | kvm_recover_nx_huge_pages (struct kvm *kvm) |
| static long | get_nx_huge_page_recovery_timeout (u64 start_time) |
| static int | kvm_nx_huge_page_recovery_worker (struct kvm *kvm, uintptr_t data) |
| int | kvm_mmu_post_init_vm (struct kvm *kvm) |
| void | kvm_mmu_pre_destroy_vm (struct kvm *kvm) |
Variables | |
| bool | itlb_multihit_kvm_mitigation |
| static bool | nx_hugepage_mitigation_hard_disabled |
| int __read_mostly | nx_huge_pages = -1 |
| static uint __read_mostly | nx_huge_pages_recovery_period_ms |
| static uint __read_mostly | nx_huge_pages_recovery_ratio = 60 |
| static const struct kernel_param_ops | nx_huge_pages_ops |
| static const struct kernel_param_ops | nx_huge_pages_recovery_param_ops |
| static bool __read_mostly | force_flush_and_sync_on_reuse |
| bool | tdp_enabled = false |
| static bool __ro_after_init | tdp_mmu_allowed |
| static int max_huge_page_level | __read_mostly |
| static struct kmem_cache * | pte_list_desc_cache |
| struct kmem_cache * | mmu_page_header_cache |
| static struct percpu_counter | kvm_total_used_mmu_pages |
| static struct shrinker * | mmu_shrinker |
Macro Definition Documentation
◆ BATCH_ZAP_PAGES
◆ BUILD_MMU_ROLE_ACCESSOR
| #define BUILD_MMU_ROLE_ACCESSOR | ( | base_or_ext, | |
| reg, | |||
| name | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR
| #define BUILD_MMU_ROLE_REGS_ACCESSOR | ( | reg, | |
| name, | |||
| flag | |||
| ) |
◆ BYTE_MASK
| #define BYTE_MASK | ( | access | ) |
◆ CREATE_TRACE_POINTS
◆ for_each_gfn_valid_sp_with_gptes
| #define for_each_gfn_valid_sp_with_gptes | ( | _kvm, | |
| _sp, | |||
| _gfn | |||
| ) |
◆ for_each_rmap_spte
| #define for_each_rmap_spte | ( | _rmap_head_, | |
| _iter_, | |||
| _spte_ | |||
| ) |
◆ for_each_shadow_entry
| #define for_each_shadow_entry | ( | _vcpu, | |
| _addr, | |||
| _walker | |||
| ) |
◆ for_each_shadow_entry_lockless
| #define for_each_shadow_entry_lockless | ( | _vcpu, | |
| _addr, | |||
| _walker, | |||
| spte | |||
| ) |
◆ for_each_shadow_entry_using_root
| #define for_each_shadow_entry_using_root | ( | _vcpu, | |
| _root, | |||
| _addr, | |||
| _walker | |||
| ) |
◆ for_each_slot_rmap_range
| #define for_each_slot_rmap_range | ( | _slot_, | |
| _start_level_, | |||
| _end_level_, | |||
| _start_gfn, | |||
| _end_gfn, | |||
| _iter_ | |||
| ) |
◆ for_each_sp
| #define for_each_sp | ( | pvec, | |
| sp, | |||
| parents, | |||
| i | |||
| ) |
◆ for_each_valid_sp
| #define for_each_valid_sp | ( | _kvm, | |
| _sp, | |||
| _list | |||
| ) |
◆ INVALID_INDEX
◆ KVM_LPAGE_MIXED_FLAG
◆ KVM_PAGE_ARRAY_NR
◆ pr_fmt
◆ PTE_LIST_EXT
◆ PTE_PREFETCH_NUM
◆ PTTYPE [1/3]
| #define PTTYPE PTTYPE_EPT |
◆ PTTYPE [2/3]
◆ PTTYPE [3/3]
◆ PTTYPE_EPT
◆ RMAP_RECYCLE_THRESHOLD
Typedef Documentation
◆ rmap_handler_t
| typedef bool(* rmap_handler_t) (struct kvm *kvm, struct kvm_rmap_head *rmap_head, struct kvm_memory_slot *slot, gfn_t gfn, int level, pte_t pte) |
◆ slot_rmaps_handler
| typedef bool(* slot_rmaps_handler) (struct kvm *kvm, struct kvm_rmap_head *rmap_head, const struct kvm_memory_slot *slot) |
Function Documentation
◆ __clear_sp_write_flooding_count()
|
static |
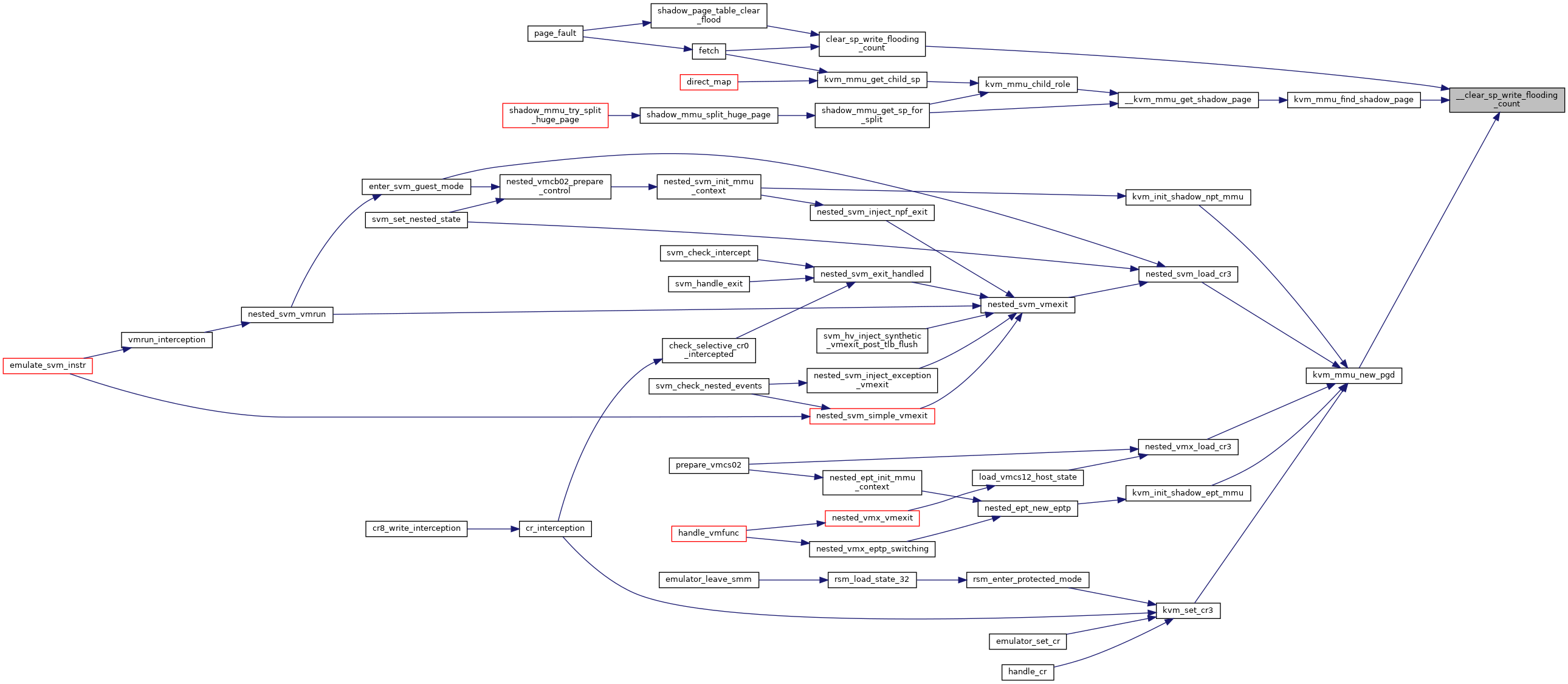
◆ __direct_pte_prefetch()
|
static |
Definition at line 3005 of file mmu.c.
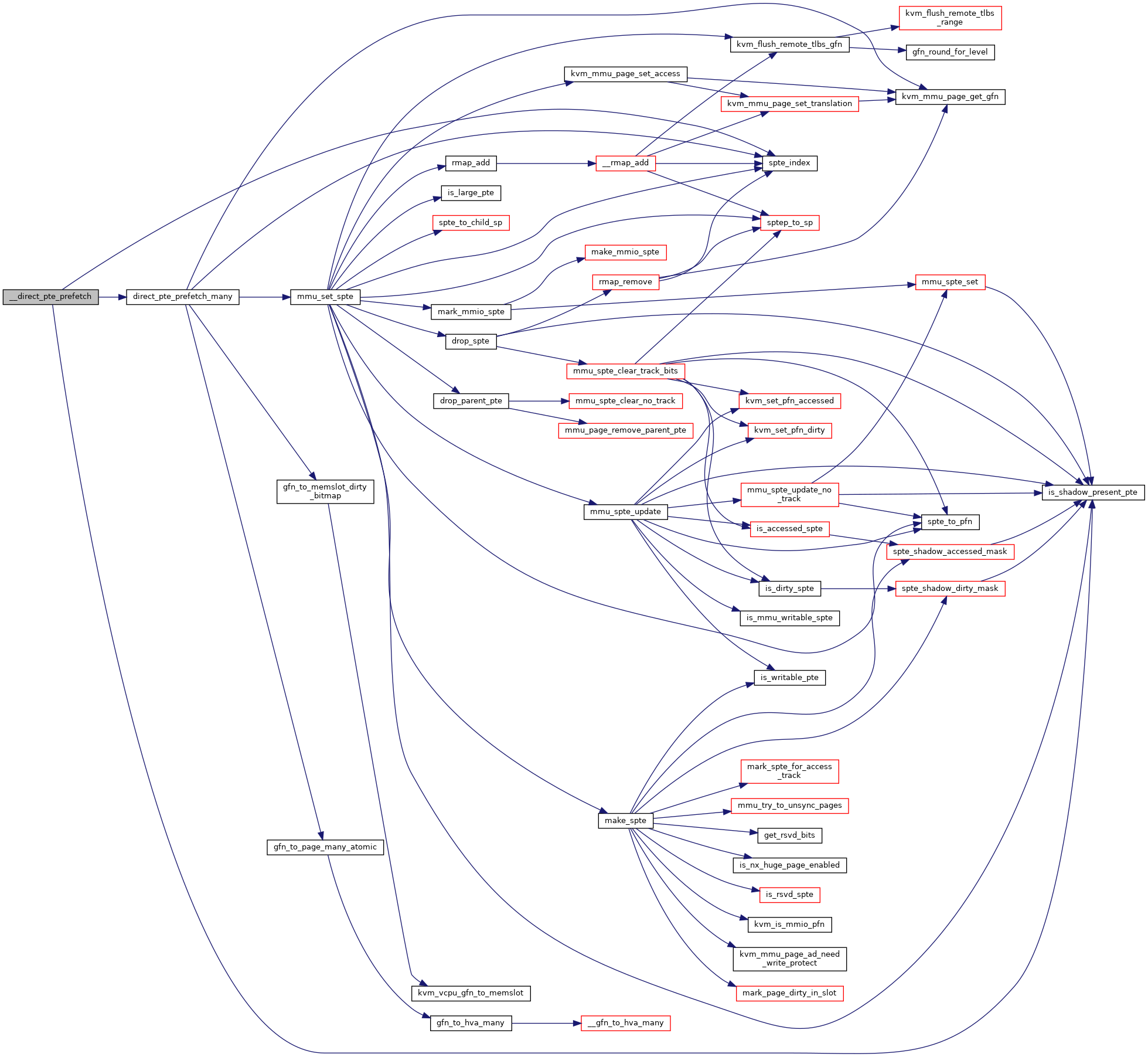
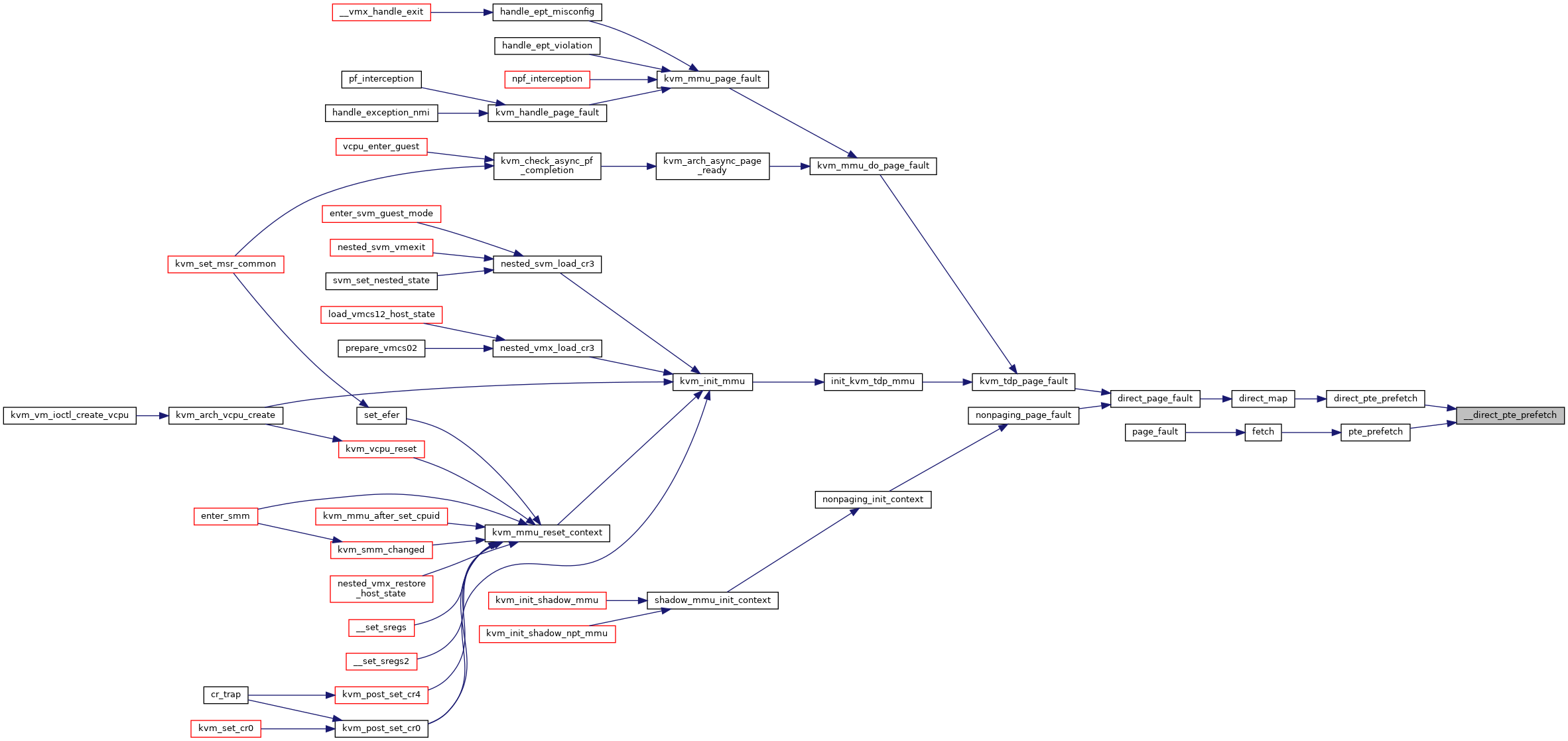
◆ __get_spte_lockless()
|
static |
Definition at line 449 of file mmu.c.


◆ __kvm_faultin_pfn()
|
static |
Definition at line 4331 of file mmu.c.
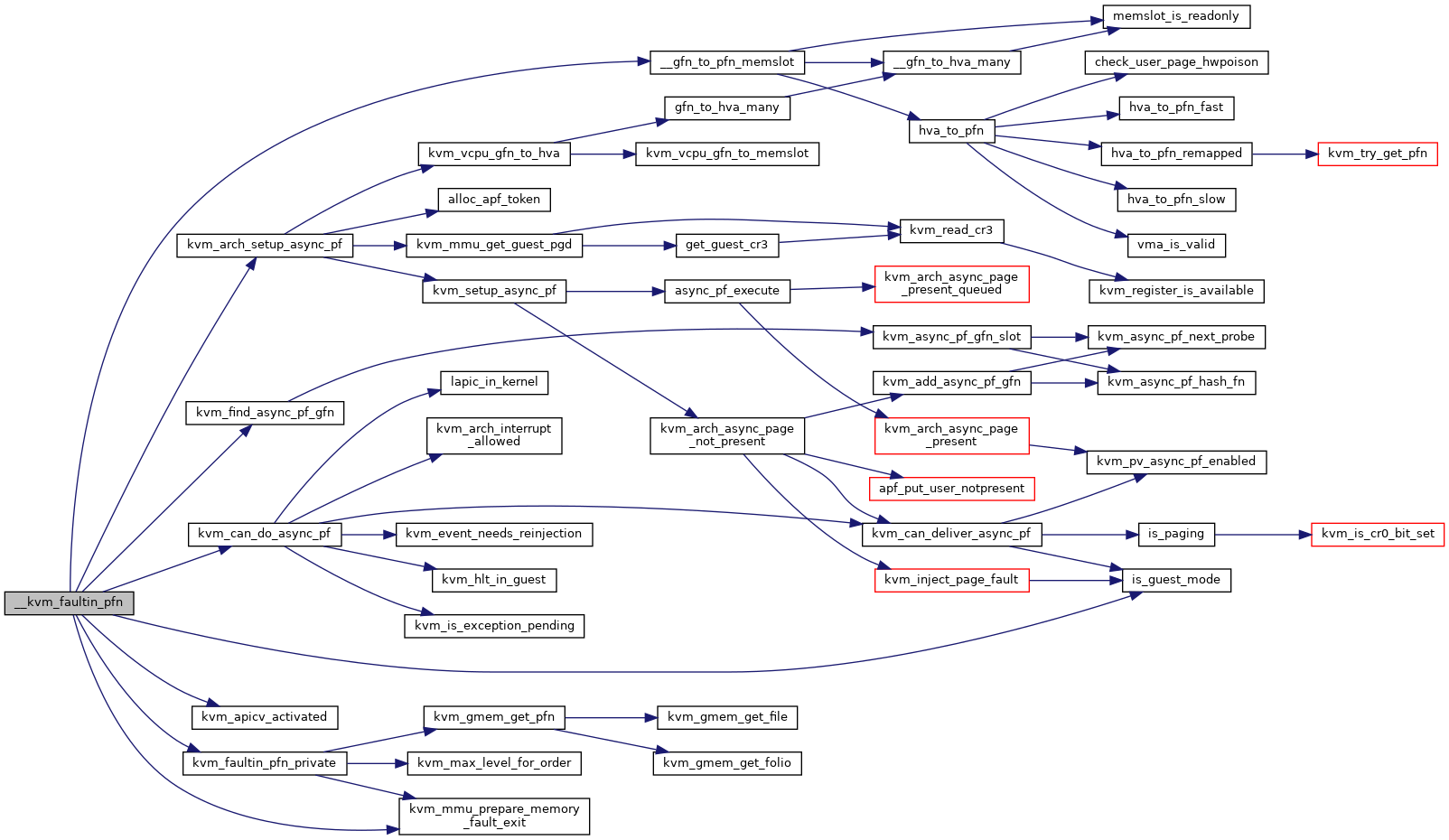
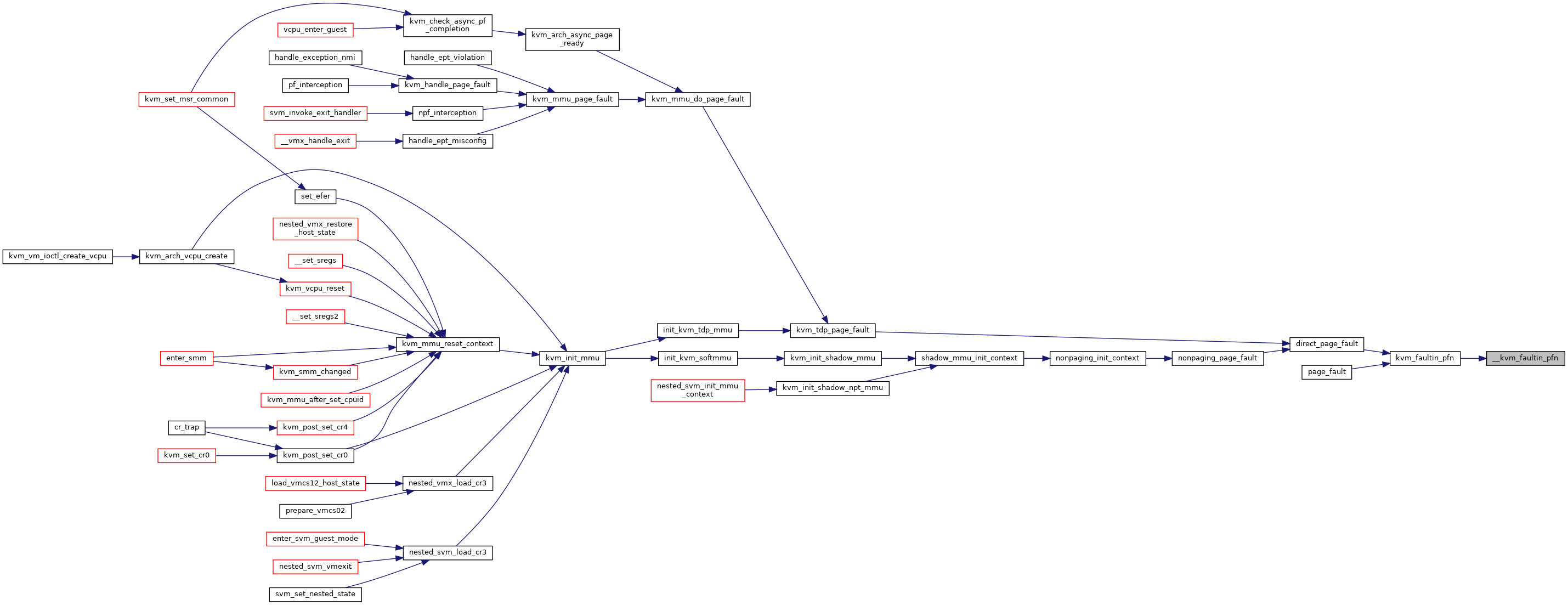
◆ __kvm_mmu_create()
|
static |


◆ __kvm_mmu_free_obsolete_roots()
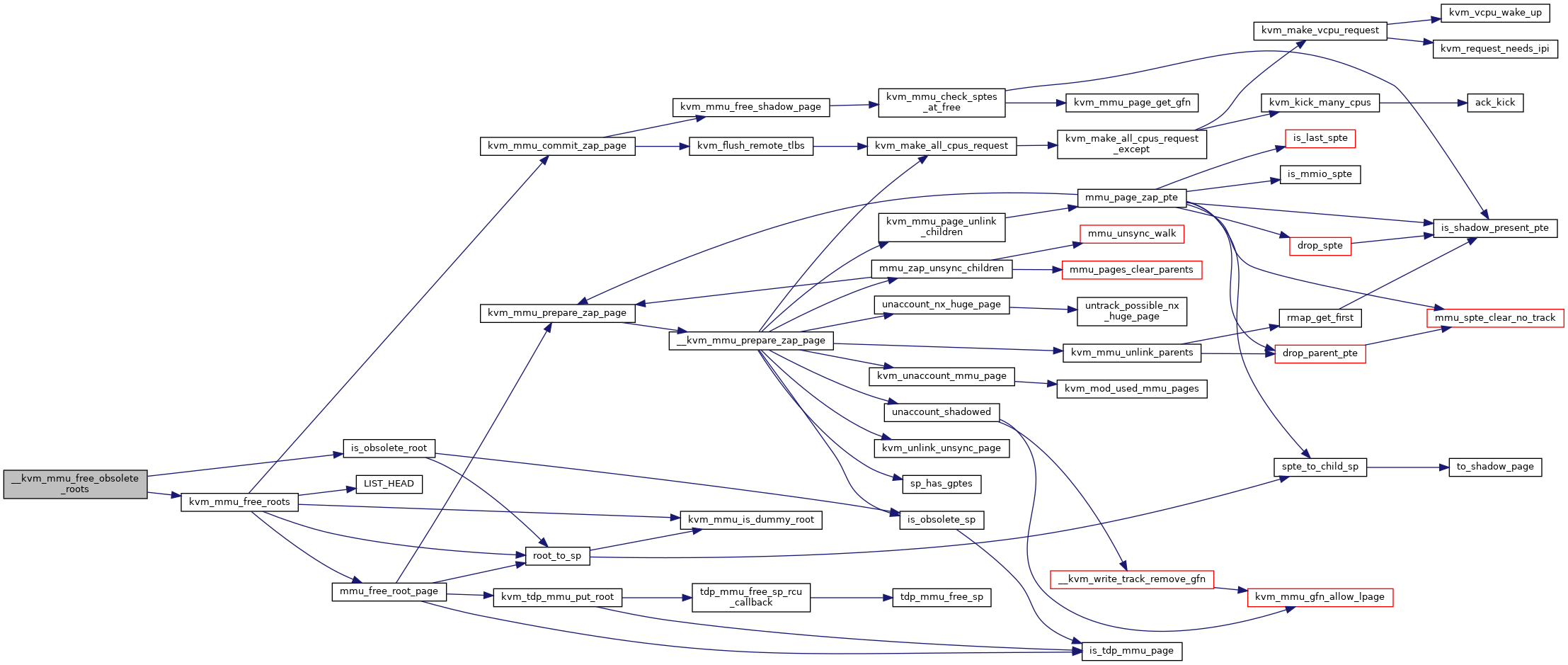
|
static |
Definition at line 5659 of file mmu.c.

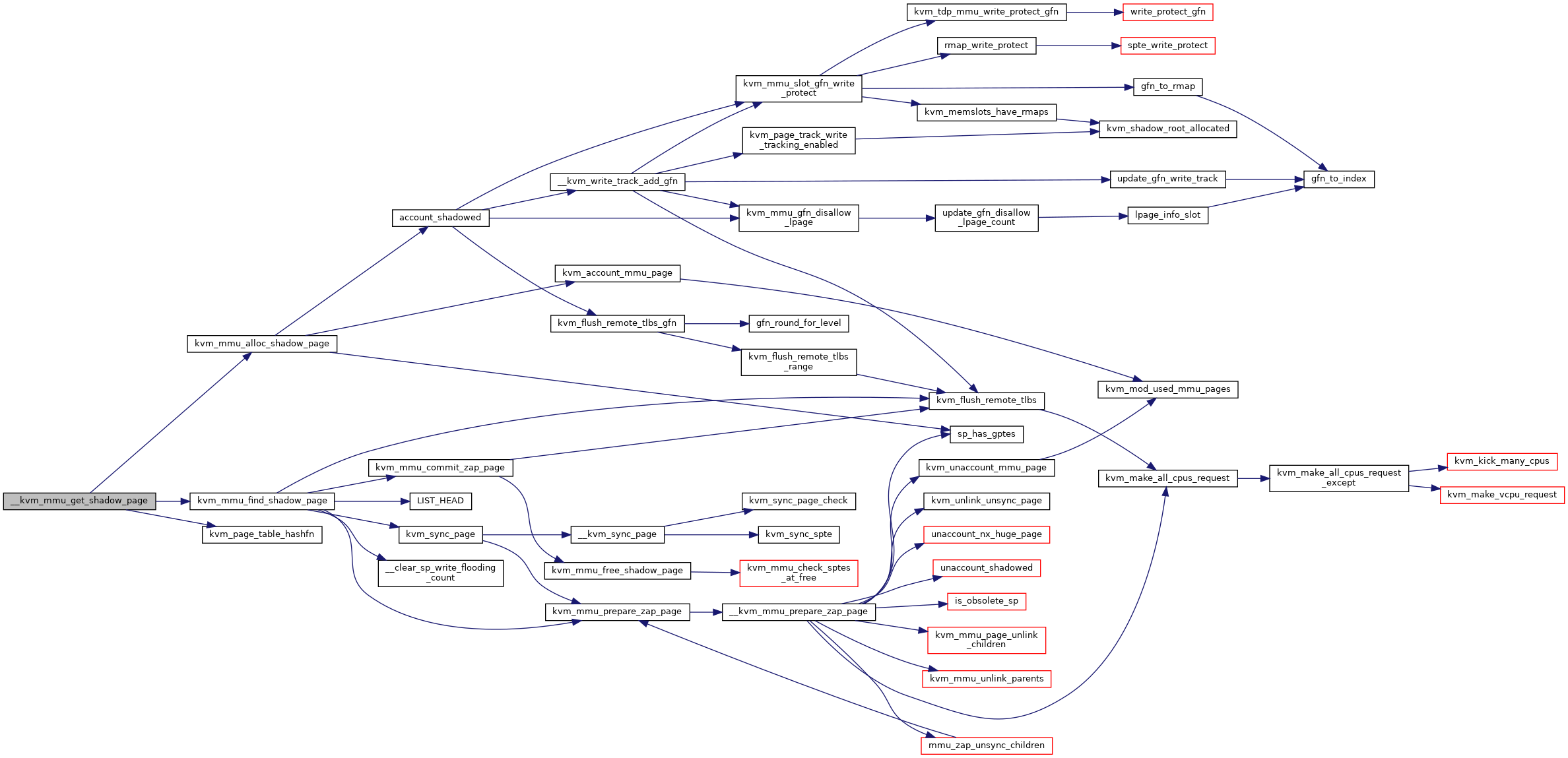
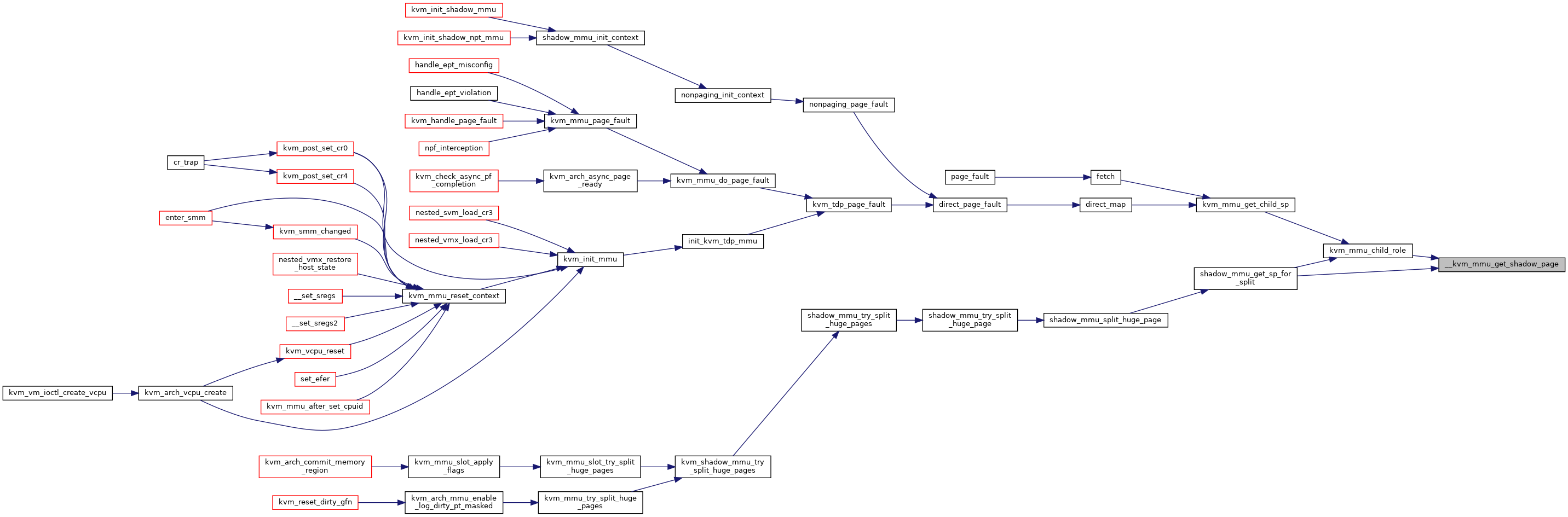
◆ __kvm_mmu_get_shadow_page()
|
static |
Definition at line 2272 of file mmu.c.
◆ __kvm_mmu_honors_guest_mtrrs()
| bool __kvm_mmu_honors_guest_mtrrs | ( | bool | vm_has_noncoherent_dma | ) |
◆ __kvm_mmu_invalidate_addr()
|
static |
Definition at line 5902 of file mmu.c.
◆ __kvm_mmu_max_mapping_level()
|
static |
Definition at line 3146 of file mmu.c.

◆ __kvm_mmu_prepare_zap_page()
|
static |
Definition at line 2569 of file mmu.c.
◆ __kvm_mmu_refresh_passthrough_bits()
| void __kvm_mmu_refresh_passthrough_bits | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_mmu * | mmu | ||
| ) |
Definition at line 5284 of file mmu.c.


◆ __kvm_sync_page()
|
static |
Definition at line 1959 of file mmu.c.

◆ __kvm_zap_rmap()
|
static |
Definition at line 1444 of file mmu.c.
◆ __link_shadow_page()
|
static |
Definition at line 2429 of file mmu.c.
◆ __mmu_unsync_walk()
|
static |
Definition at line 1832 of file mmu.c.
◆ __MODULE_PARM_TYPE() [1/3]
| __MODULE_PARM_TYPE | ( | nx_huge_pages | , |
| "bool" | |||
| ) |
◆ __MODULE_PARM_TYPE() [2/3]
| __MODULE_PARM_TYPE | ( | nx_huge_pages_recovery_period_ms | , |
| "uint" | |||
| ) |
◆ __MODULE_PARM_TYPE() [3/3]
| __MODULE_PARM_TYPE | ( | nx_huge_pages_recovery_ratio | , |
| "uint" | |||
| ) |
◆ __reset_rsvds_bits_mask()
|
static |
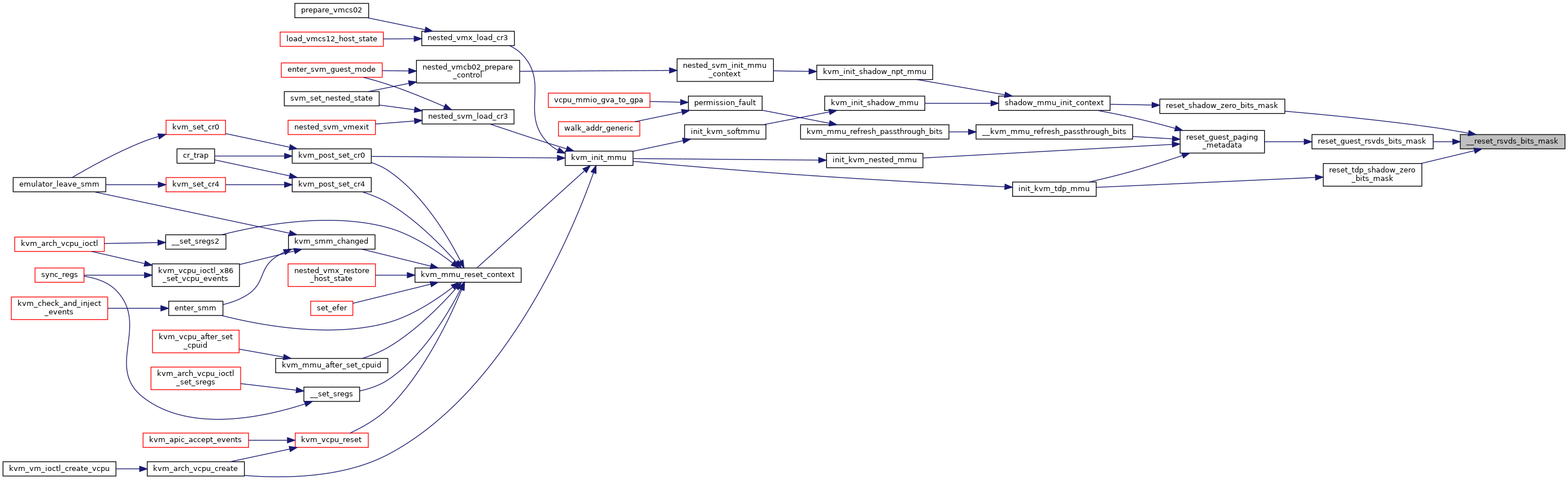
◆ __reset_rsvds_bits_mask_ept()
|
static |

◆ __rmap_add()
|
static |
Definition at line 1641 of file mmu.c.
◆ __rmap_clear_dirty()
|
static |
Definition at line 1282 of file mmu.c.

◆ __set_nx_huge_pages()
|
static |

◆ __set_spte()
|
static |
◆ __shadow_walk_next()
|
static |


◆ __update_clear_spte_fast()
|
static |

◆ __update_clear_spte_slow()
|
static |

◆ __walk_slot_rmaps()
|
static |
Definition at line 6043 of file mmu.c.

◆ account_nx_huge_page()
|
static |

◆ account_shadowed()
|
static |
Definition at line 827 of file mmu.c.
◆ alloc_apf_token()
|
static |
◆ boot_cpu_is_amd()
|
inlinestatic |
◆ BUILD_MMU_ROLE_ACCESSOR() [1/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | base | , |
| cr0 | , | ||
| wp | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [2/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | base | , |
| efer | , | ||
| nx | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [3/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| cr4 | , | ||
| la57 | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [4/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| cr4 | , | ||
| pke | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [5/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| cr4 | , | ||
| pse | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [6/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| cr4 | , | ||
| smap | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [7/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| cr4 | , | ||
| smep | |||
| ) |
◆ BUILD_MMU_ROLE_ACCESSOR() [8/8]
| BUILD_MMU_ROLE_ACCESSOR | ( | ext | , |
| efer | , | ||
| lma | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [1/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr0 | , |
| pg | , | ||
| X86_CR0_PG | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [2/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr0 | , |
| wp | , | ||
| X86_CR0_WP | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [3/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| la57 | , | ||
| X86_CR4_LA57 | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [4/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| pae | , | ||
| X86_CR4_PAE | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [5/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| pke | , | ||
| X86_CR4_PKE | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [6/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| pse | , | ||
| X86_CR4_PSE | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [7/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| smap | , | ||
| X86_CR4_SMAP | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [8/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | cr4 | , |
| smep | , | ||
| X86_CR4_SMEP | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [9/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | efer | , |
| lma | , | ||
| EFER_LMA | |||
| ) |
◆ BUILD_MMU_ROLE_REGS_ACCESSOR() [10/10]
| BUILD_MMU_ROLE_REGS_ACCESSOR | ( | efer | , |
| nx | , | ||
| EFER_NX | |||
| ) |
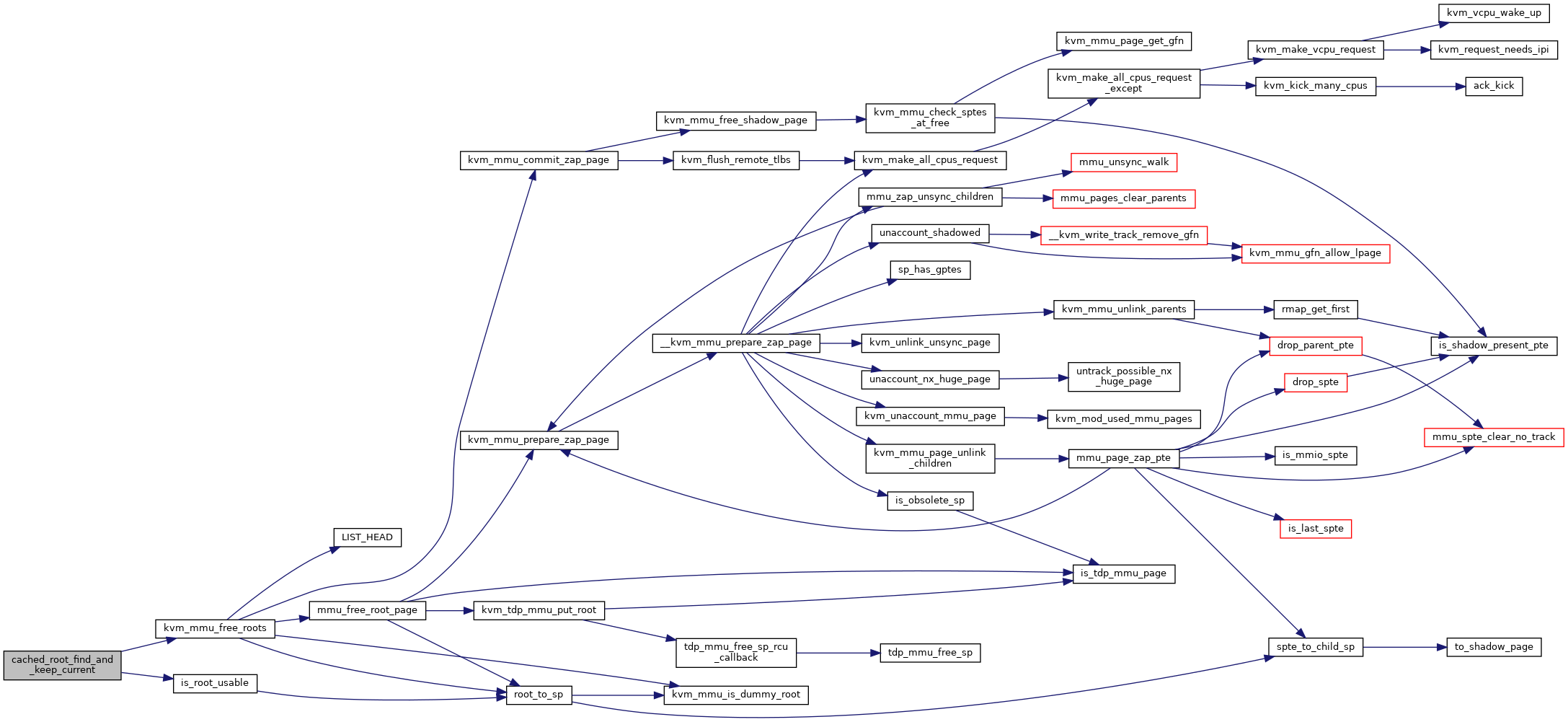
◆ cached_root_find_and_keep_current()
|
static |
Definition at line 4682 of file mmu.c.
◆ cached_root_find_without_current()
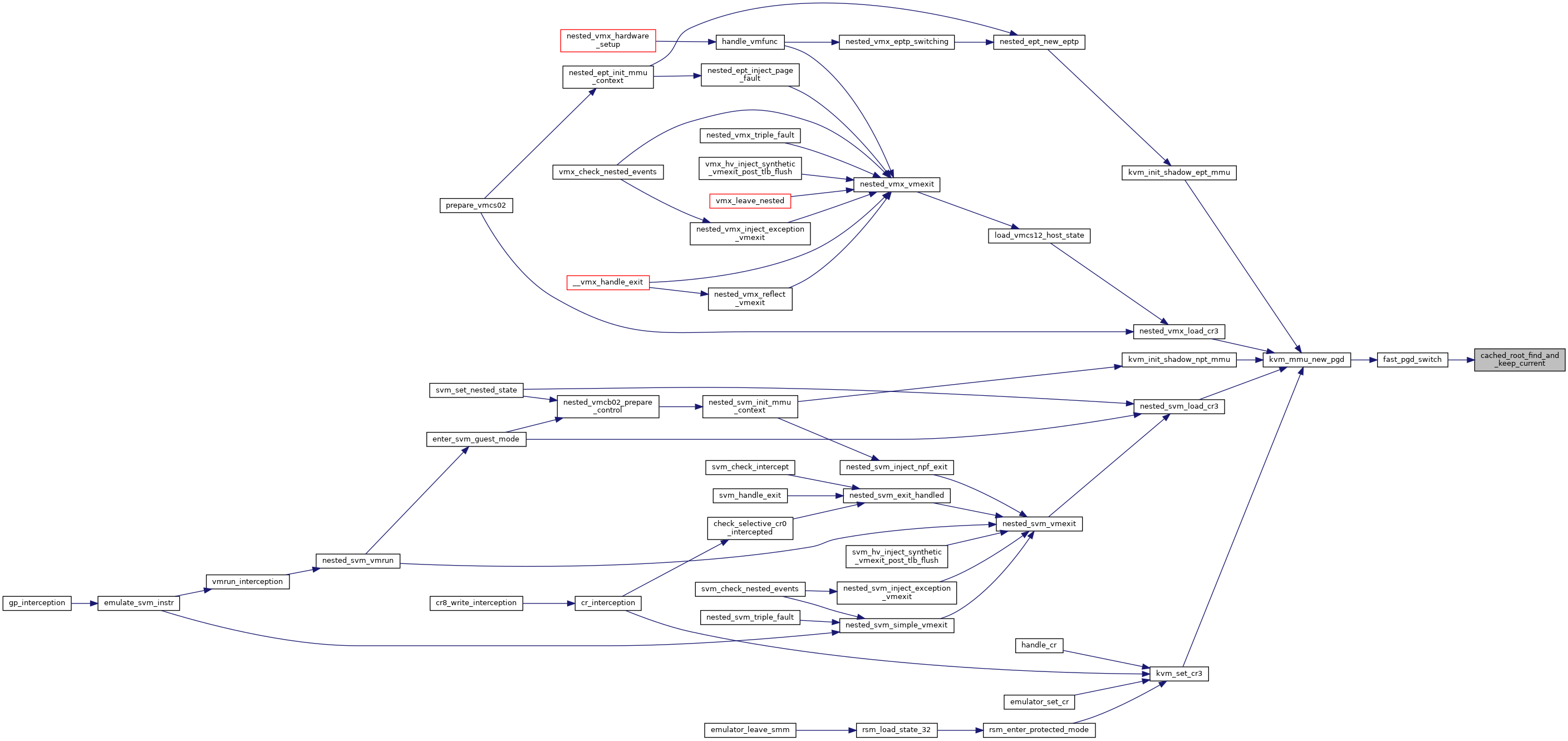
|
static |

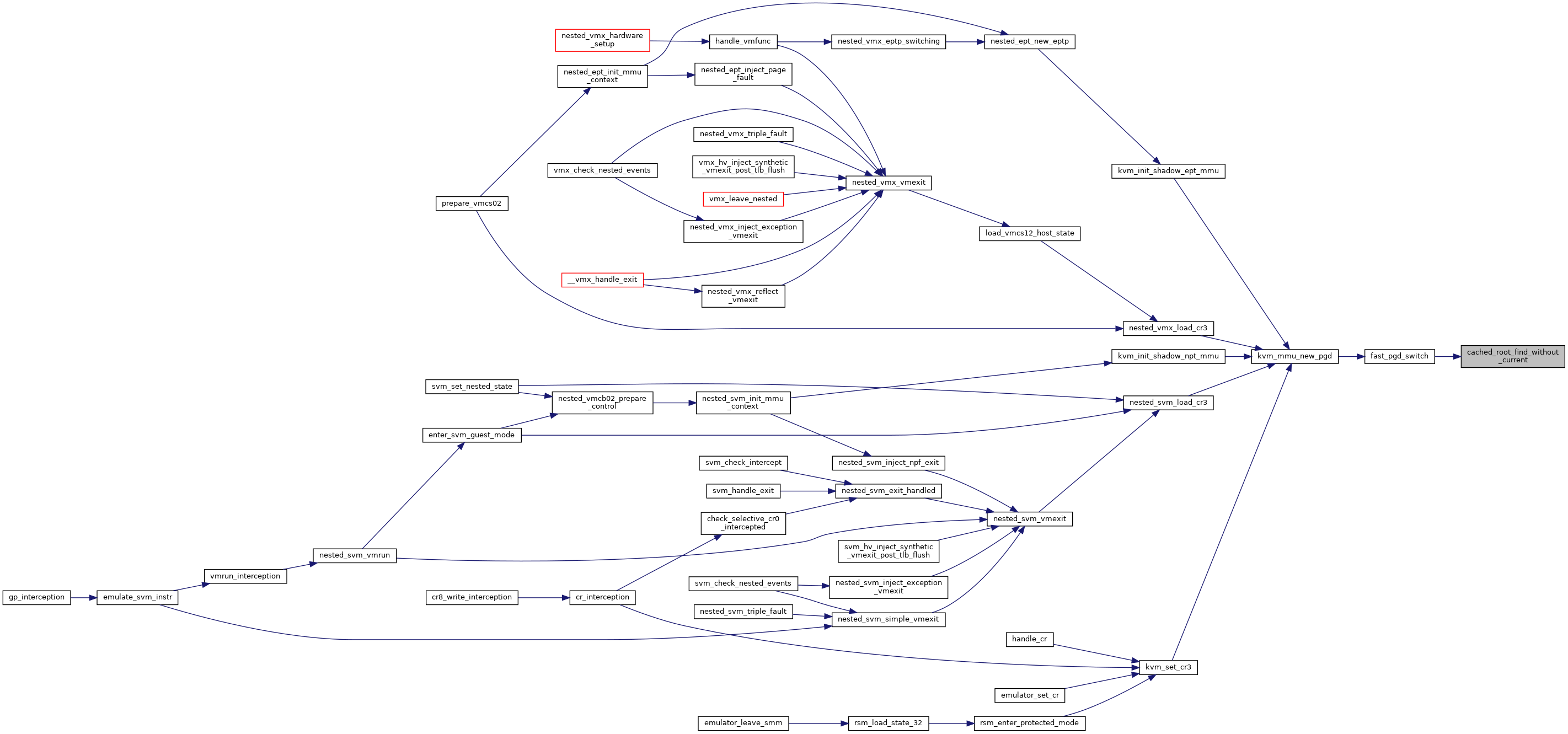
◆ calc_nx_huge_pages_recovery_period()
|
static |

◆ check_mmio_spte()
|
static |


◆ clear_sp_write_flooding_count()
|
static |
Definition at line 2140 of file mmu.c.


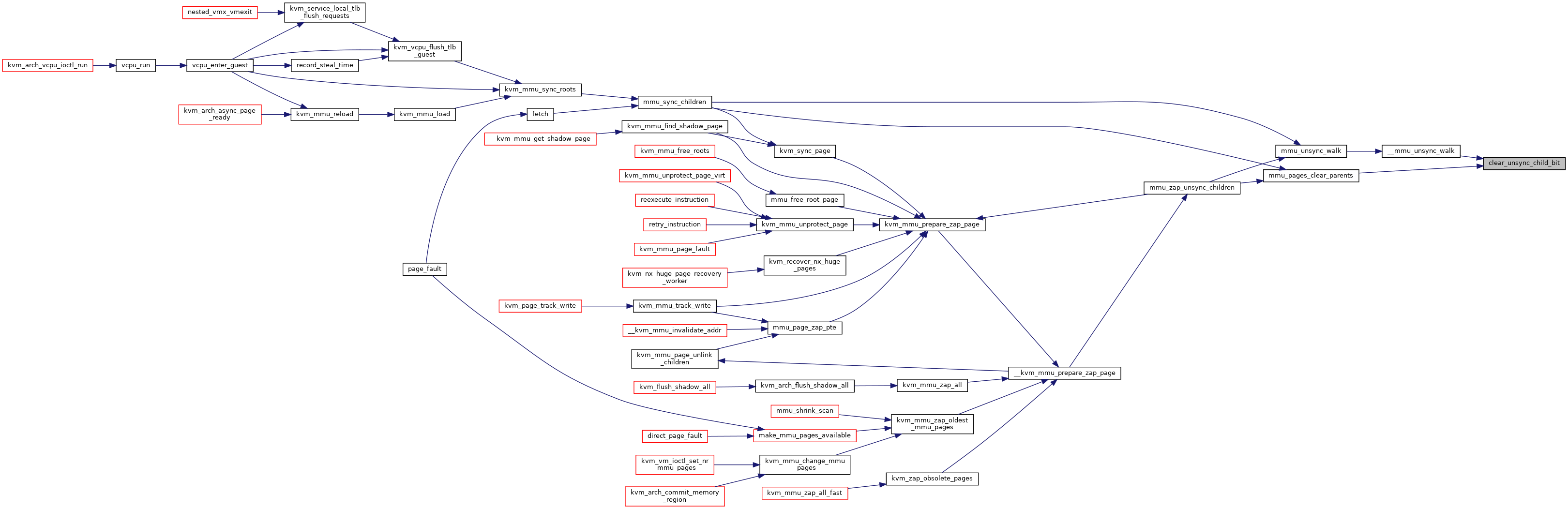
◆ clear_unsync_child_bit()
|
inlinestatic |
◆ count_spte_clear()
|
static |

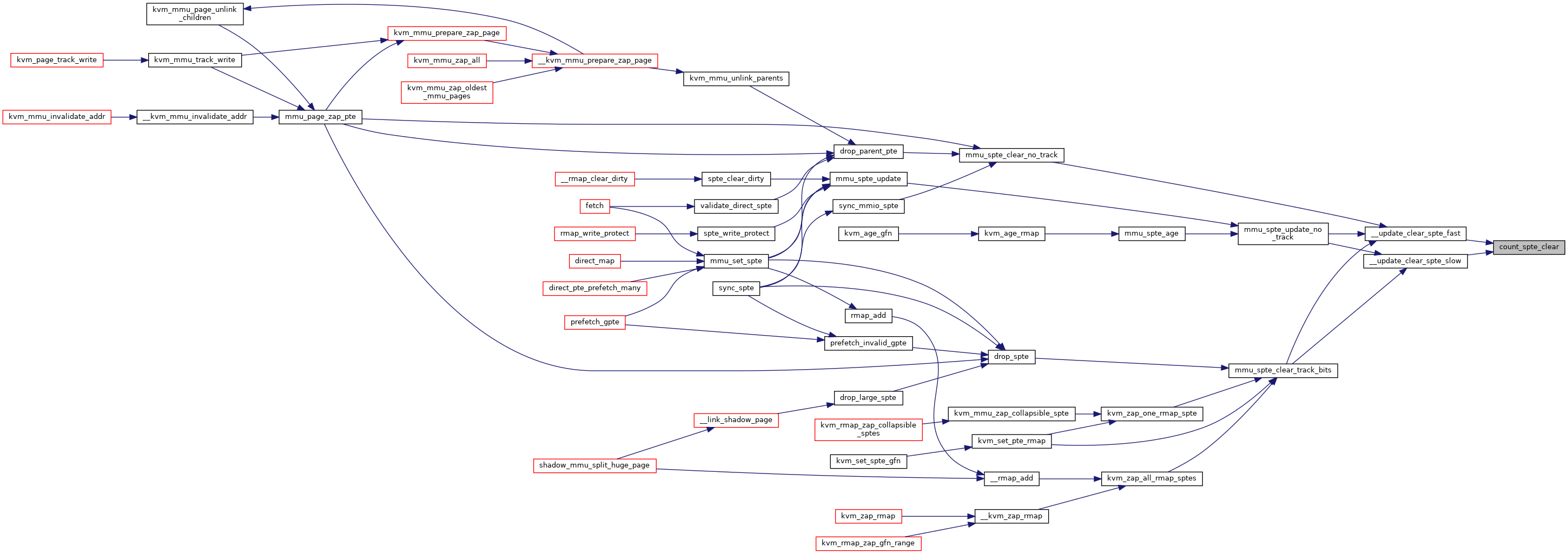
◆ detect_write_flooding()
|
static |

◆ detect_write_misaligned()
|
static |

◆ direct_map()
|
static |
Definition at line 3237 of file mmu.c.
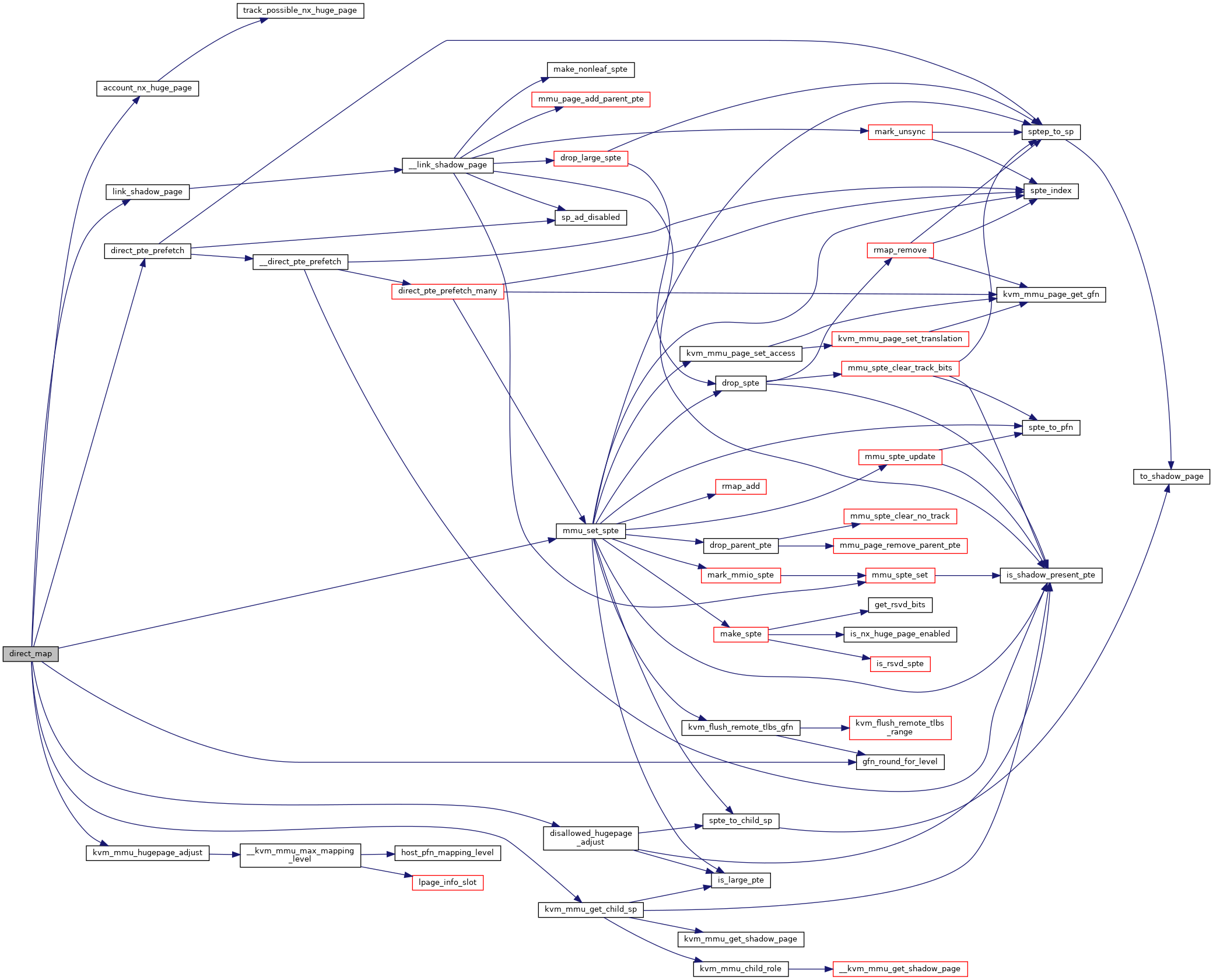
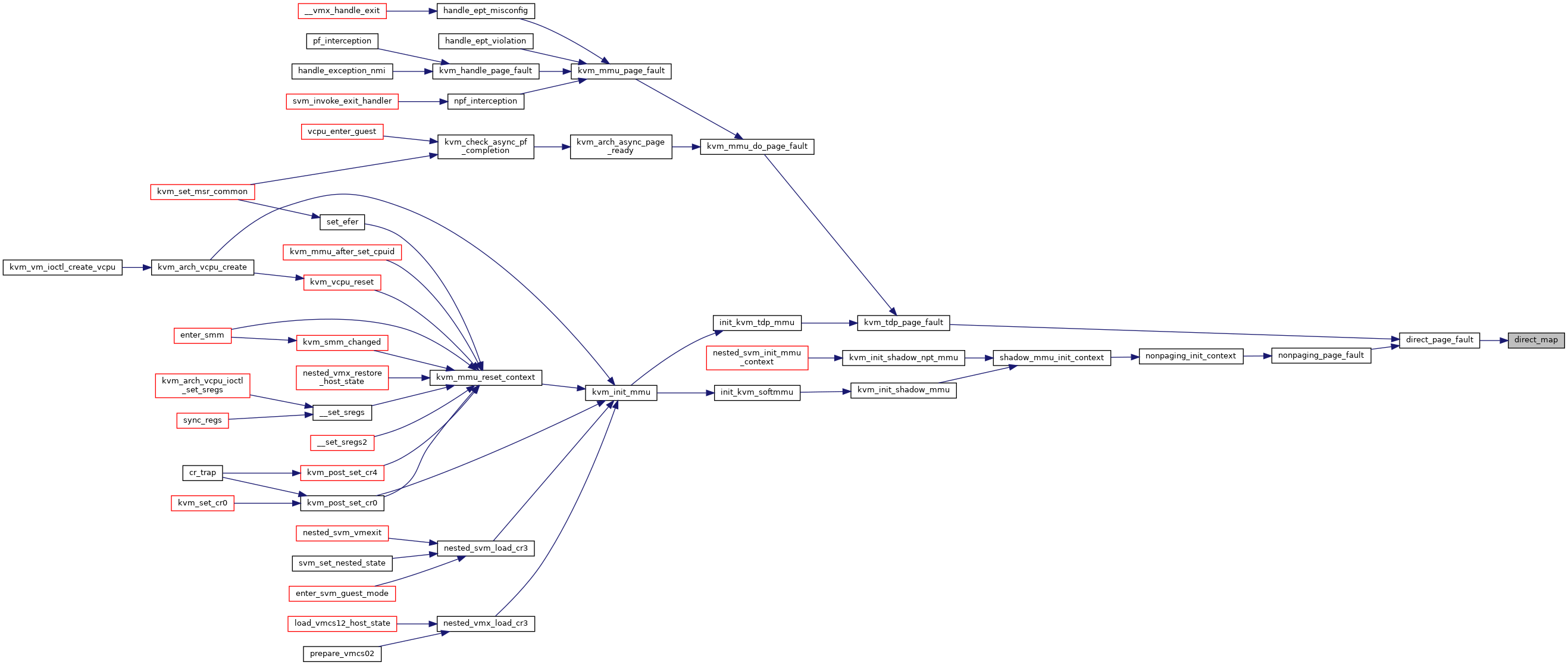
◆ direct_page_fault()
|
static |
Definition at line 4491 of file mmu.c.
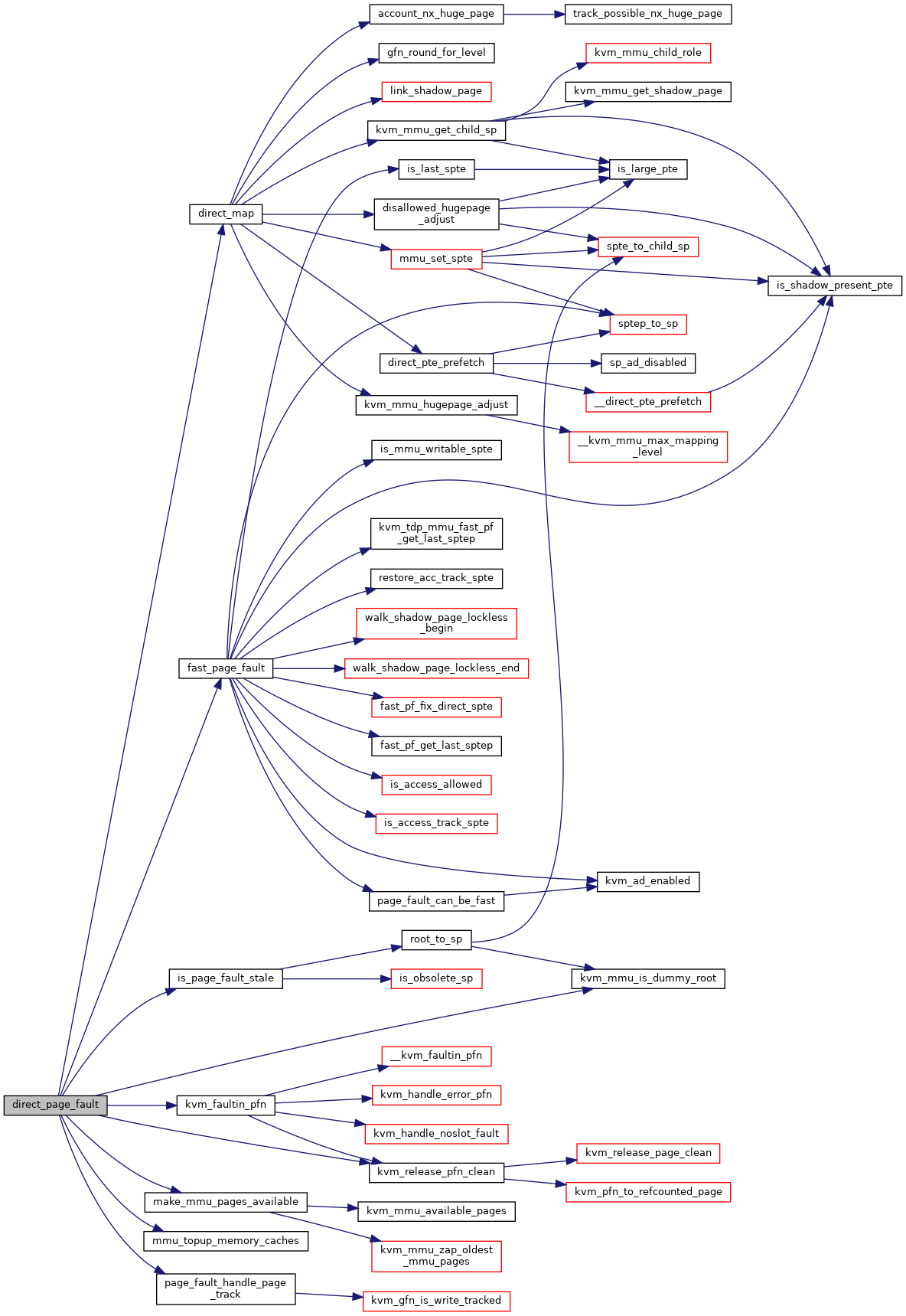
◆ direct_pte_prefetch()
|
static |
Definition at line 3030 of file mmu.c.
◆ direct_pte_prefetch_many()
|
static |
Definition at line 2977 of file mmu.c.
◆ disallowed_hugepage_adjust()
| void disallowed_hugepage_adjust | ( | struct kvm_page_fault * | fault, |
| u64 | spte, | ||
| int | cur_level | ||
| ) |
◆ drop_large_spte()
|
static |
◆ drop_parent_pte()
|
static |
Definition at line 1769 of file mmu.c.

◆ drop_spte()
|
static |
◆ EXPORT_SYMBOL_GPL() [1/12]
| EXPORT_SYMBOL_GPL | ( | kvm_configure_mmu | ) |
◆ EXPORT_SYMBOL_GPL() [2/12]
| EXPORT_SYMBOL_GPL | ( | kvm_handle_page_fault | ) |
◆ EXPORT_SYMBOL_GPL() [3/12]
| EXPORT_SYMBOL_GPL | ( | kvm_init_mmu | ) |
◆ EXPORT_SYMBOL_GPL() [4/12]
| EXPORT_SYMBOL_GPL | ( | kvm_init_shadow_ept_mmu | ) |
◆ EXPORT_SYMBOL_GPL() [5/12]
| EXPORT_SYMBOL_GPL | ( | kvm_init_shadow_npt_mmu | ) |
◆ EXPORT_SYMBOL_GPL() [6/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_free_guest_mode_roots | ) |
◆ EXPORT_SYMBOL_GPL() [7/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_free_roots | ) |
◆ EXPORT_SYMBOL_GPL() [8/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_invalidate_addr | ) |
◆ EXPORT_SYMBOL_GPL() [9/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_invlpg | ) |
◆ EXPORT_SYMBOL_GPL() [10/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_new_pgd | ) |
◆ EXPORT_SYMBOL_GPL() [11/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_page_fault | ) |
◆ EXPORT_SYMBOL_GPL() [12/12]
| EXPORT_SYMBOL_GPL | ( | kvm_mmu_reset_context | ) |
◆ fast_page_fault()
|
static |
Definition at line 3444 of file mmu.c.
◆ fast_pf_fix_direct_spte()
|
static |
Definition at line 3381 of file mmu.c.

◆ fast_pf_get_last_sptep()
|
static |
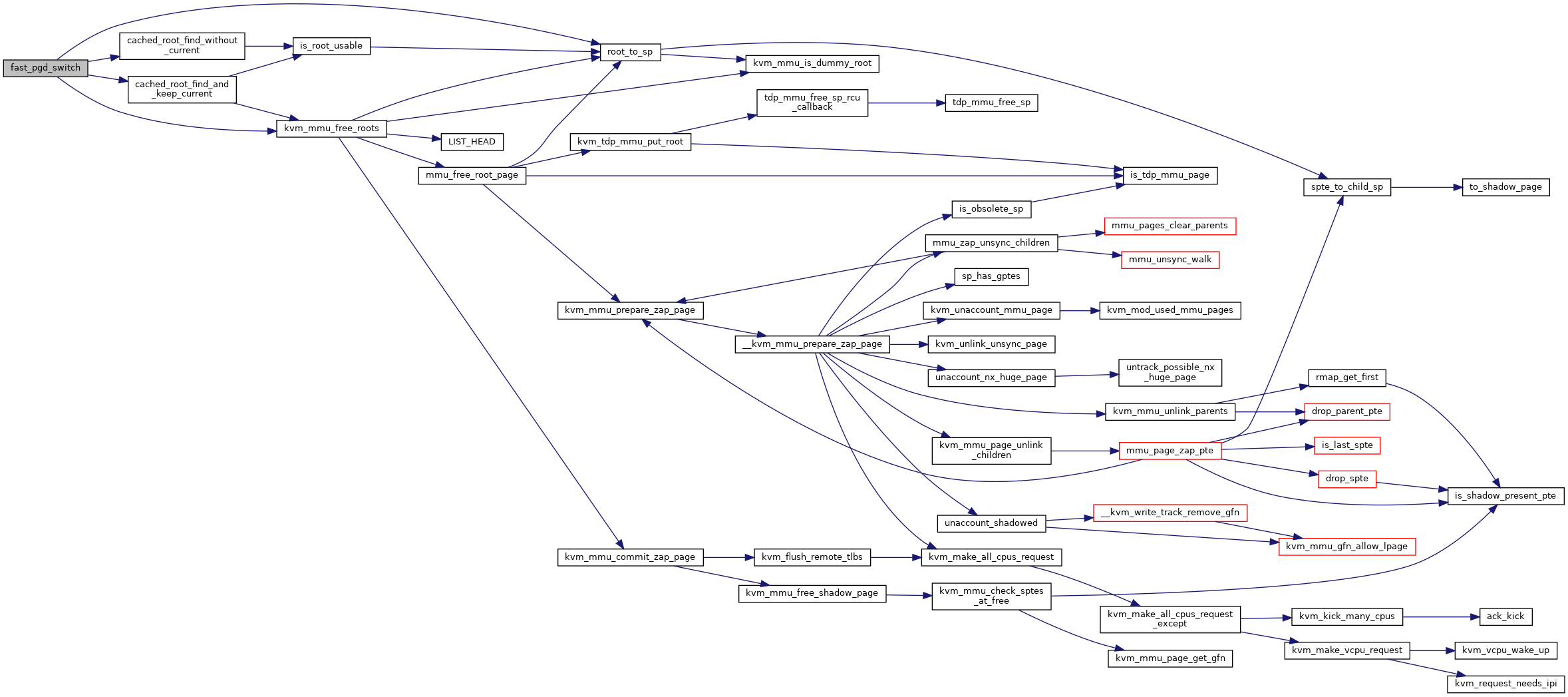
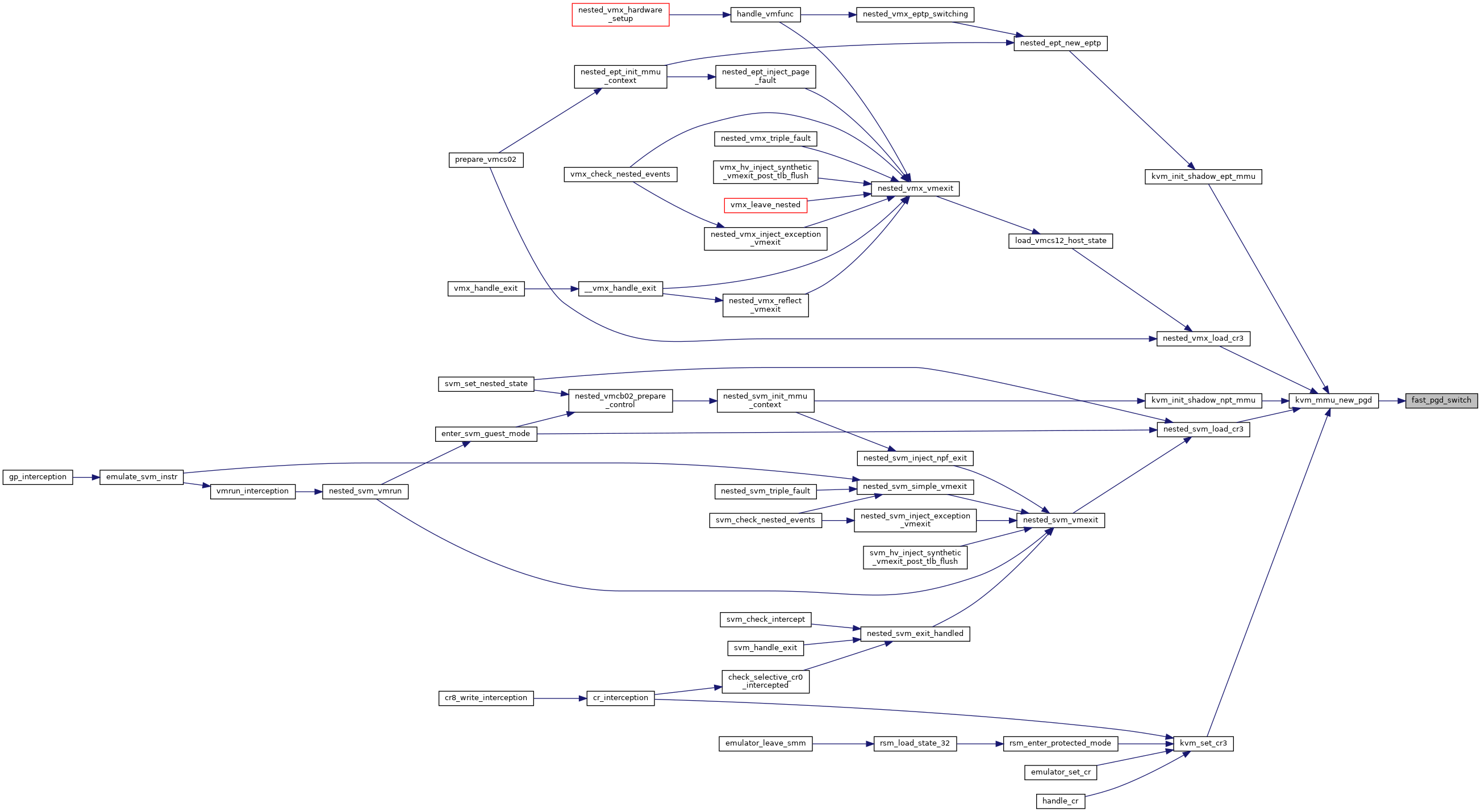
◆ fast_pgd_switch()
|
static |
Definition at line 4737 of file mmu.c.
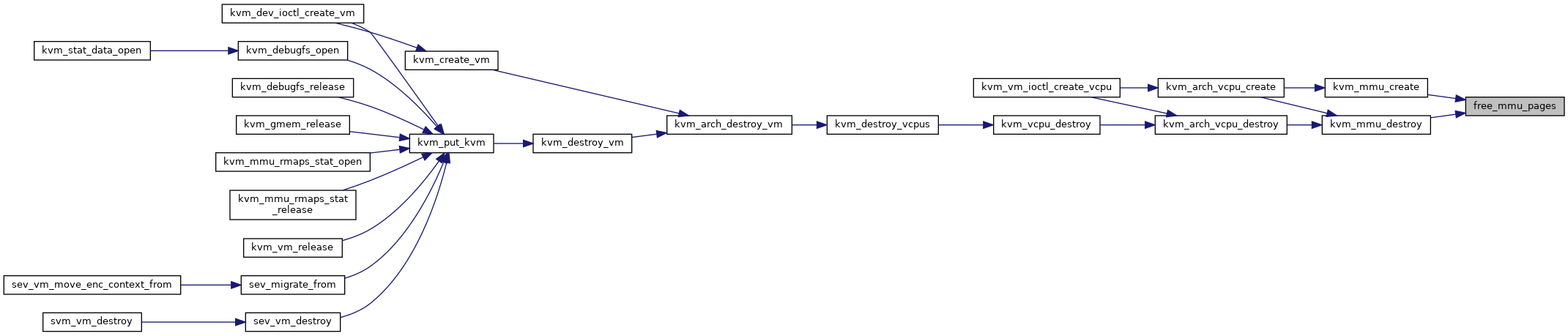
◆ free_mmu_pages()
|
static |
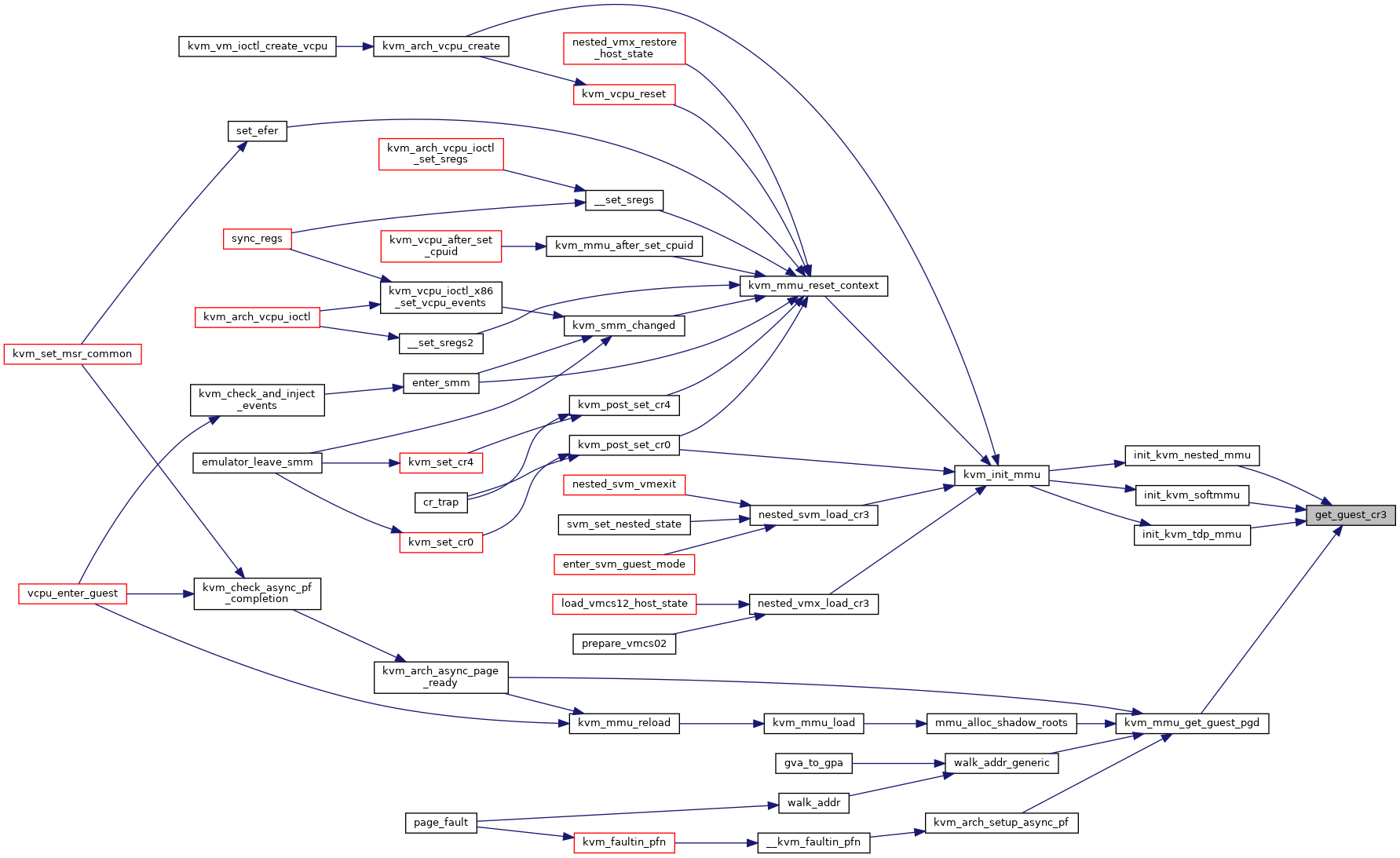
◆ get_guest_cr3()
|
static |

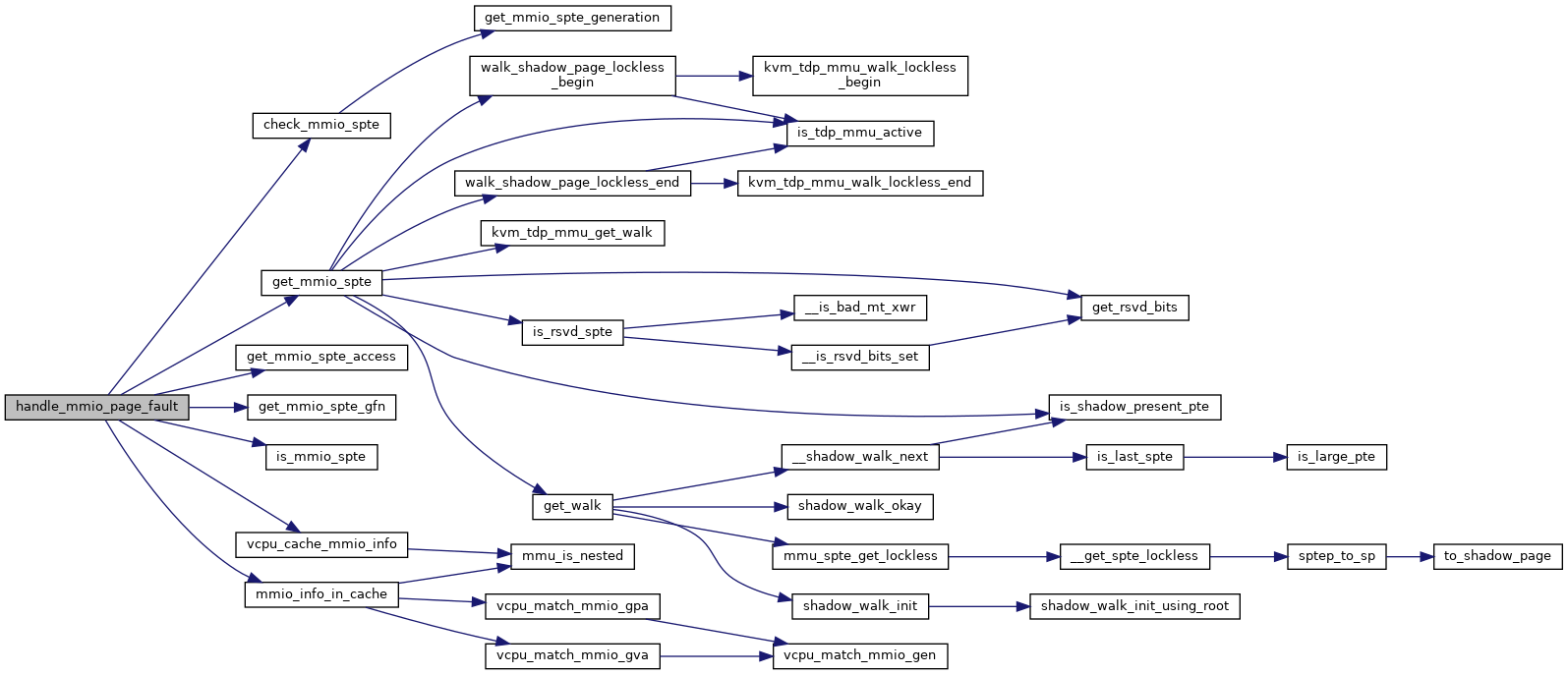
◆ get_mmio_spte()
|
static |
Definition at line 4125 of file mmu.c.

◆ get_mmio_spte_access()
|
static |

◆ get_mmio_spte_gfn()
|
static |

◆ get_nx_auto_mode()
|
static |

◆ get_nx_huge_page_recovery_timeout()
|
static |
Definition at line 7243 of file mmu.c.


◆ get_nx_huge_pages()
|
static |
◆ get_walk()
|
static |
Definition at line 4105 of file mmu.c.

◆ get_written_sptes()
|
static |

◆ gfn_to_memslot_dirty_bitmap()
|
static |
Definition at line 907 of file mmu.c.

◆ gfn_to_rmap()
|
static |

◆ handle_mmio_page_fault()
|
static |
Definition at line 4174 of file mmu.c.

◆ host_pfn_mapping_level()
|
static |
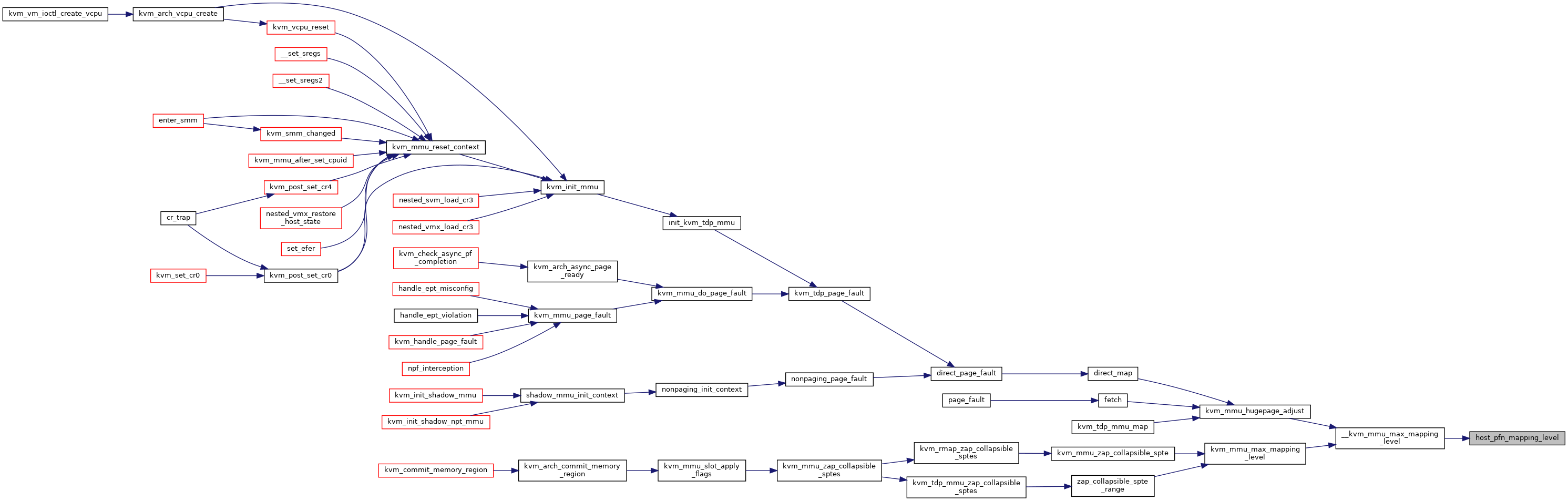
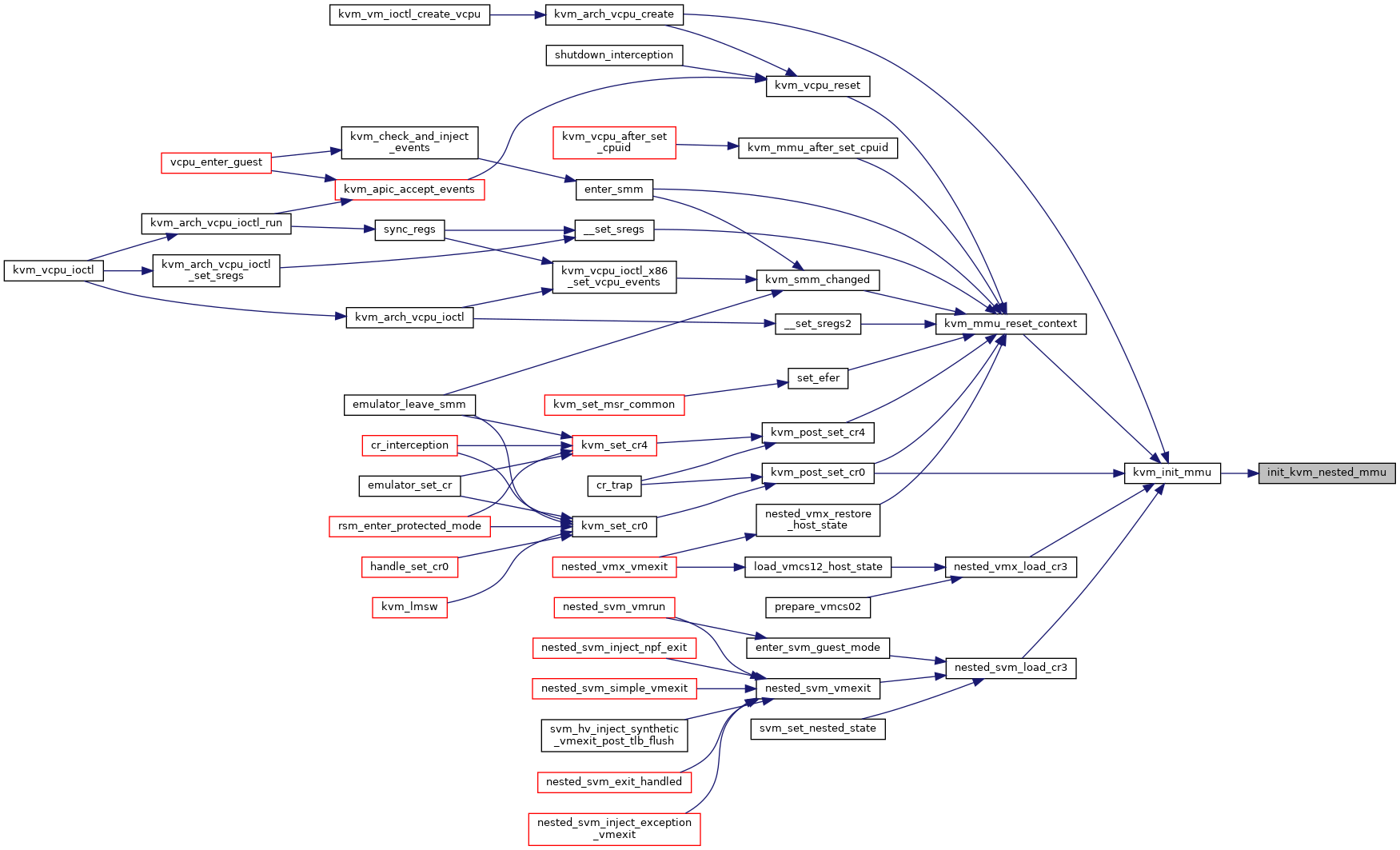
◆ init_kvm_nested_mmu()
|
static |
Definition at line 5499 of file mmu.c.
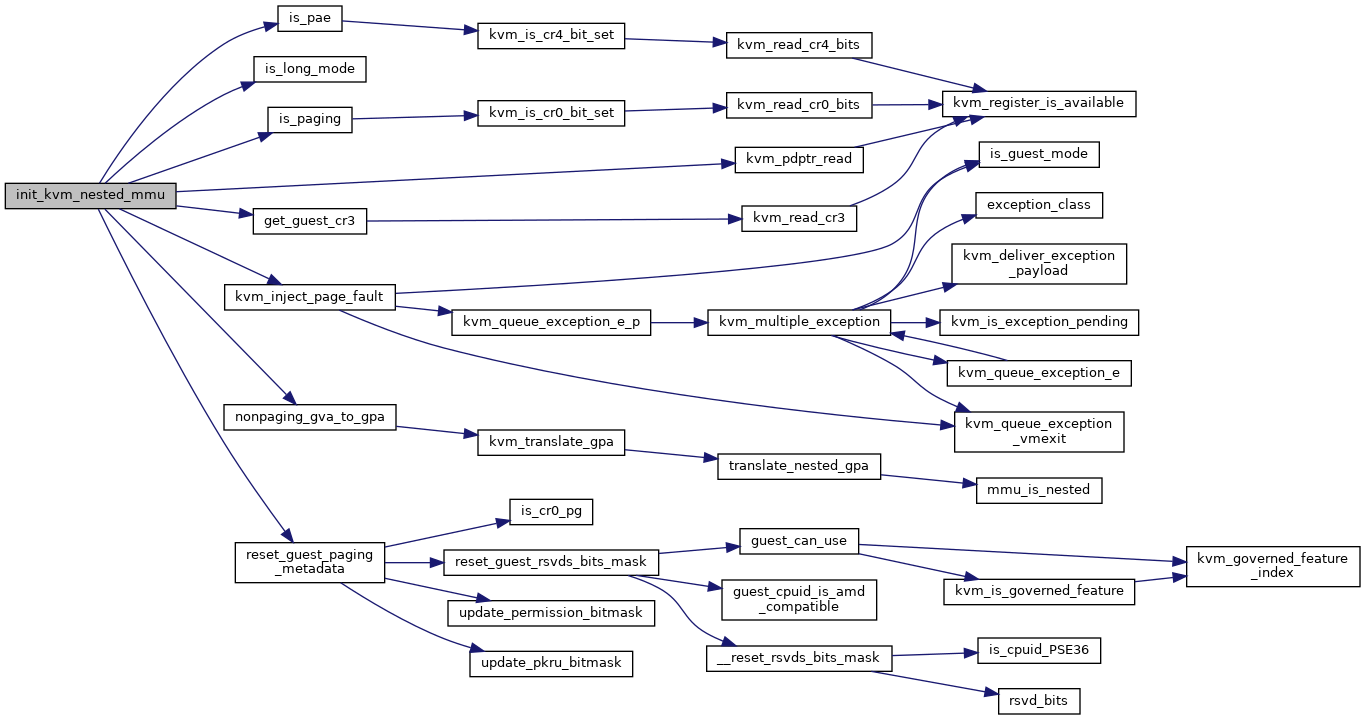
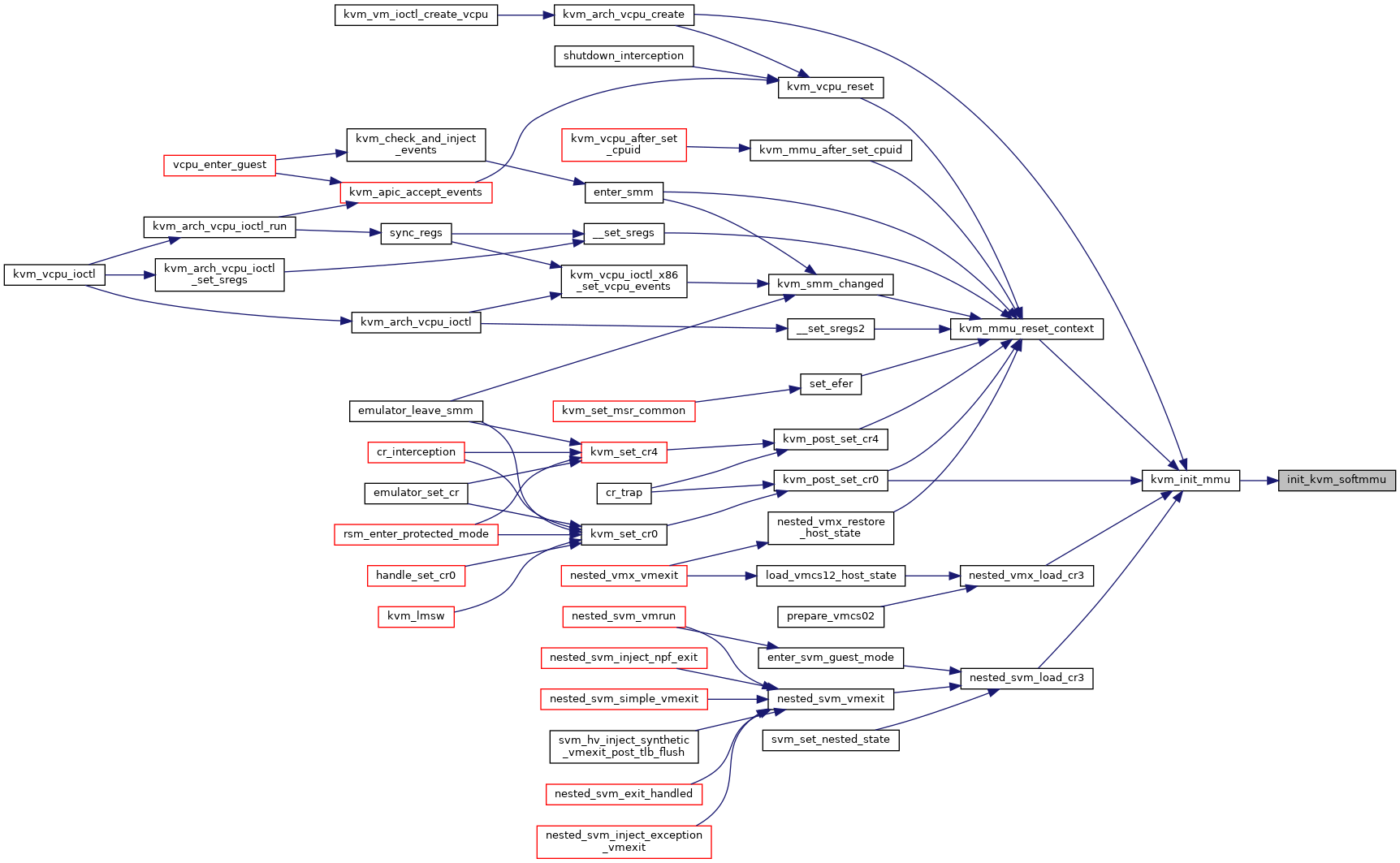
◆ init_kvm_softmmu()
|
static |
Definition at line 5487 of file mmu.c.
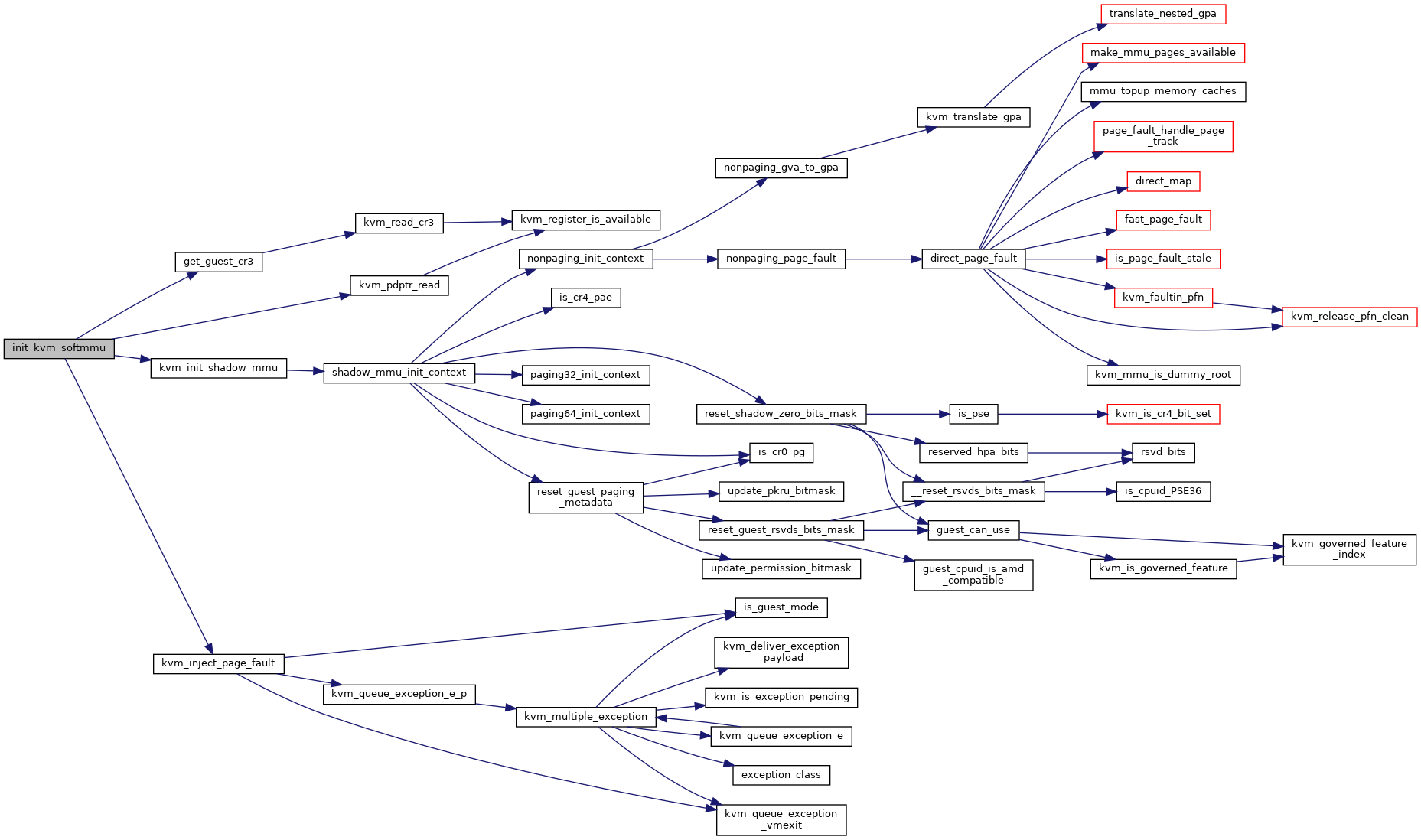
◆ init_kvm_tdp_mmu()
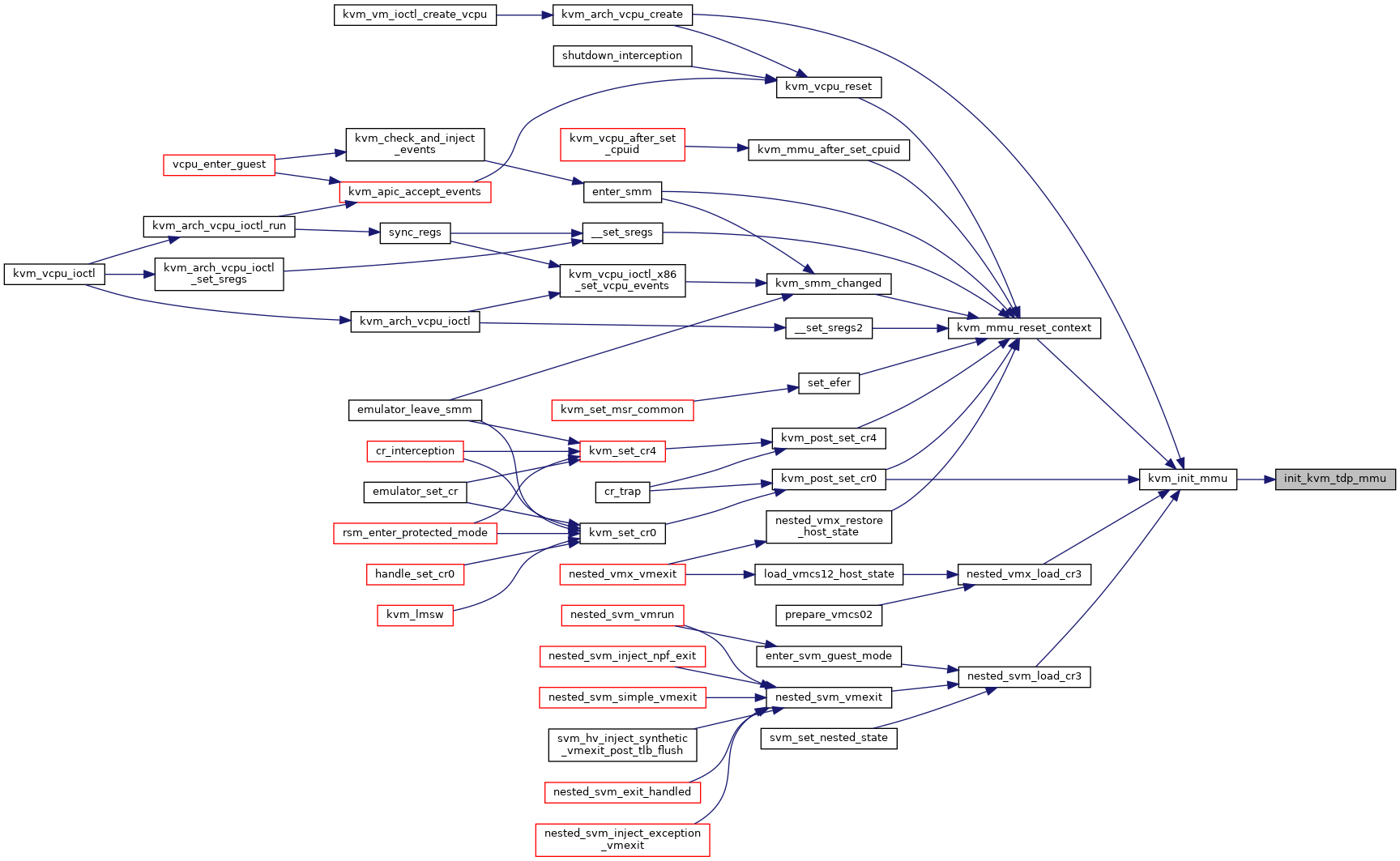
|
static |
Definition at line 5331 of file mmu.c.
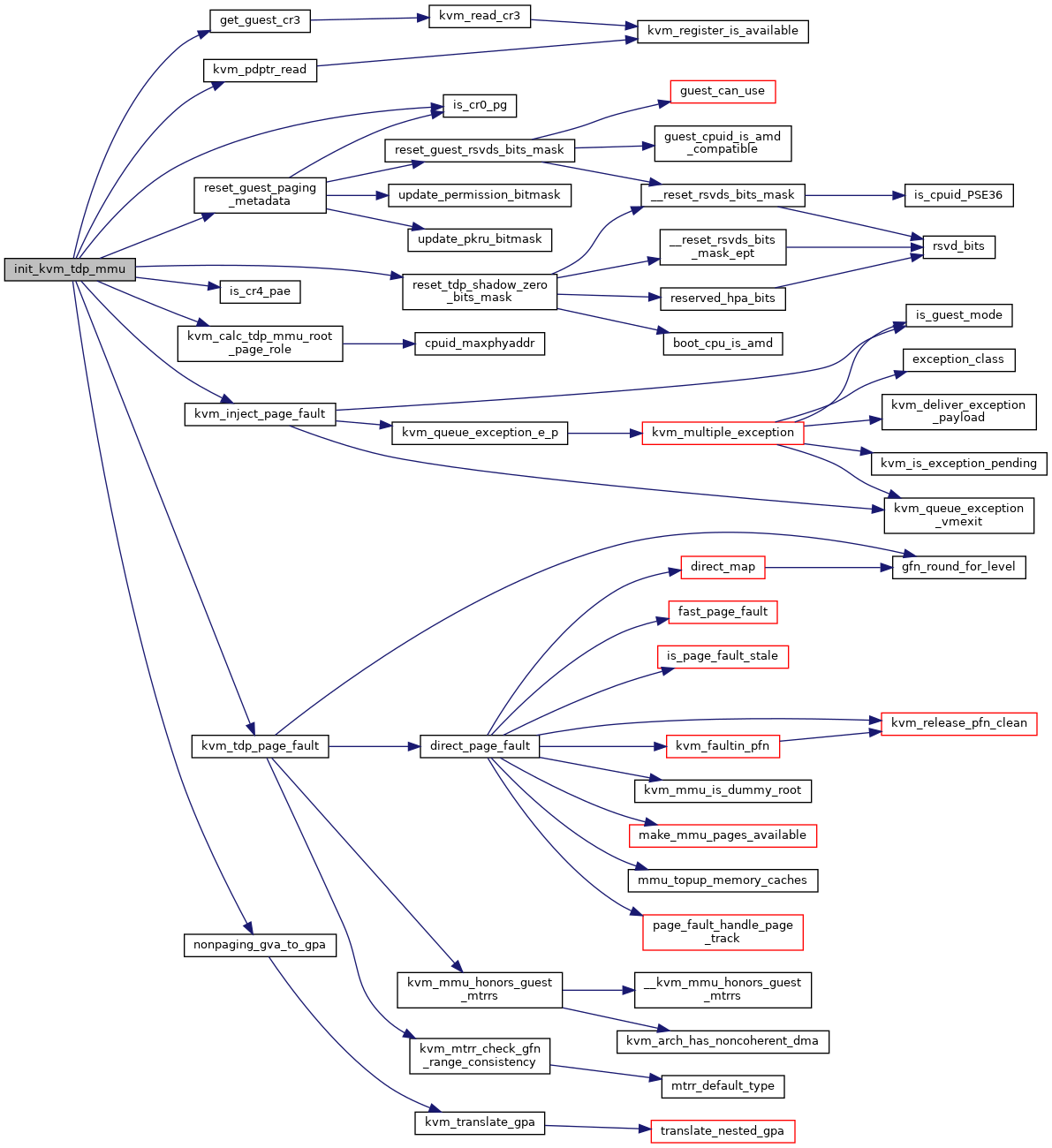
◆ is_access_allowed()
|
static |
◆ is_cpuid_PSE36()
|
static |
◆ is_cr0_pg()
|
inlinestatic |
◆ is_cr4_pae()
|
inlinestatic |
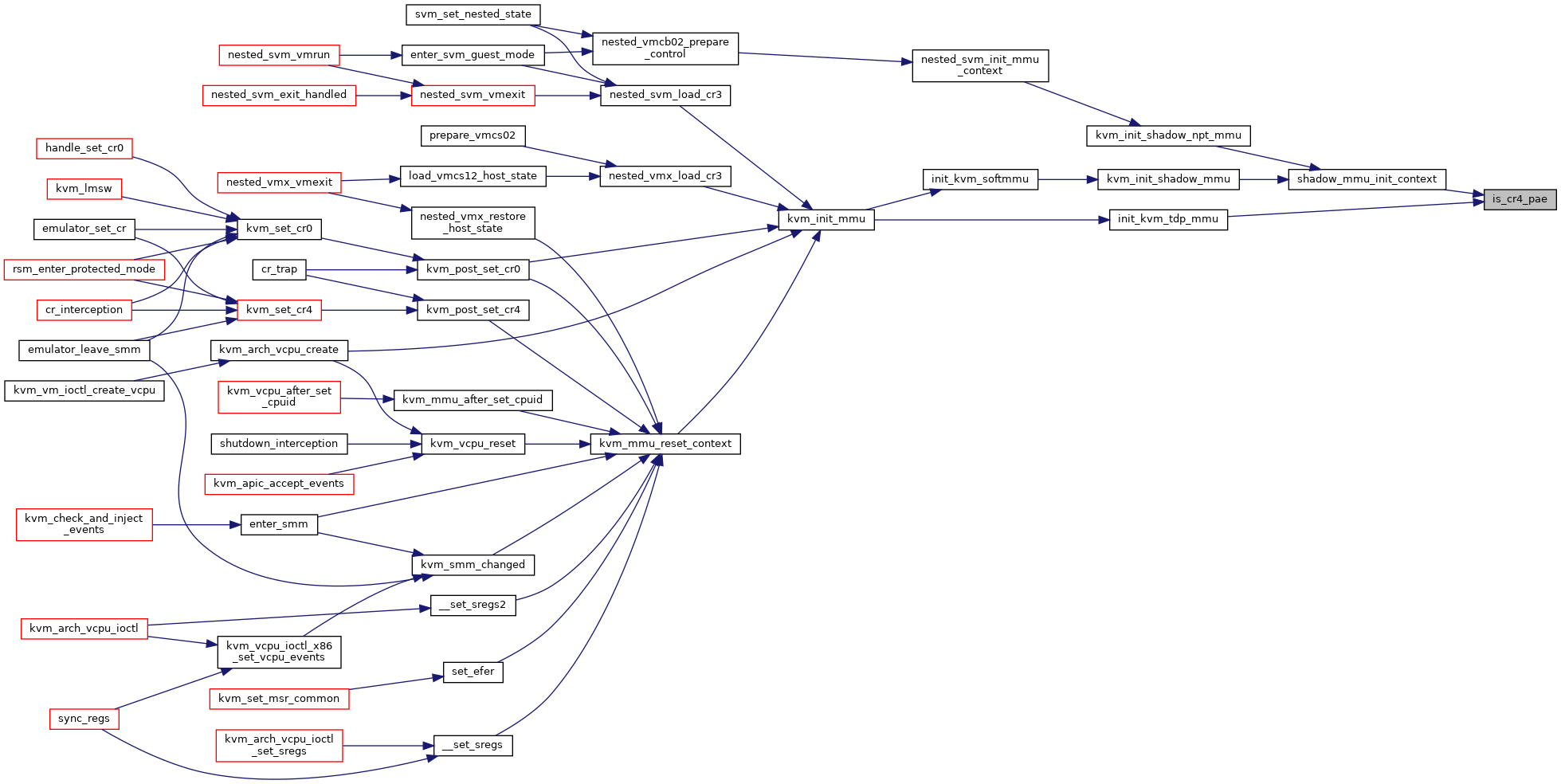
◆ is_obsolete_root()
|
static |


◆ is_obsolete_sp()
|
static |

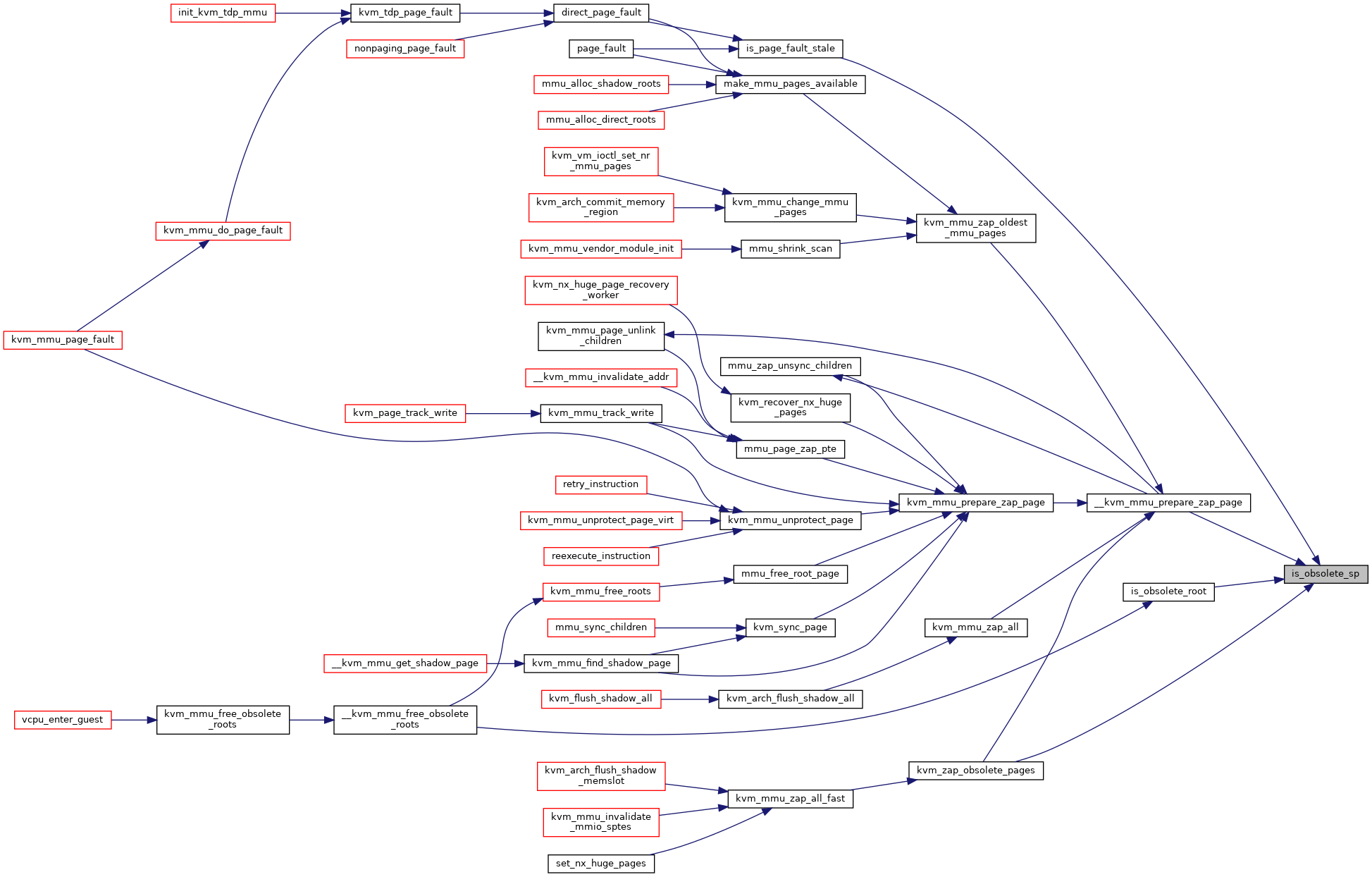
◆ is_page_fault_stale()
|
static |

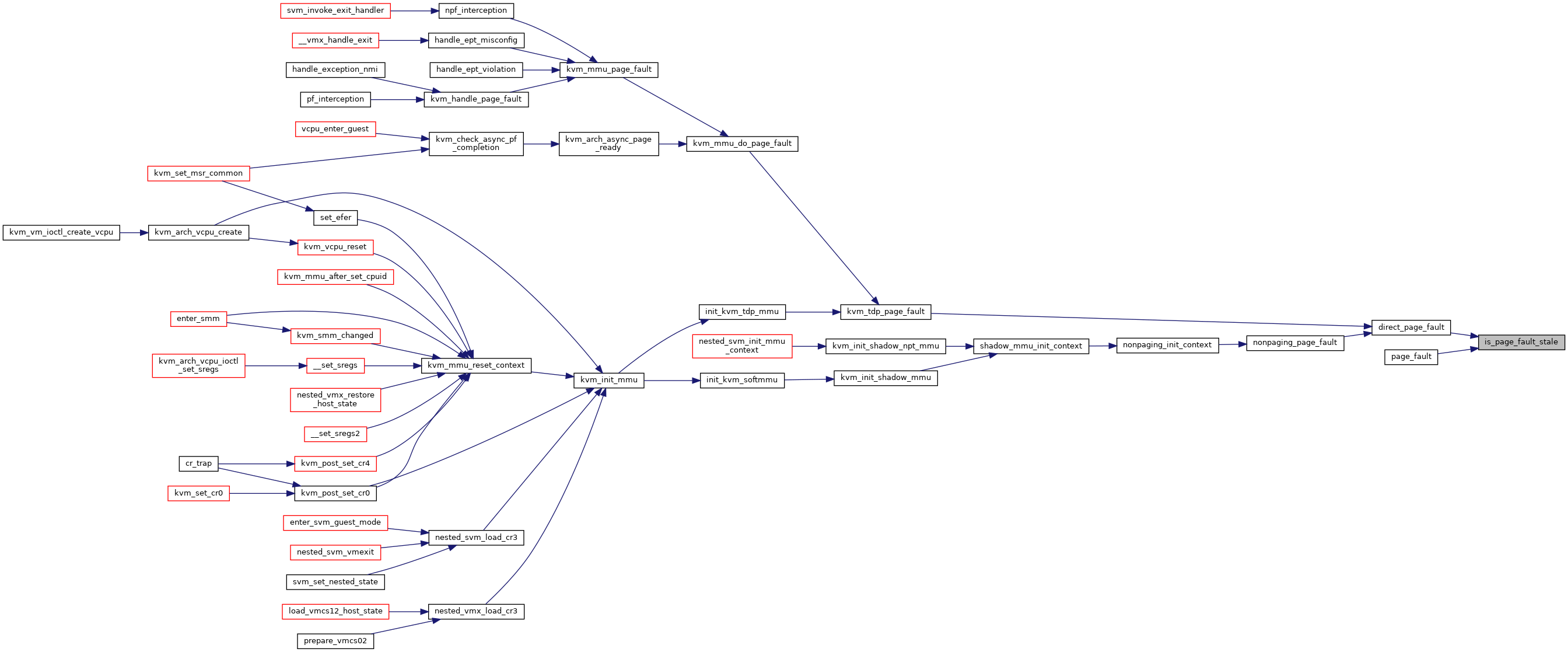
◆ is_root_usable()
|
inlinestatic |

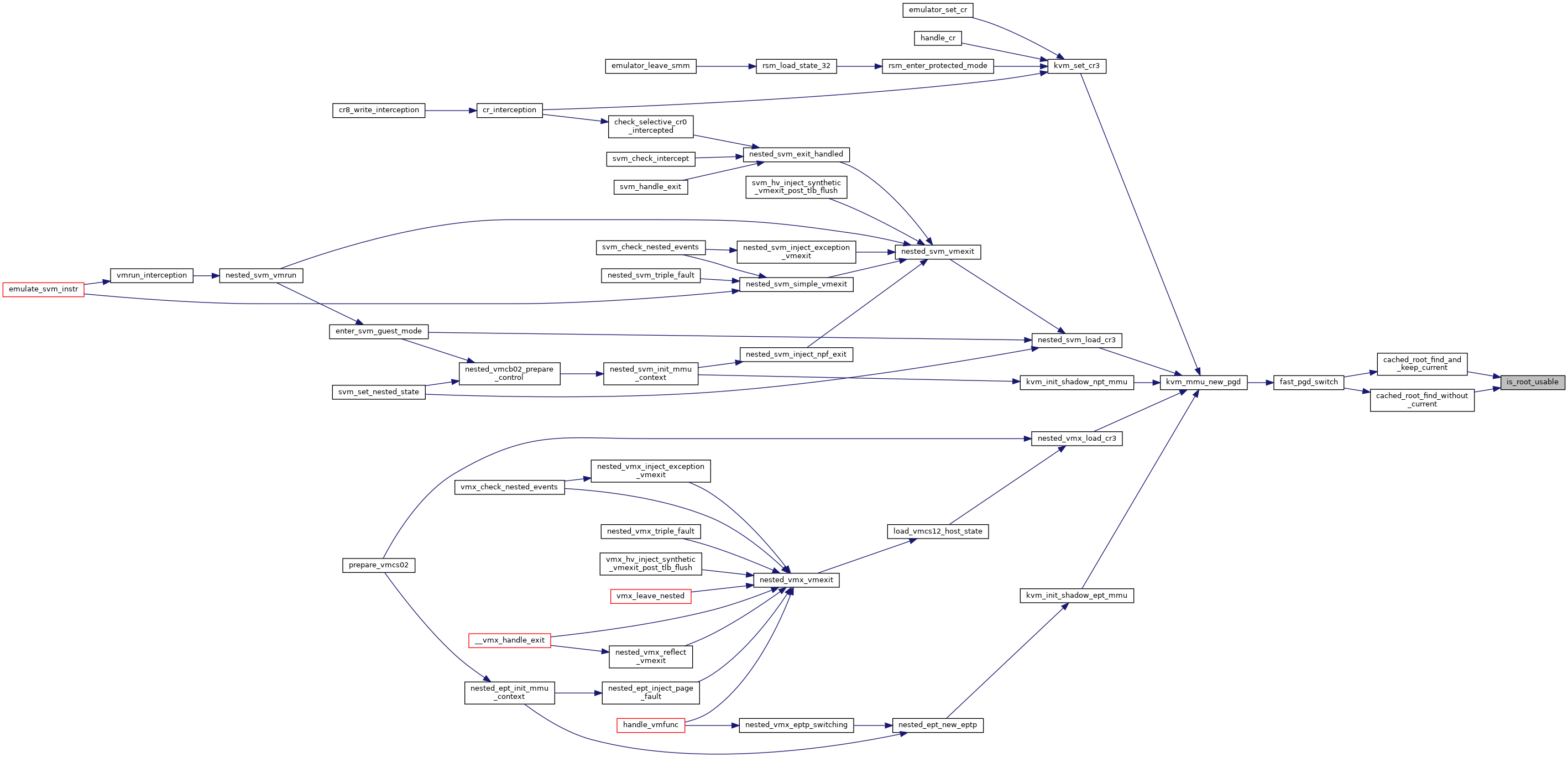
◆ is_tdp_mmu_active()
|
inlinestatic |
◆ is_unsync_root()
|
static |

◆ kvm_account_mmu_page()
|
static |
Definition at line 1725 of file mmu.c.

◆ kvm_age_gfn()
| bool kvm_age_gfn | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1673 of file mmu.c.
◆ kvm_age_rmap()
|
static |

◆ kvm_arch_async_page_ready()
| void kvm_arch_async_page_ready | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_async_pf * | work | ||
| ) |
Definition at line 4263 of file mmu.c.

◆ kvm_arch_flush_shadow_all()
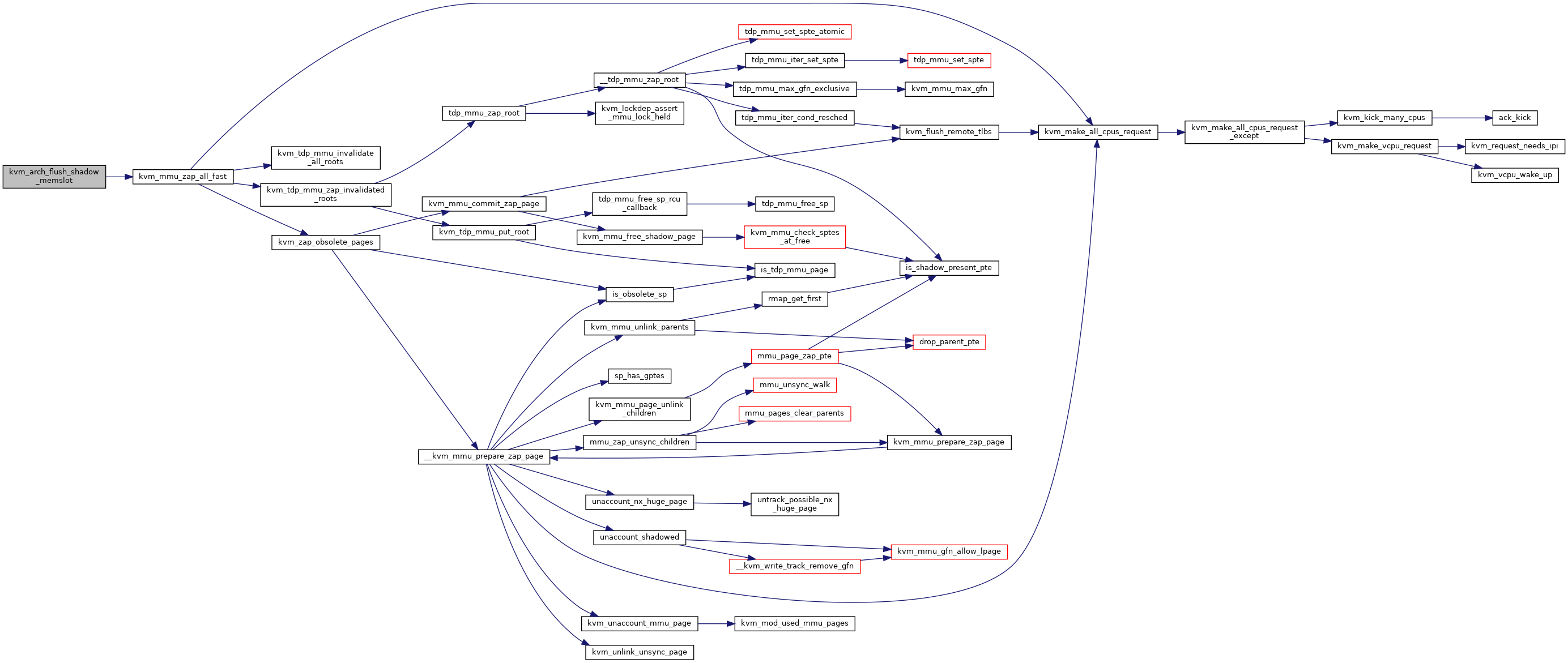
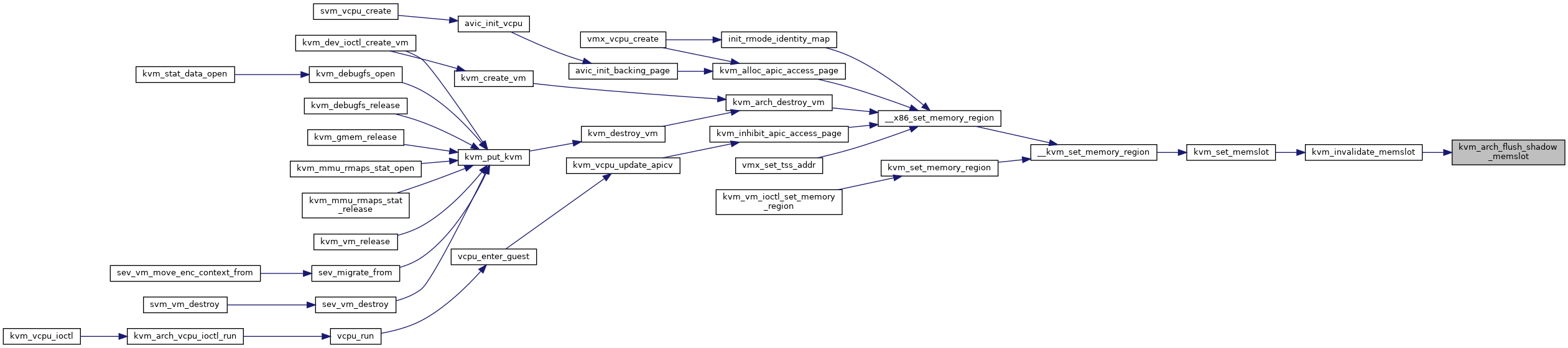
| void kvm_arch_flush_shadow_all | ( | struct kvm * | kvm | ) |
◆ kvm_arch_flush_shadow_memslot()
| void kvm_arch_flush_shadow_memslot | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot | ||
| ) |
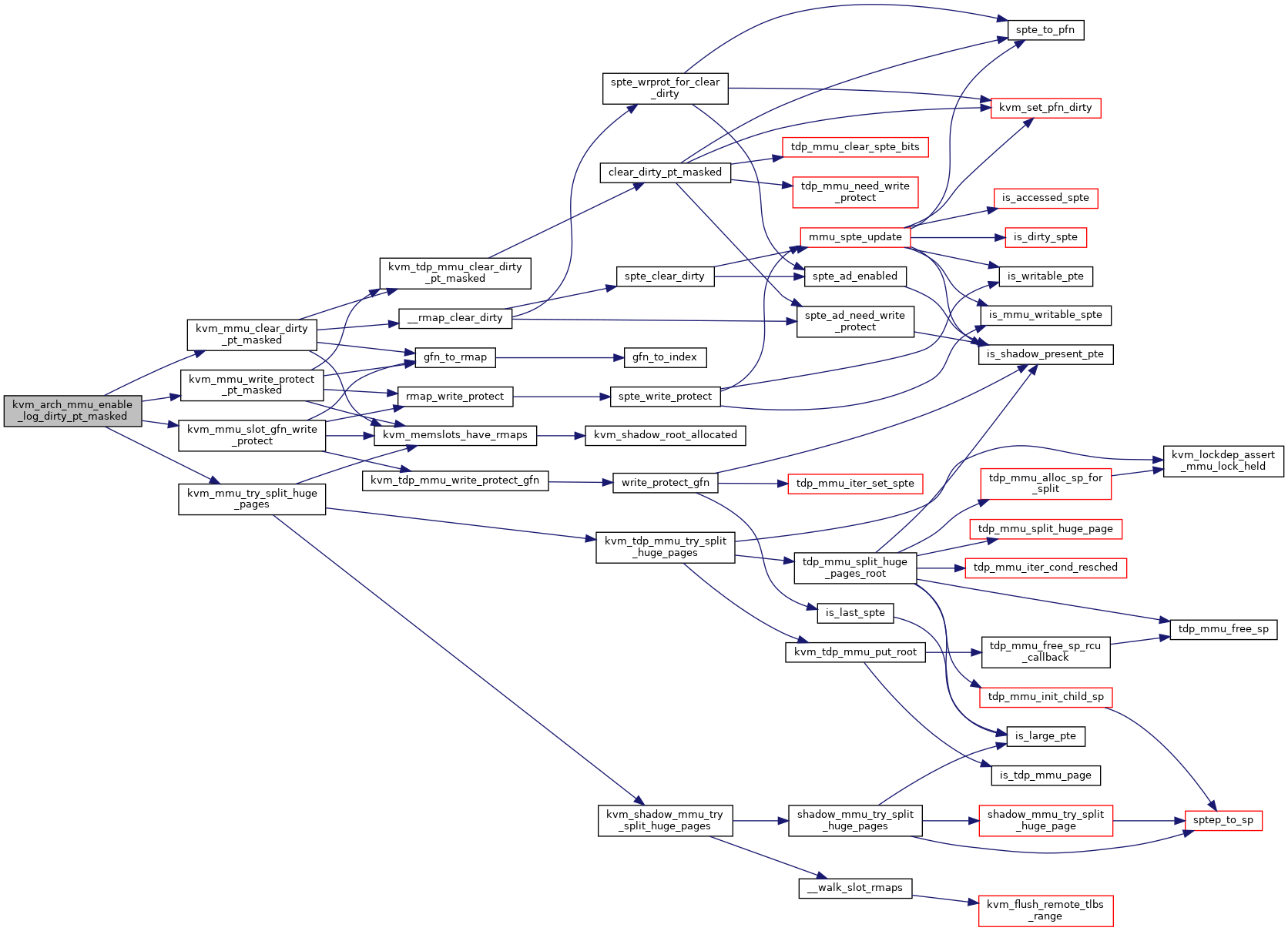
◆ kvm_arch_mmu_enable_log_dirty_pt_masked()
| void kvm_arch_mmu_enable_log_dirty_pt_masked | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn_offset, | ||
| unsigned long | mask | ||
| ) |
kvm_arch_mmu_enable_log_dirty_pt_masked - enable dirty logging for selected PT level pages.
It calls kvm_mmu_write_protect_pt_masked to write protect selected pages to enable dirty logging for them.
We need to care about huge page mappings: e.g. during dirty logging we may have such mappings.
Definition at line 1373 of file mmu.c.

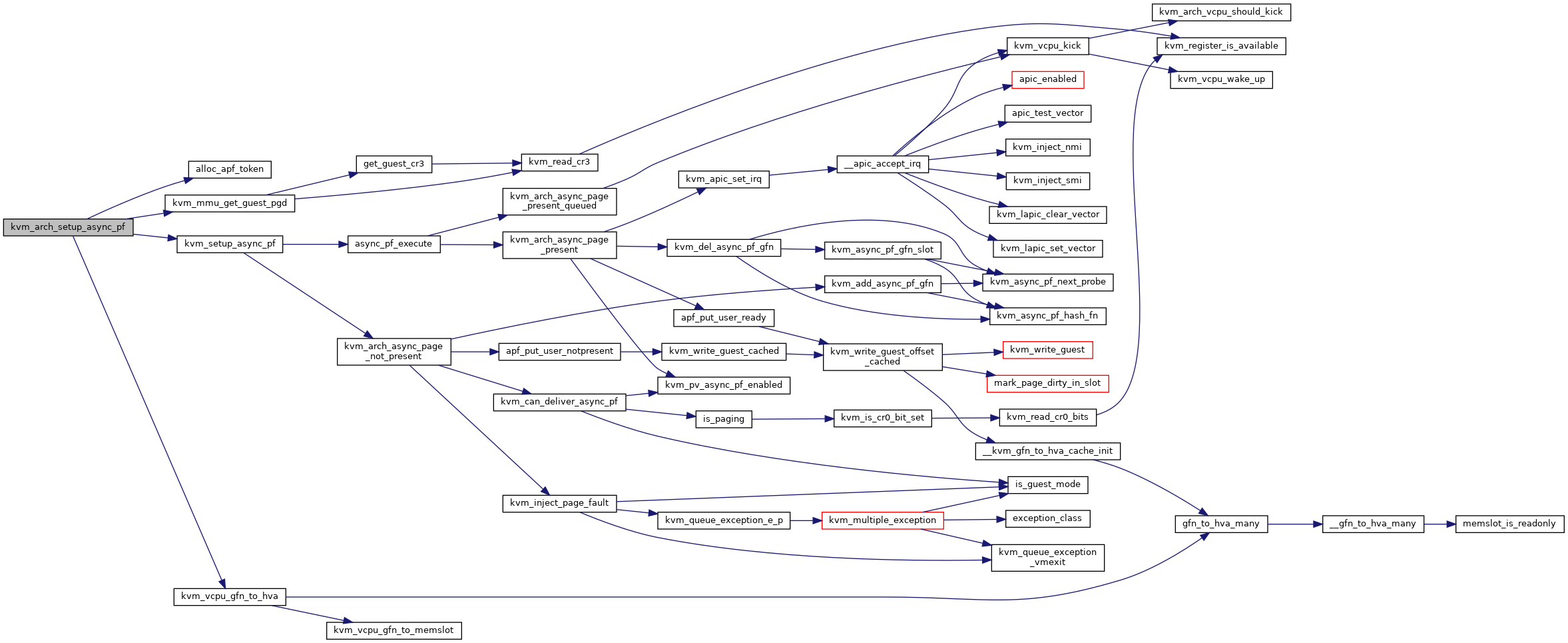
◆ kvm_arch_setup_async_pf()
|
static |
Definition at line 4249 of file mmu.c.
◆ kvm_available_flush_remote_tlbs_range()
|
inlinestatic |

◆ kvm_calc_cpu_role()
|
static |
◆ kvm_calc_shadow_ept_root_page_role()
|
static |

◆ kvm_calc_tdp_mmu_root_page_role()
|
static |

◆ kvm_configure_mmu()
| void kvm_configure_mmu | ( | bool | enable_tdp, |
| int | tdp_forced_root_level, | ||
| int | tdp_max_root_level, | ||
| int | tdp_huge_page_level | ||
| ) |
◆ kvm_cpu_dirty_log_size()
| int kvm_cpu_dirty_log_size | ( | void | ) |
◆ kvm_faultin_pfn()
|
static |
Definition at line 4400 of file mmu.c.
◆ kvm_faultin_pfn_private()
|
static |
Definition at line 4307 of file mmu.c.
◆ kvm_flush_remote_tlbs_sptep()
|
static |

◆ kvm_handle_error_pfn()
|
static |
Definition at line 3288 of file mmu.c.

◆ kvm_handle_gfn_range()
|
static |
◆ kvm_handle_noslot_fault()
|
static |

◆ kvm_handle_page_fault()
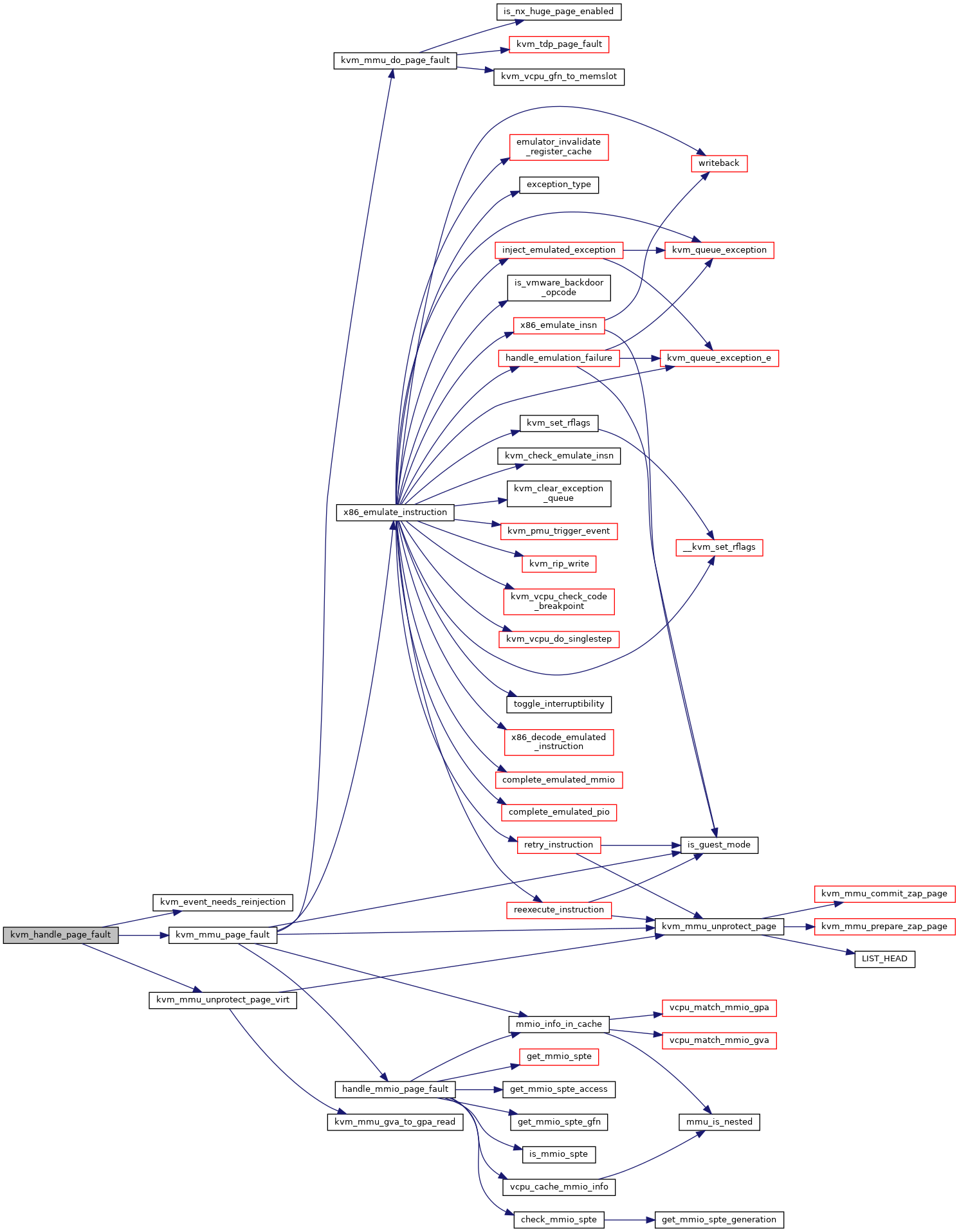
| int kvm_handle_page_fault | ( | struct kvm_vcpu * | vcpu, |
| u64 | error_code, | ||
| u64 | fault_address, | ||
| char * | insn, | ||
| int | insn_len | ||
| ) |
Definition at line 4540 of file mmu.c.
◆ kvm_has_zapped_obsolete_pages()
|
static |

◆ kvm_init_mmu()
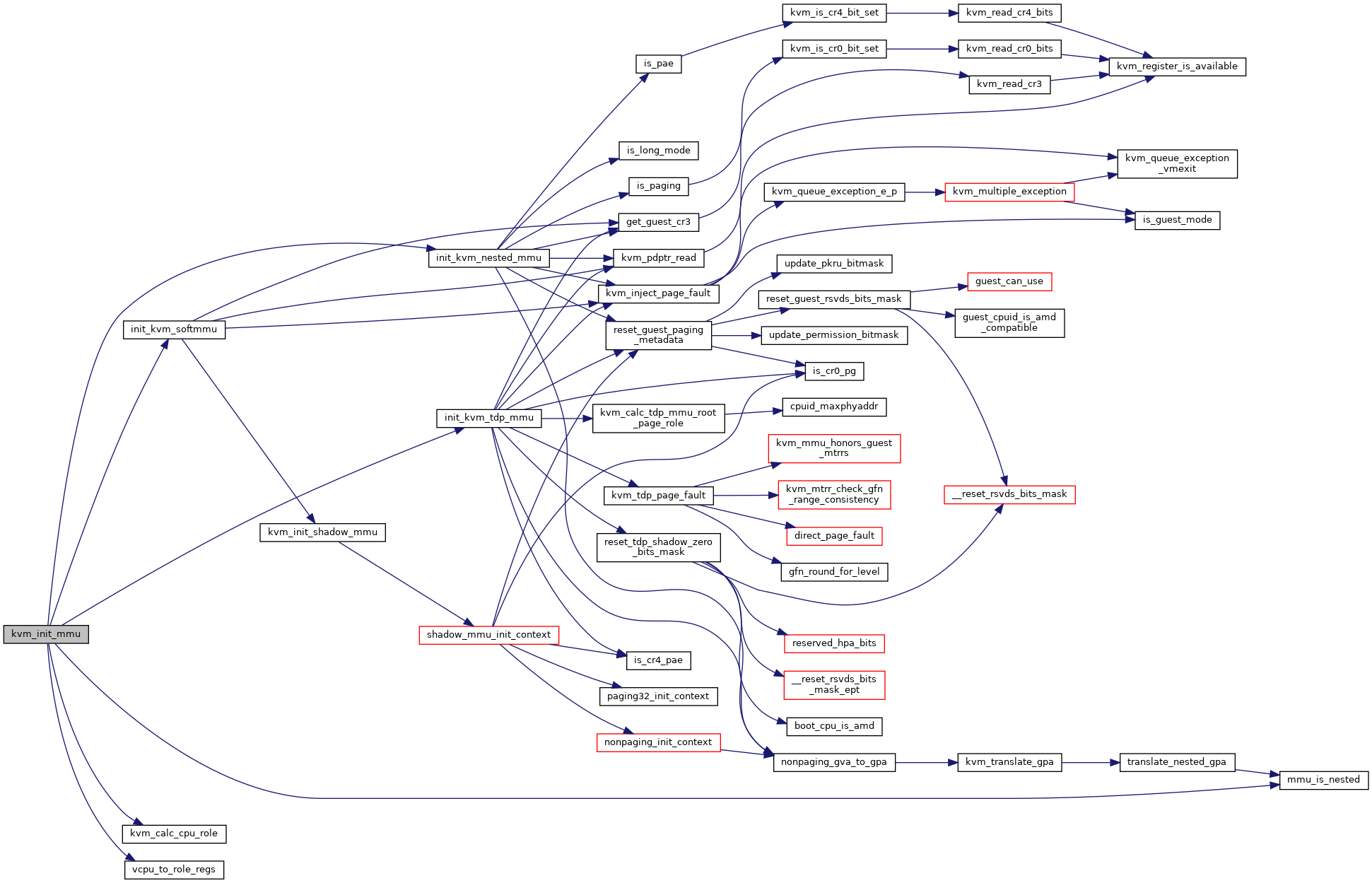
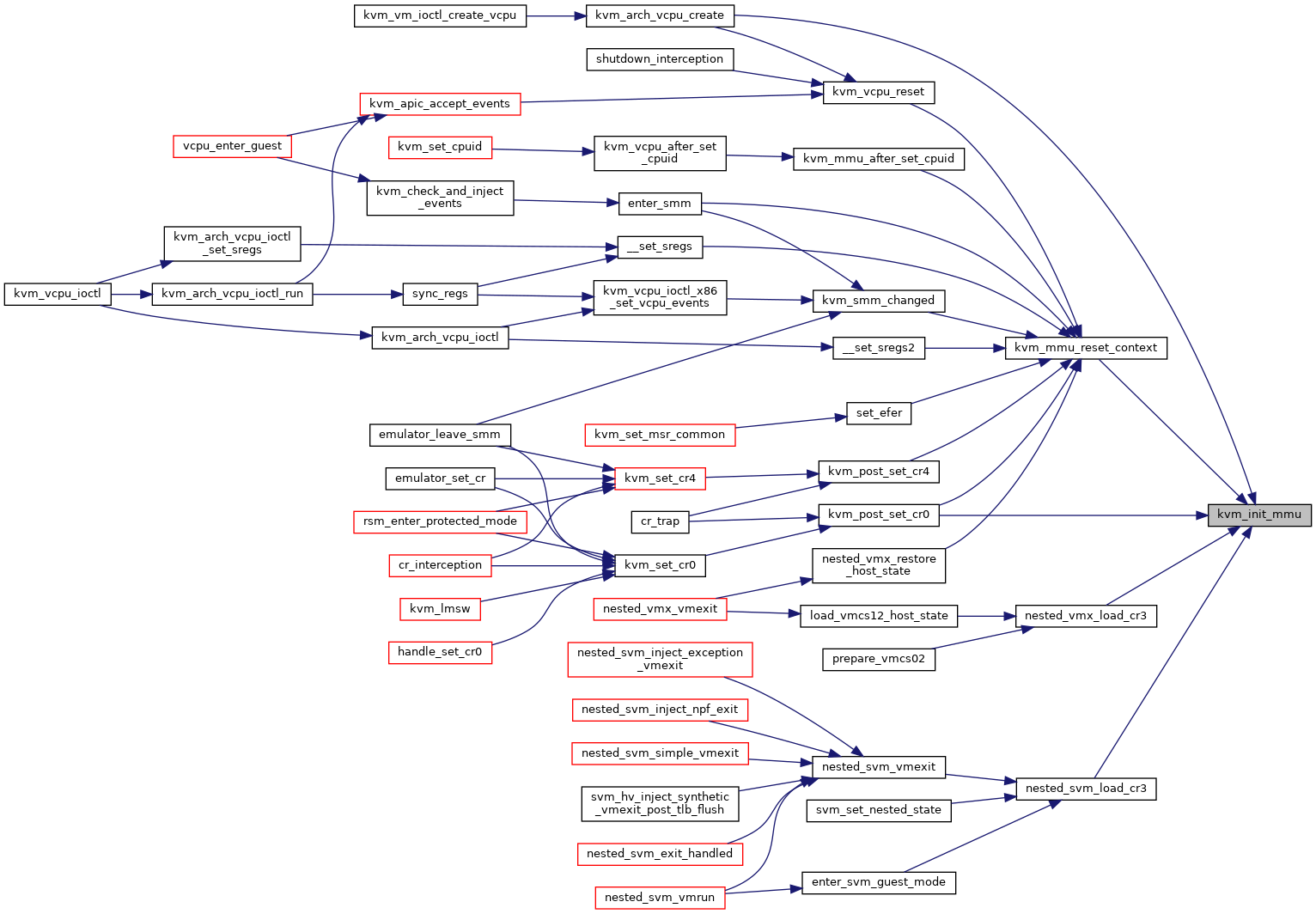
| void kvm_init_mmu | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 5538 of file mmu.c.
◆ kvm_init_shadow_ept_mmu()
| void kvm_init_shadow_ept_mmu | ( | struct kvm_vcpu * | vcpu, |
| bool | execonly, | ||
| int | huge_page_level, | ||
| bool | accessed_dirty, | ||
| gpa_t | new_eptp | ||
| ) |
Definition at line 5458 of file mmu.c.
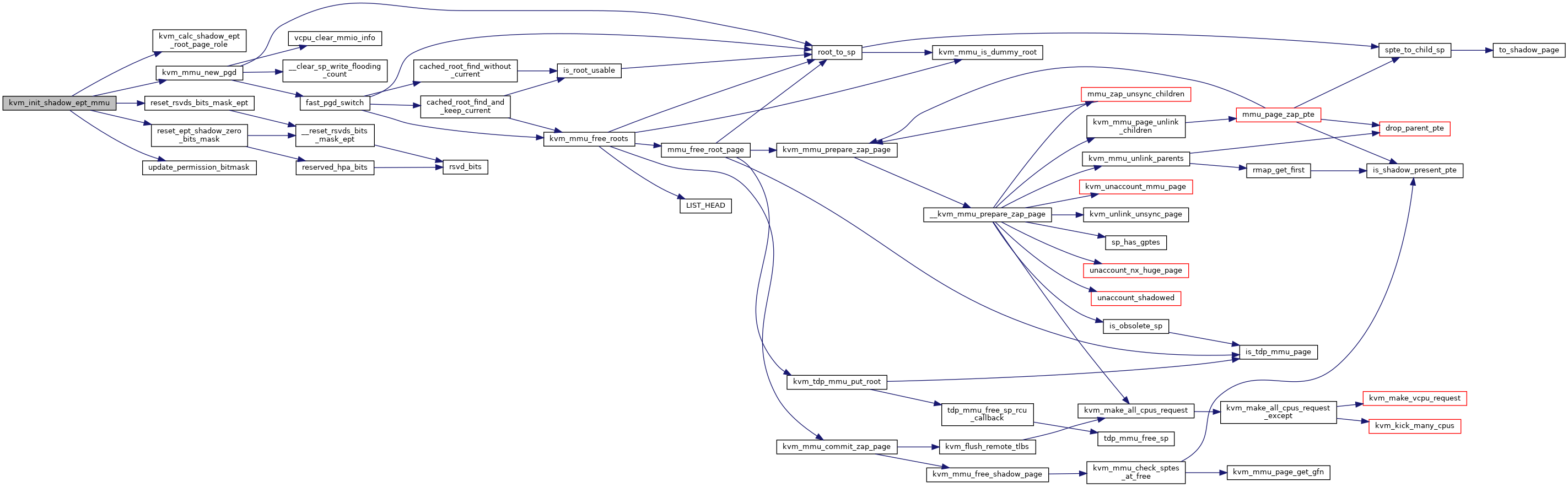

◆ kvm_init_shadow_mmu()
|
static |
Definition at line 5382 of file mmu.c.
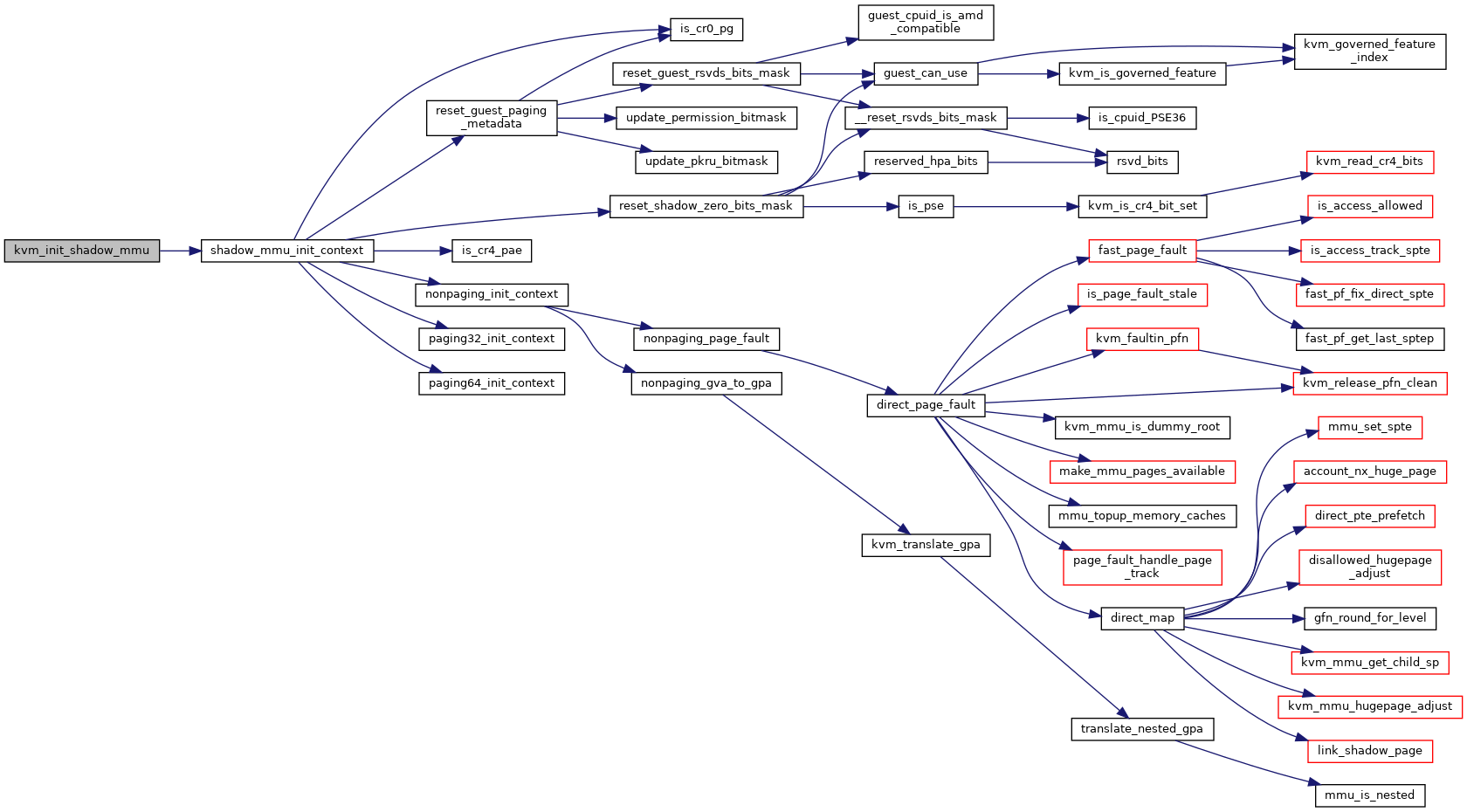
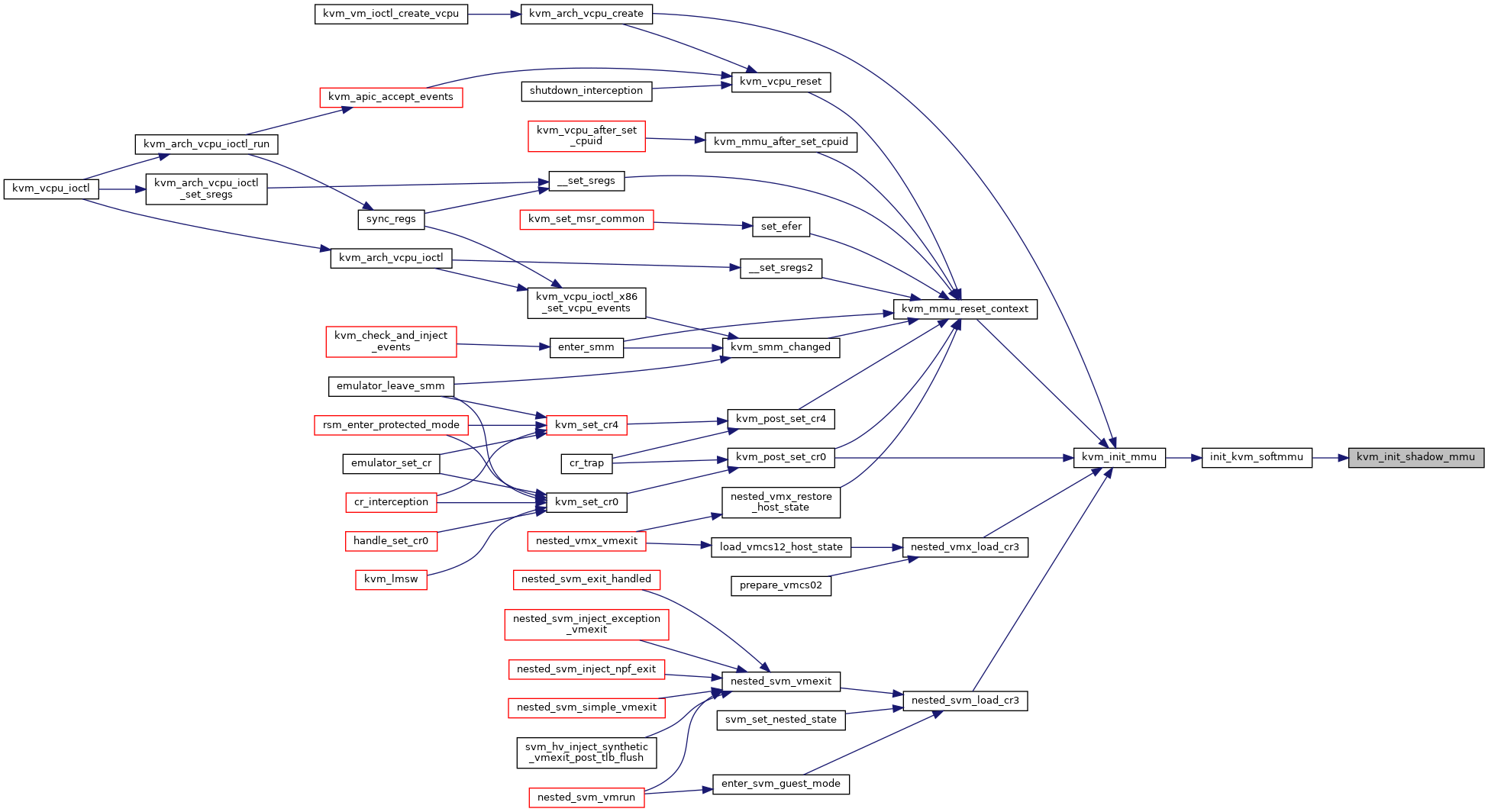
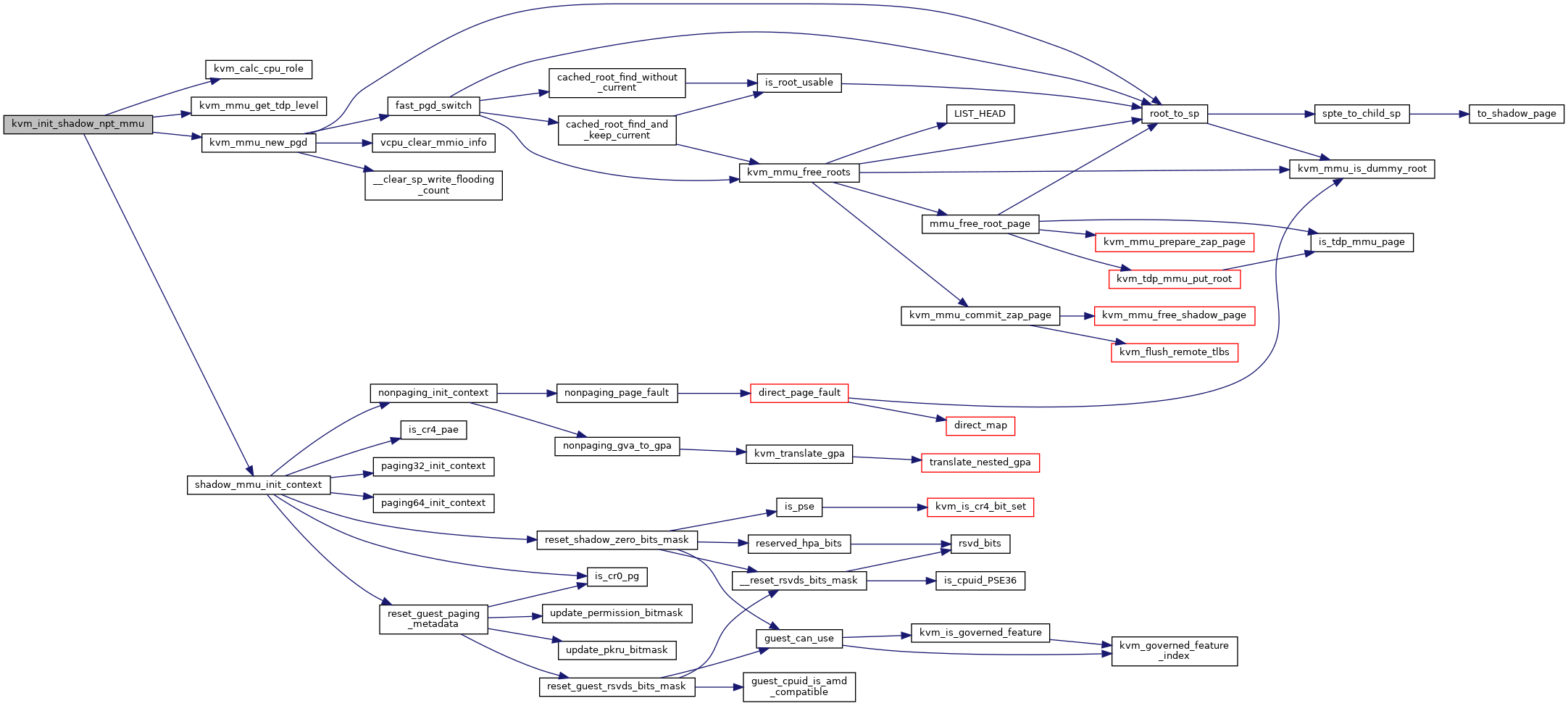
◆ kvm_init_shadow_npt_mmu()
| void kvm_init_shadow_npt_mmu | ( | struct kvm_vcpu * | vcpu, |
| unsigned long | cr0, | ||
| unsigned long | cr4, | ||
| u64 | efer, | ||
| gpa_t | nested_cr3 | ||
| ) |

◆ kvm_max_level_for_order()
|
inlinestatic |
◆ kvm_mmu_after_set_cpuid()
| void kvm_mmu_after_set_cpuid | ( | struct kvm_vcpu * | vcpu | ) |

◆ kvm_mmu_alloc_shadow_page()
|
static |
Definition at line 2236 of file mmu.c.
◆ kvm_mmu_available_pages()
|
inlinestatic |
◆ kvm_mmu_change_mmu_pages()
| void kvm_mmu_change_mmu_pages | ( | struct kvm * | kvm, |
| unsigned long | goal_nr_mmu_pages | ||
| ) |
Definition at line 2741 of file mmu.c.

◆ kvm_mmu_check_sptes_at_free()
|
static |
◆ kvm_mmu_child_role()
|
static |
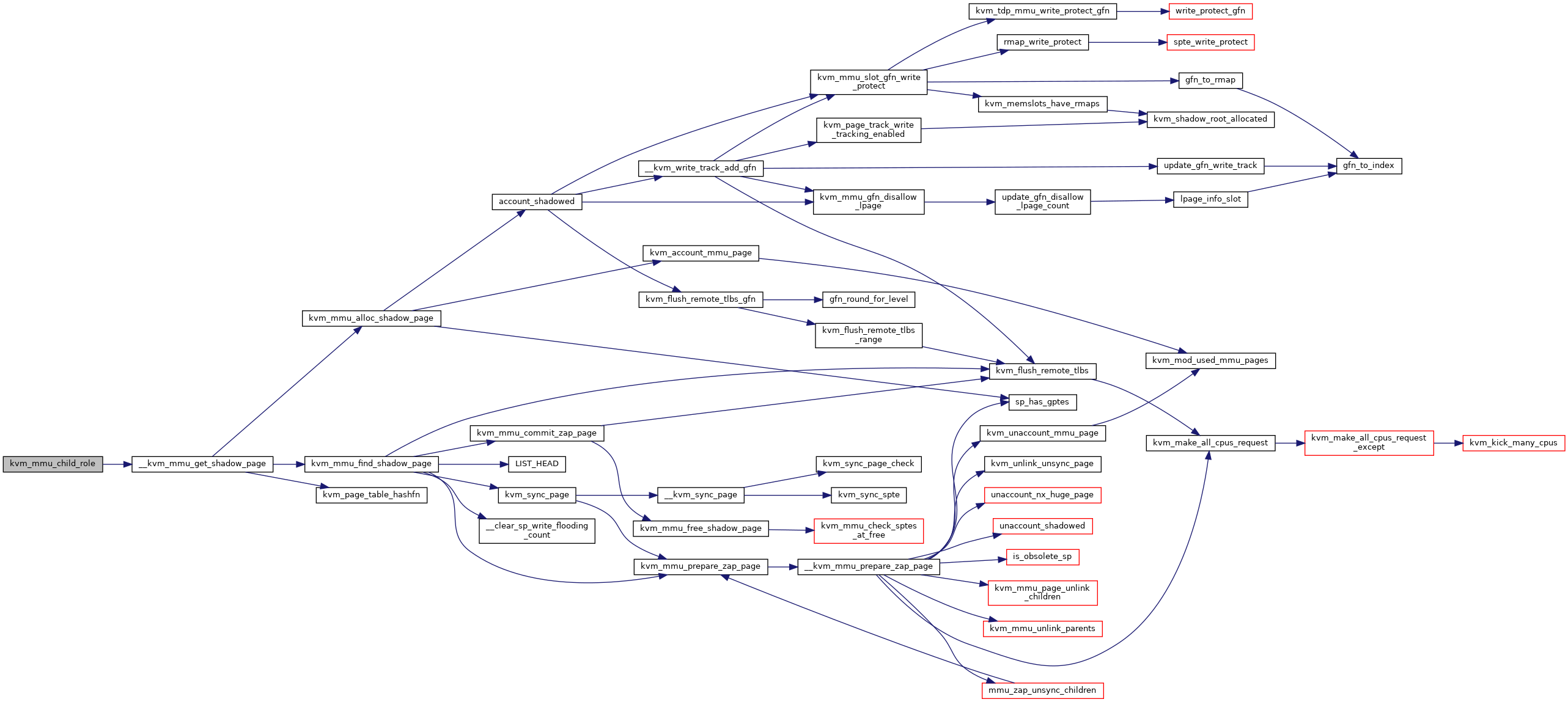
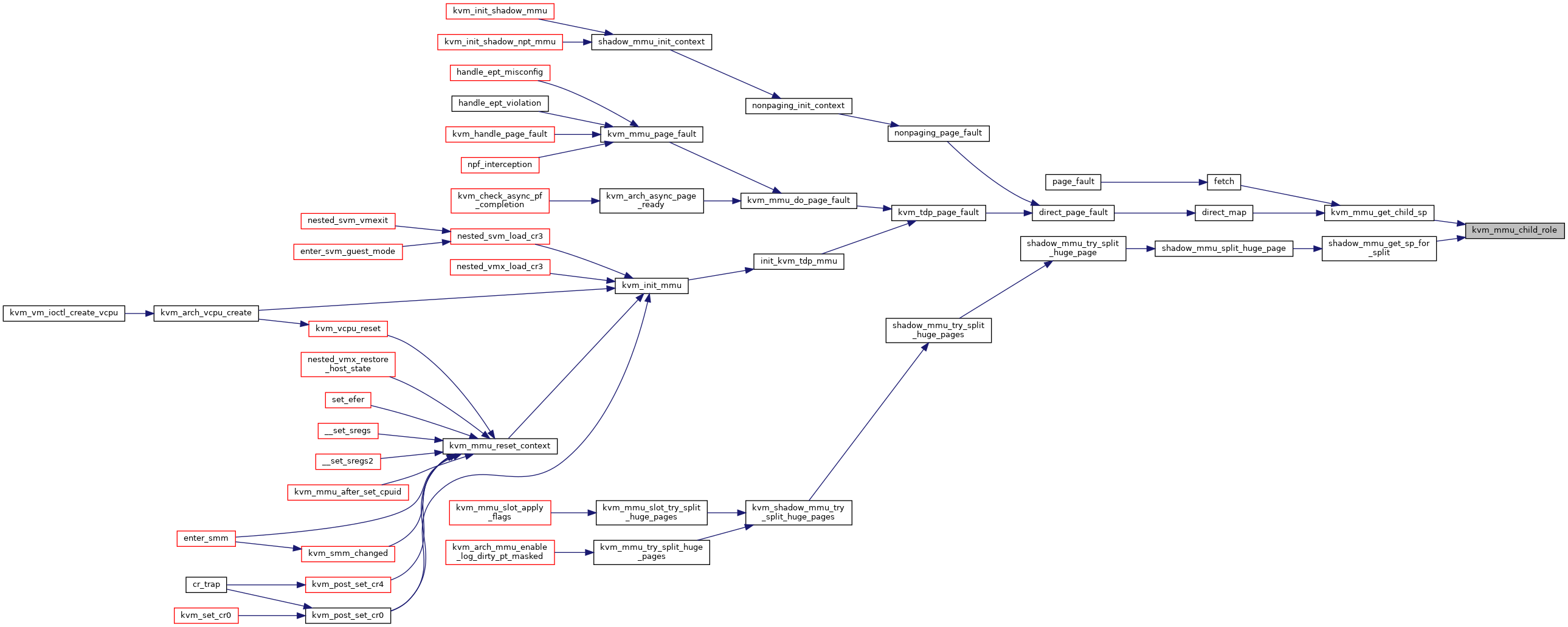
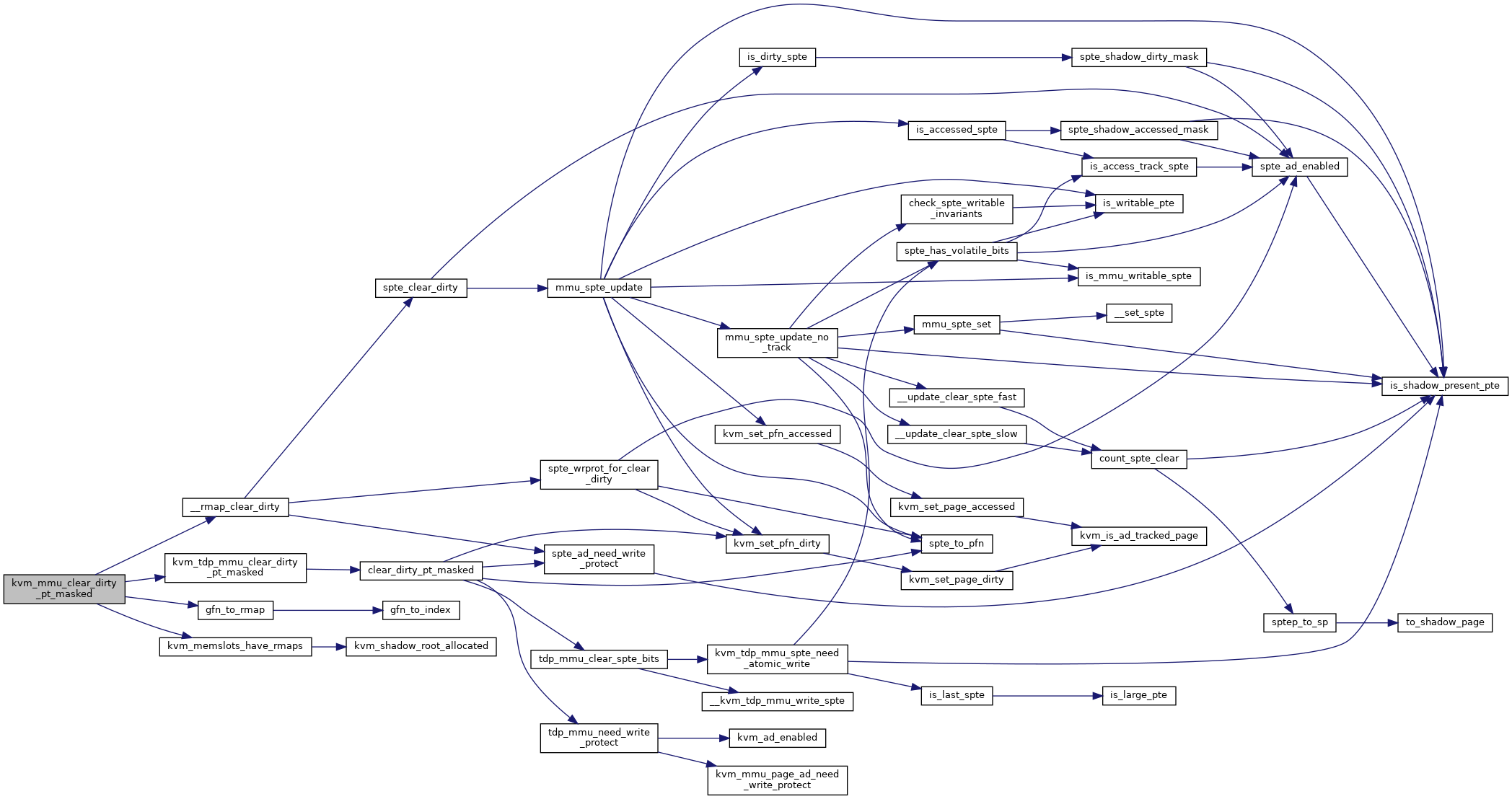
◆ kvm_mmu_clear_dirty_pt_masked()
|
static |
kvm_mmu_clear_dirty_pt_masked - clear MMU D-bit for PT level pages, or write protect the page if the D-bit isn't supported. @kvm: kvm instance @slot: slot to clear D-bit @gfn_offset: start of the BITS_PER_LONG pages we care about @mask: indicates which pages we should clear D-bit
Used for PML to re-log the dirty GPAs after userspace querying dirty_bitmap.
Definition at line 1340 of file mmu.c.
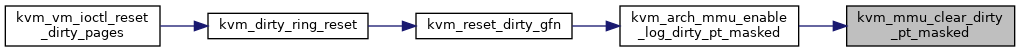
◆ kvm_mmu_commit_zap_page()
|
static |
Definition at line 2643 of file mmu.c.

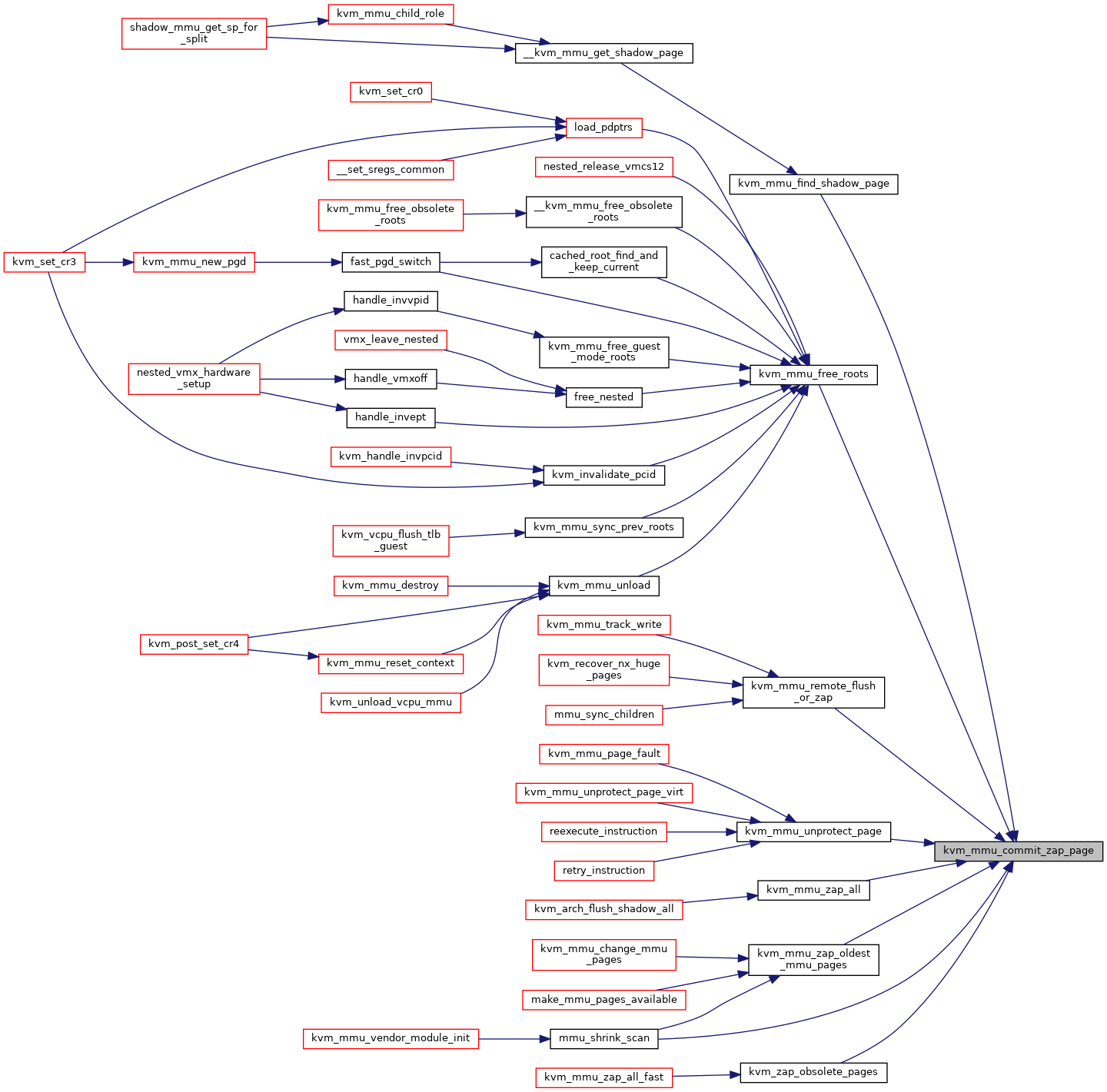
◆ kvm_mmu_create()
| int kvm_mmu_create | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 6153 of file mmu.c.


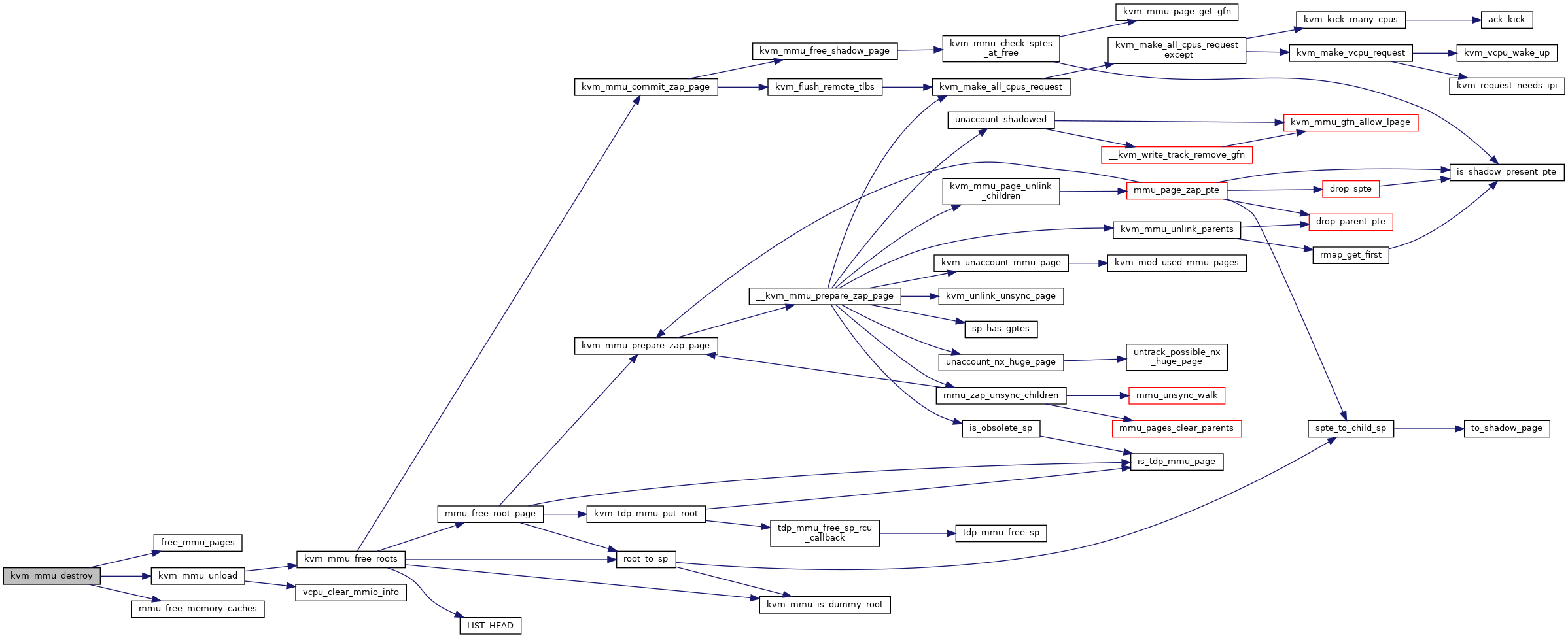
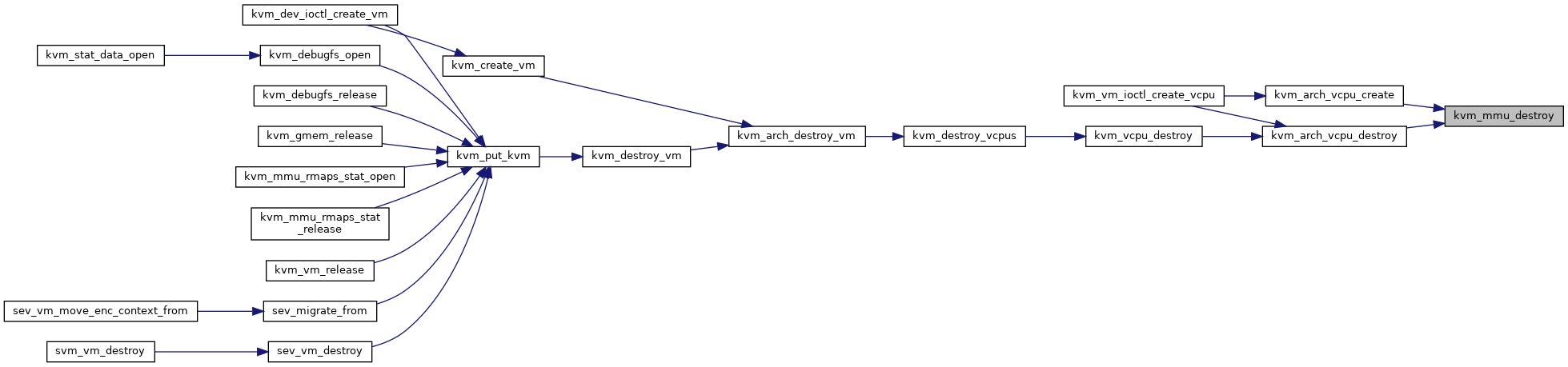
◆ kvm_mmu_destroy()
| void kvm_mmu_destroy | ( | struct kvm_vcpu * | vcpu | ) |
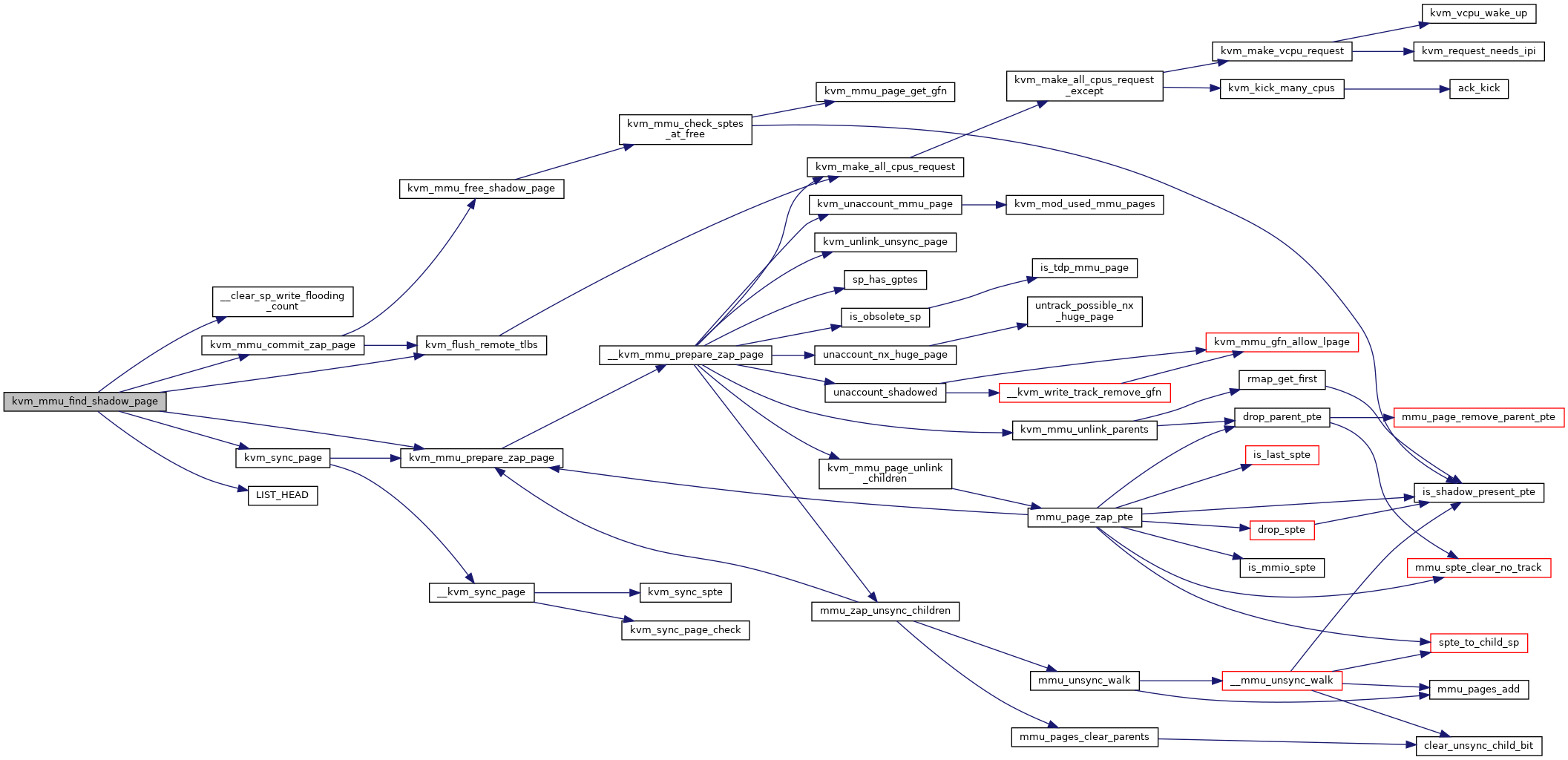
◆ kvm_mmu_find_shadow_page()
|
static |
Definition at line 2151 of file mmu.c.
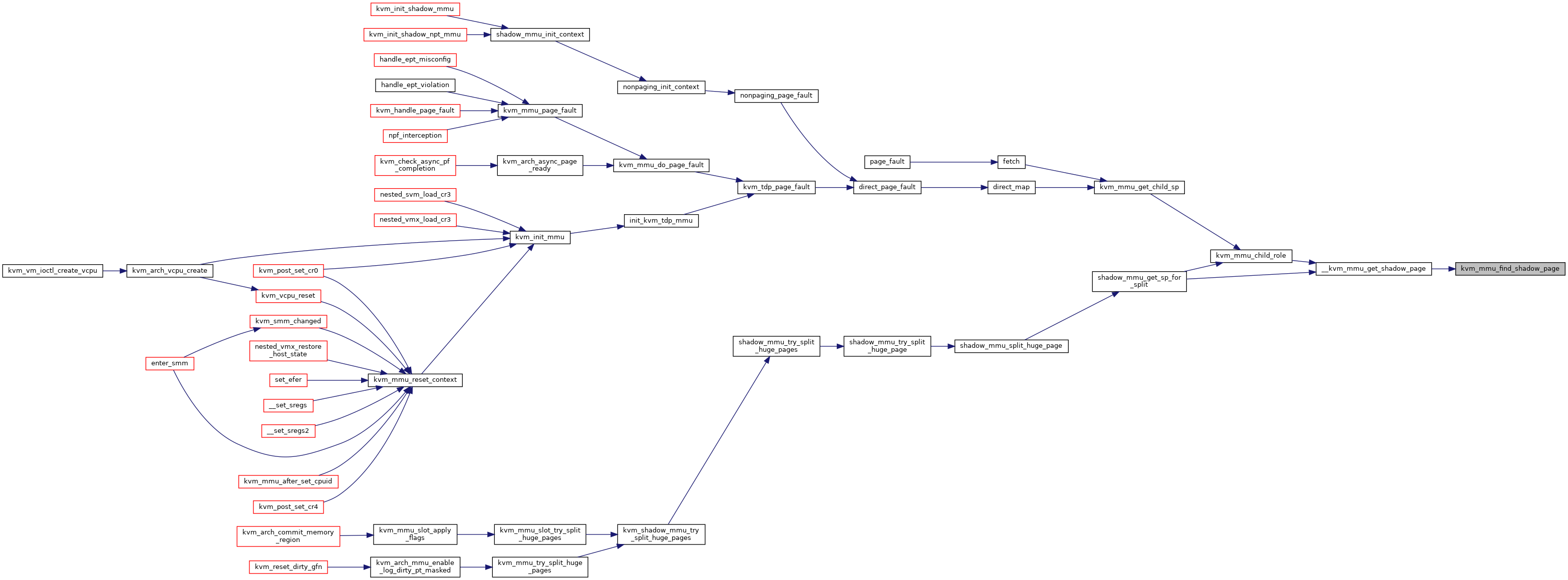
◆ kvm_mmu_free_guest_mode_roots()
| void kvm_mmu_free_guest_mode_roots | ( | struct kvm * | kvm, |
| struct kvm_mmu * | mmu | ||
| ) |
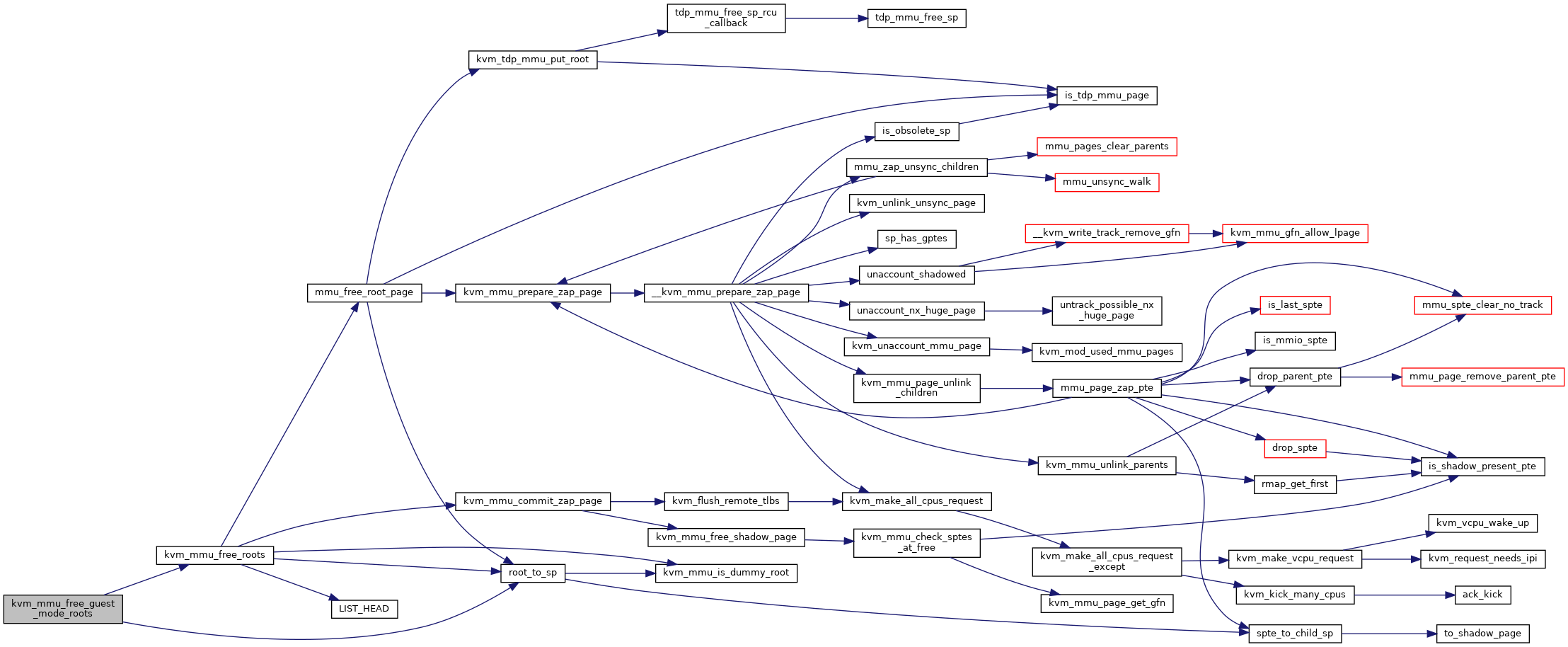

◆ kvm_mmu_free_obsolete_roots()
| void kvm_mmu_free_obsolete_roots | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 5676 of file mmu.c.
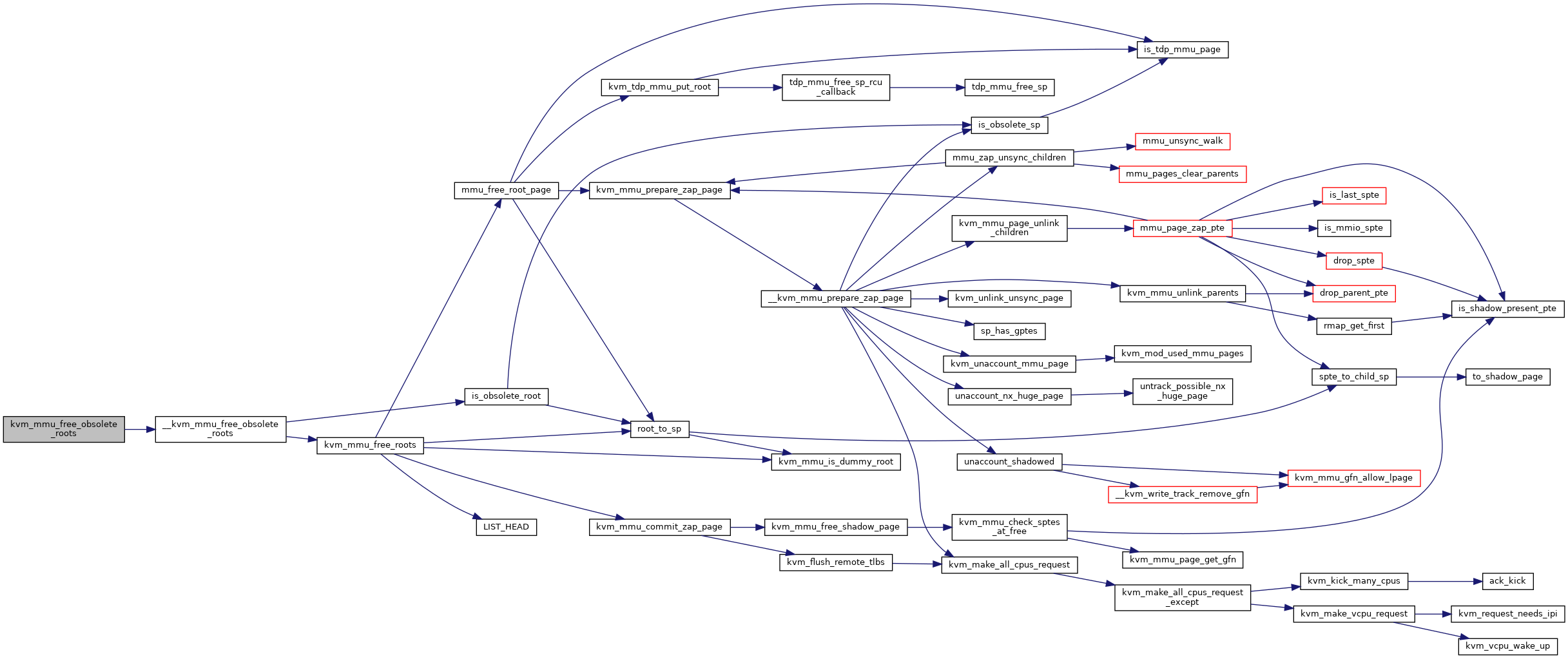

◆ kvm_mmu_free_roots()
| void kvm_mmu_free_roots | ( | struct kvm * | kvm, |
| struct kvm_mmu * | mmu, | ||
| ulong | roots_to_free | ||
| ) |
Definition at line 3587 of file mmu.c.
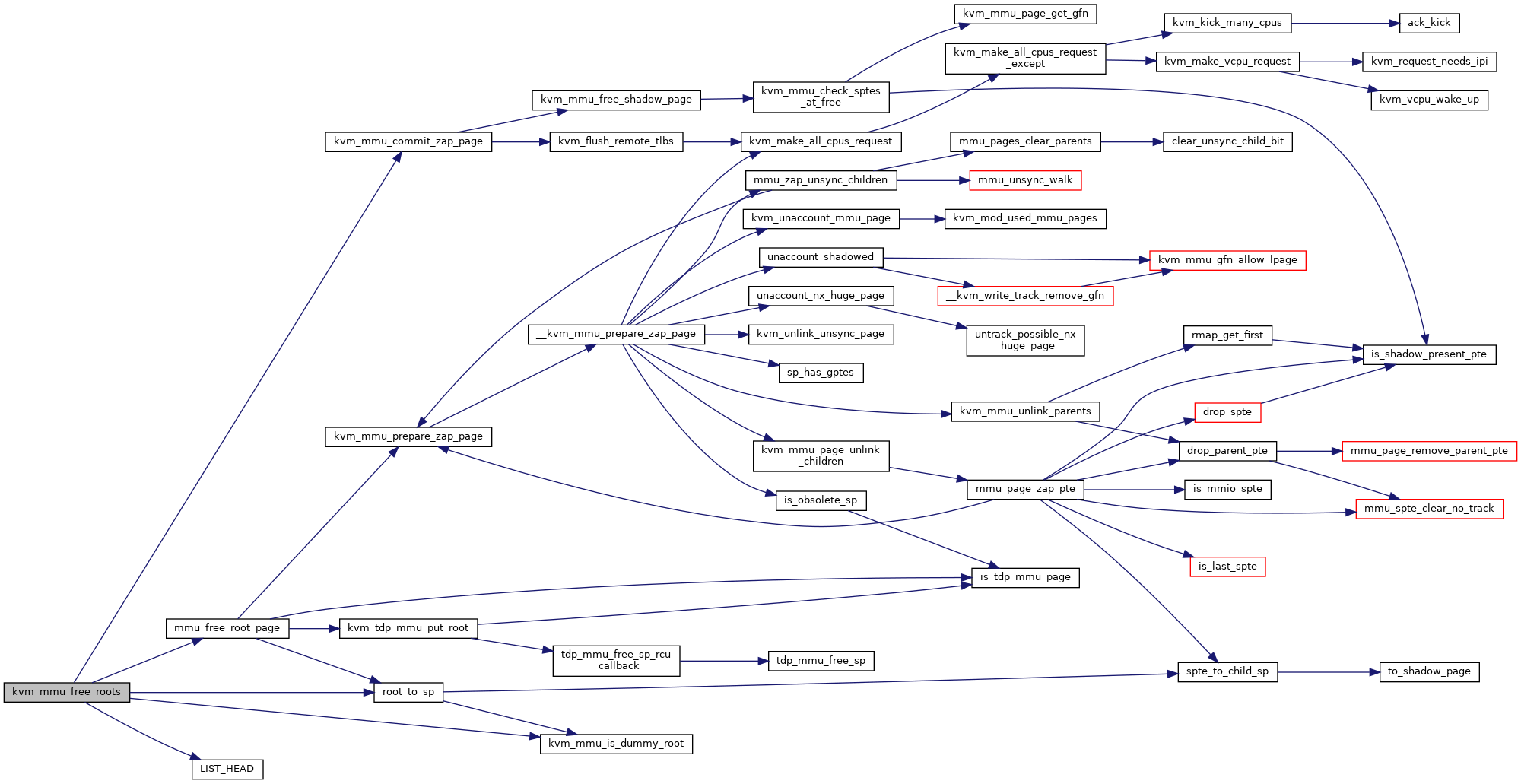
◆ kvm_mmu_free_shadow_page()
|
static |
Definition at line 1737 of file mmu.c.

◆ kvm_mmu_get_child_sp()
|
static |
Definition at line 2353 of file mmu.c.
◆ kvm_mmu_get_guest_pgd()
|
inlinestatic |

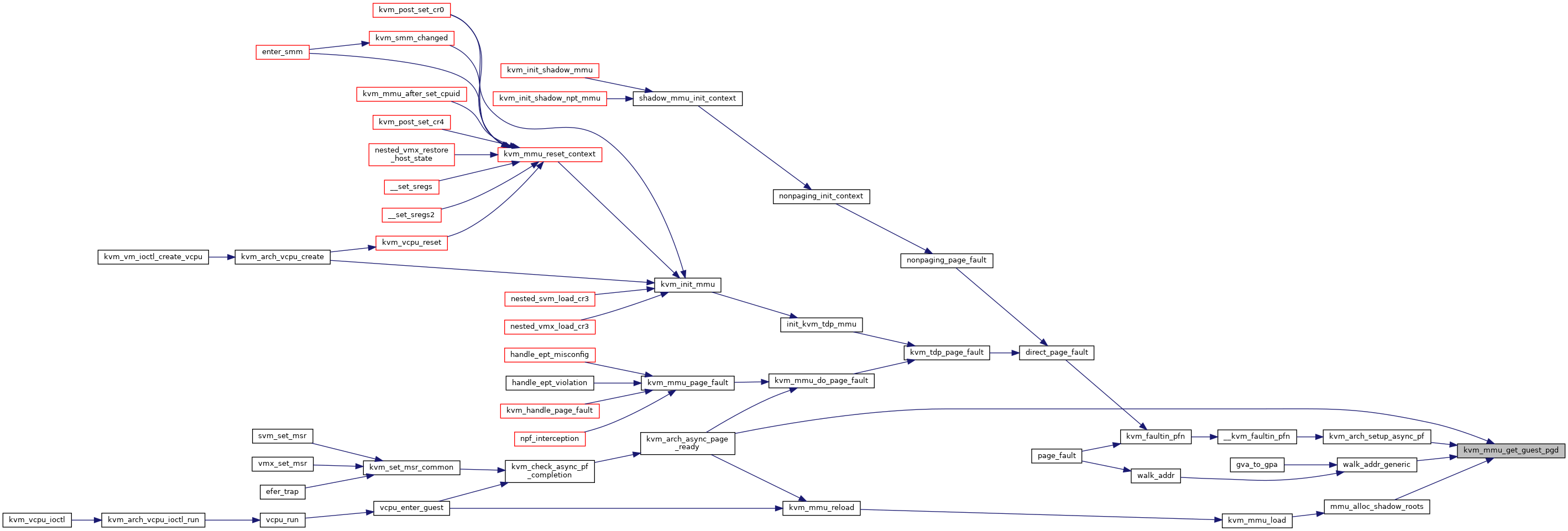
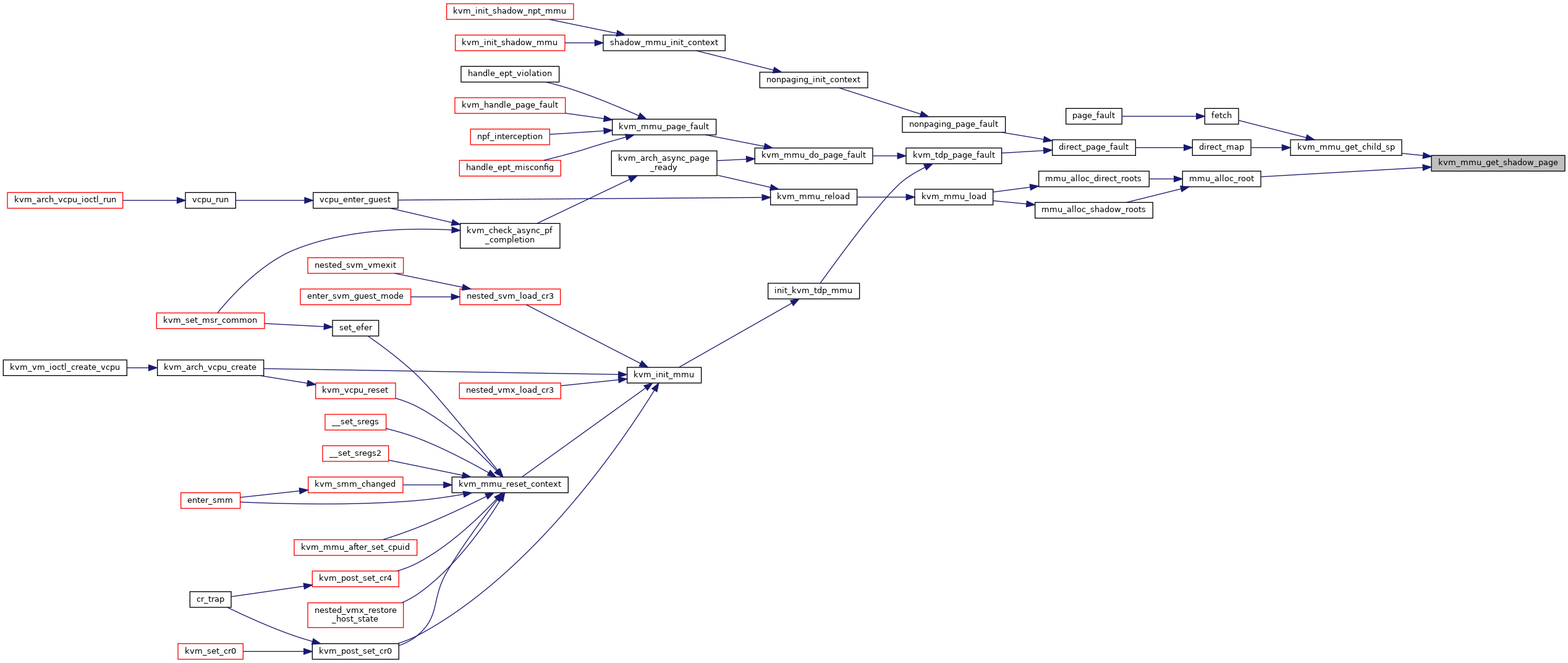
◆ kvm_mmu_get_shadow_page()
|
static |
Definition at line 2294 of file mmu.c.
◆ kvm_mmu_get_tdp_level()
|
inlinestatic |

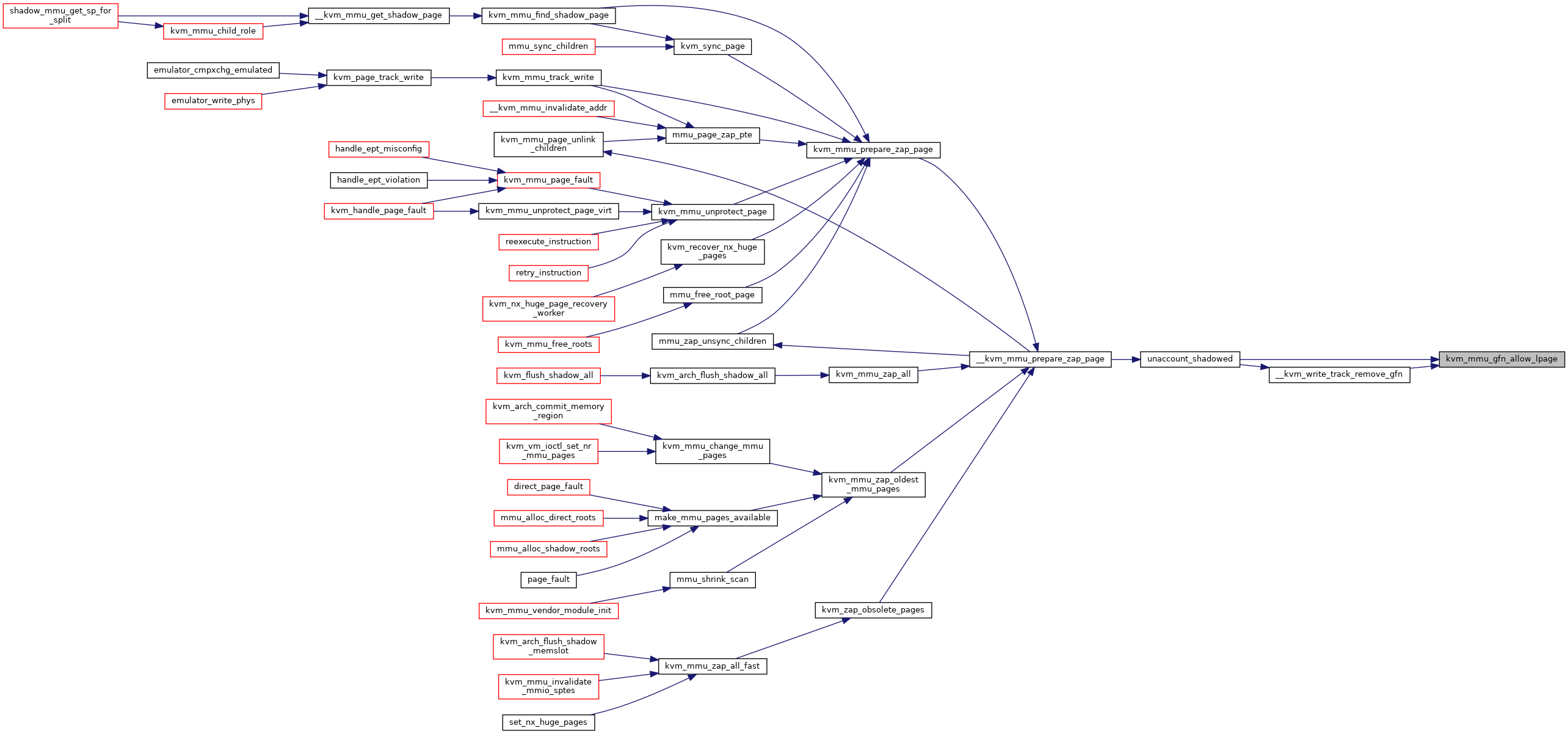
◆ kvm_mmu_gfn_allow_lpage()
| void kvm_mmu_gfn_allow_lpage | ( | const struct kvm_memory_slot * | slot, |
| gfn_t | gfn | ||
| ) |

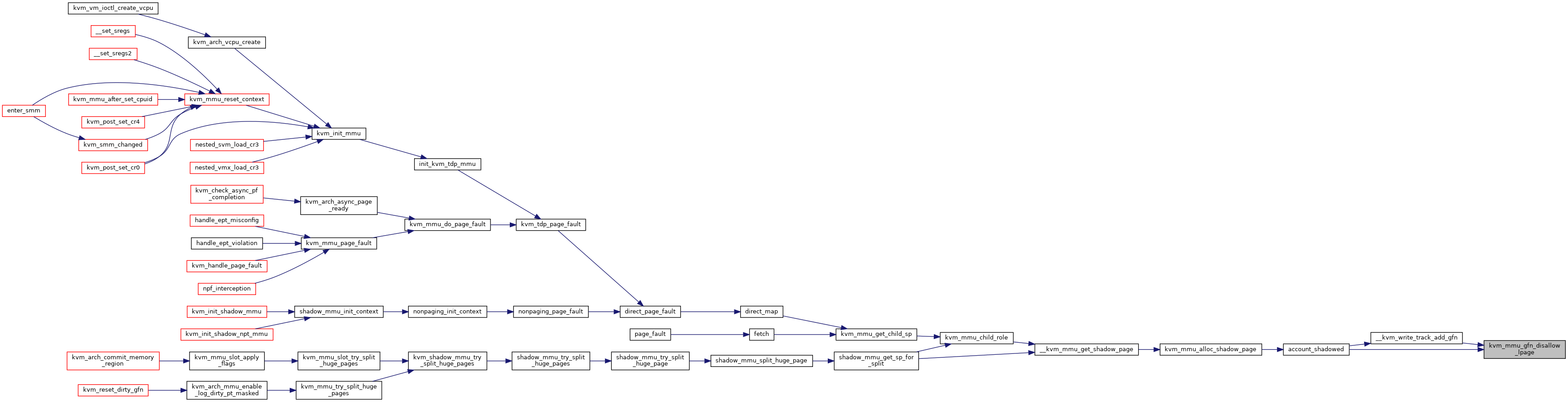
◆ kvm_mmu_gfn_disallow_lpage()
| void kvm_mmu_gfn_disallow_lpage | ( | const struct kvm_memory_slot * | slot, |
| gfn_t | gfn | ||
| ) |

◆ kvm_mmu_hugepage_adjust()
| void kvm_mmu_hugepage_adjust | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_page_fault * | fault | ||
| ) |
Definition at line 3180 of file mmu.c.

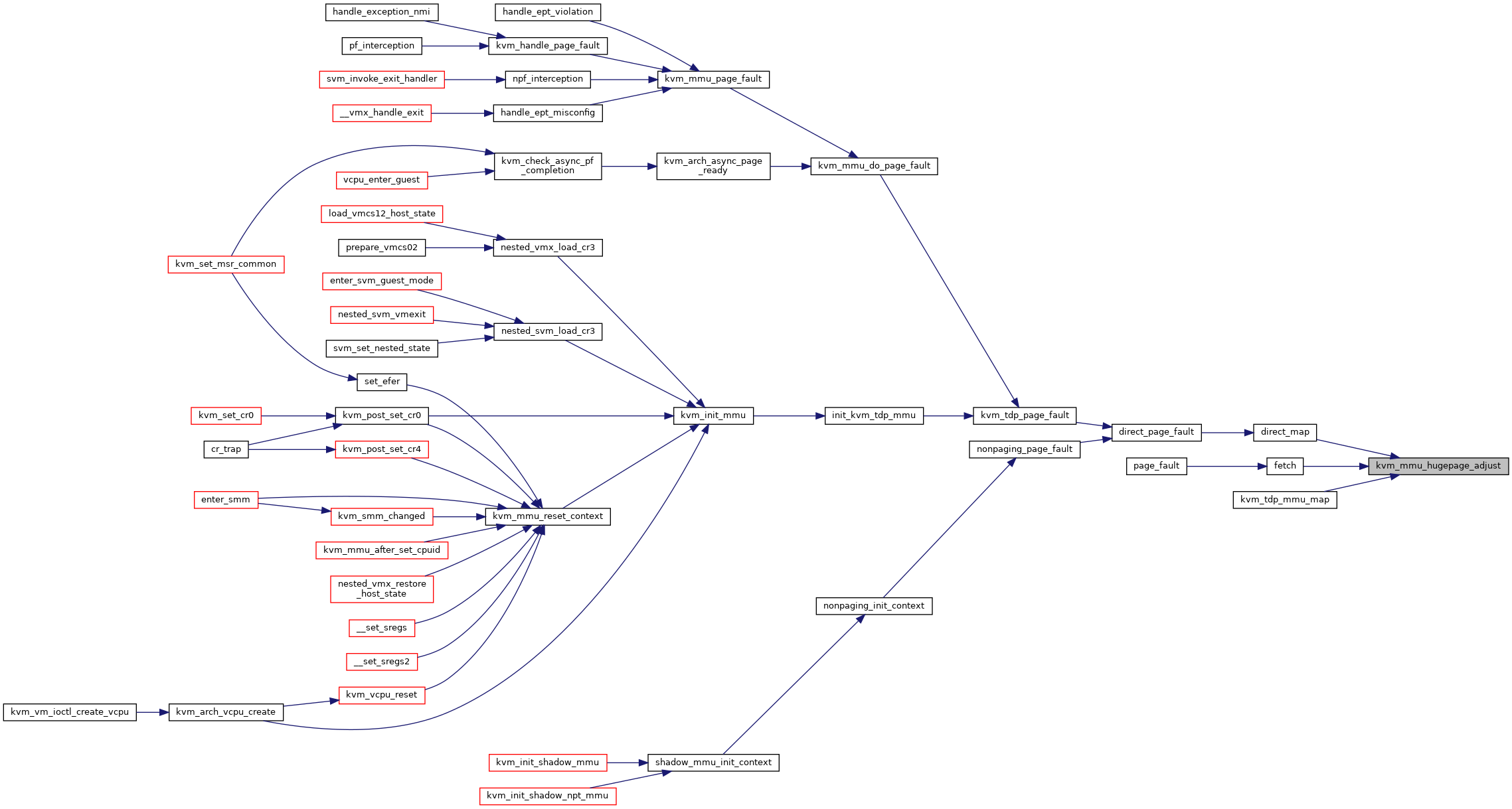
◆ kvm_mmu_init_vm()
| void kvm_mmu_init_vm | ( | struct kvm * | kvm | ) |


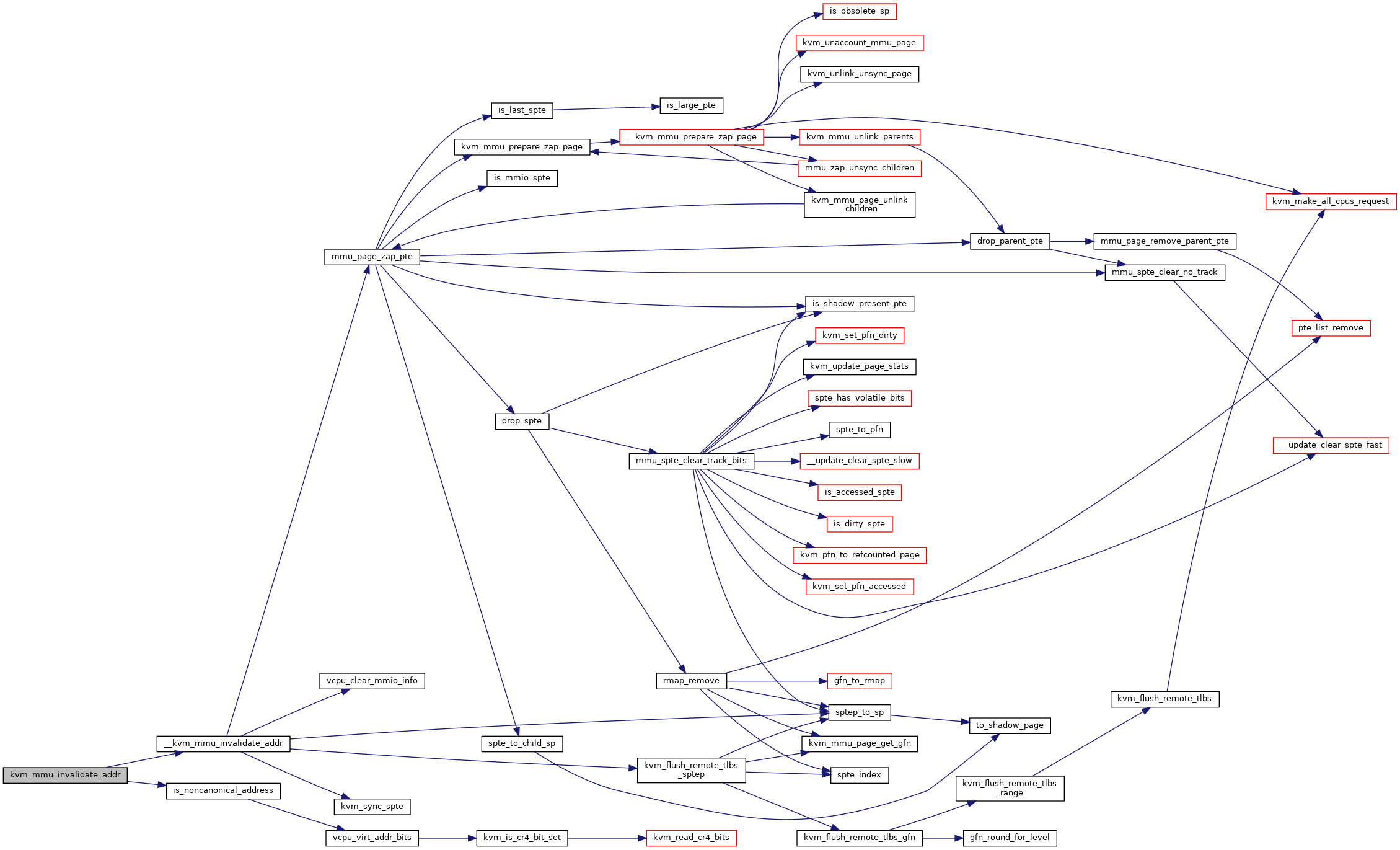
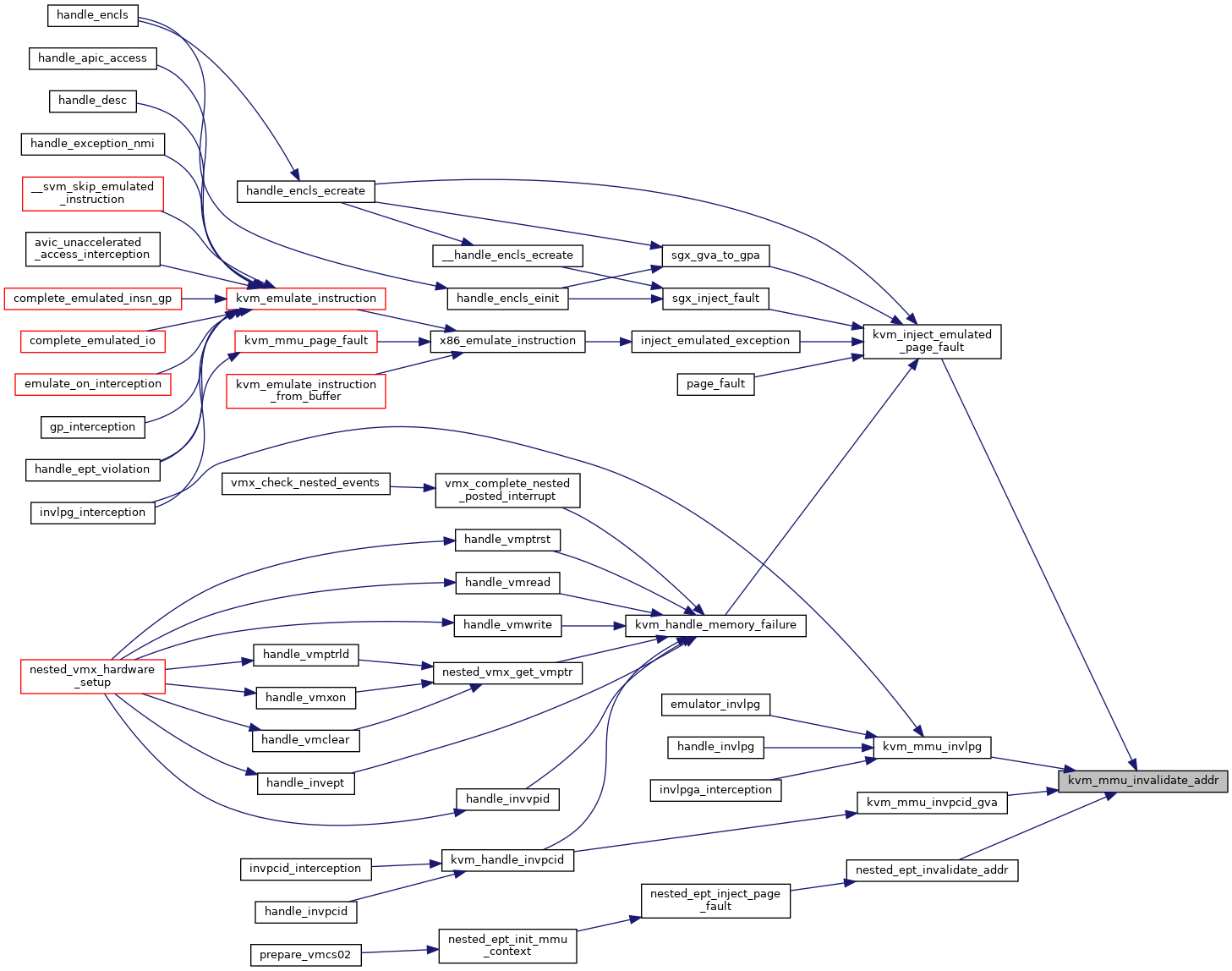
◆ kvm_mmu_invalidate_addr()
| void kvm_mmu_invalidate_addr | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_mmu * | mmu, | ||
| u64 | addr, | ||
| unsigned long | roots | ||
| ) |
Definition at line 5939 of file mmu.c.
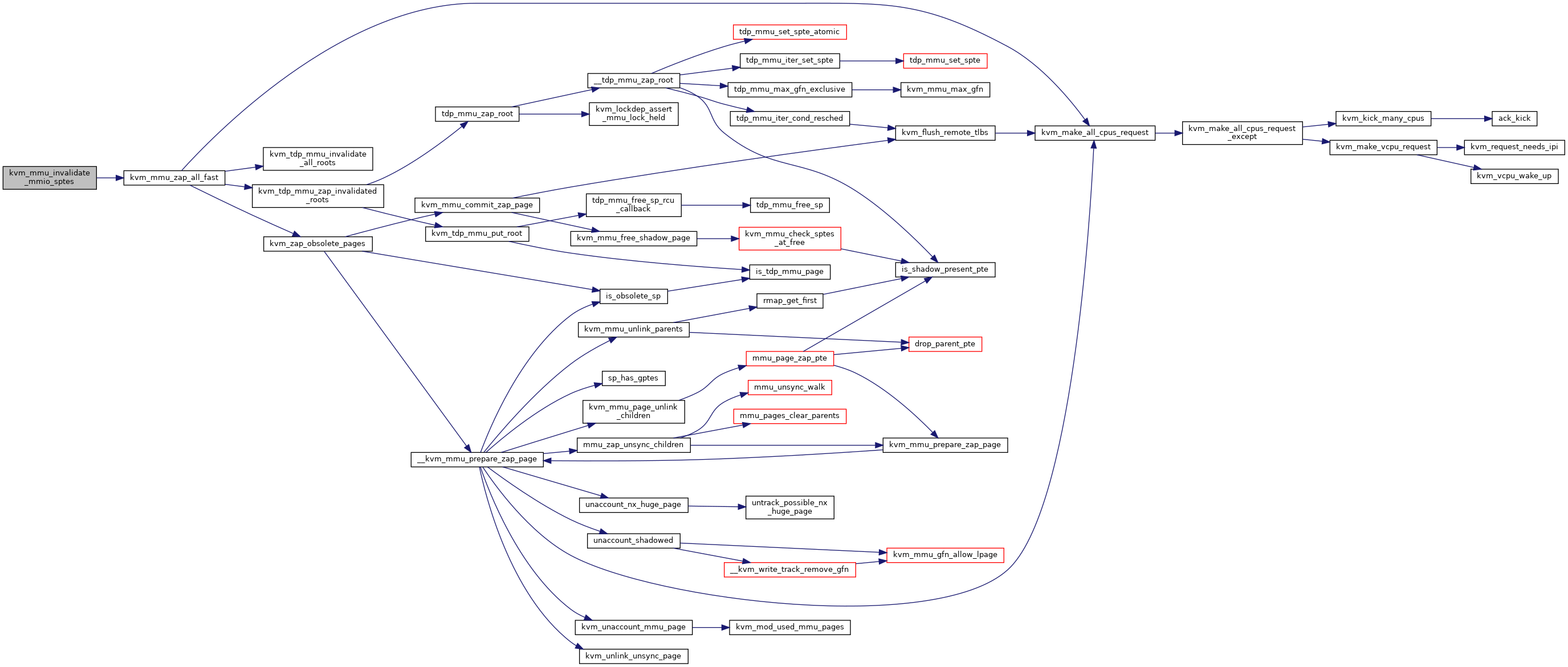
◆ kvm_mmu_invalidate_mmio_sptes()
| void kvm_mmu_invalidate_mmio_sptes | ( | struct kvm * | kvm, |
| u64 | gen | ||
| ) |

◆ kvm_mmu_invlpg()
| void kvm_mmu_invlpg | ( | struct kvm_vcpu * | vcpu, |
| gva_t | gva | ||
| ) |
Definition at line 5968 of file mmu.c.
◆ kvm_mmu_invpcid_gva()
| void kvm_mmu_invpcid_gva | ( | struct kvm_vcpu * | vcpu, |
| gva_t | gva, | ||
| unsigned long | pcid | ||
| ) |

◆ kvm_mmu_load()
| int kvm_mmu_load | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 5588 of file mmu.c.

◆ kvm_mmu_mark_parents_unsync()
|
static |

◆ kvm_mmu_max_mapping_level()
| int kvm_mmu_max_mapping_level | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| int | max_level | ||
| ) |


◆ kvm_mmu_new_pgd()
| void kvm_mmu_new_pgd | ( | struct kvm_vcpu * | vcpu, |
| gpa_t | new_pgd | ||
| ) |
Definition at line 4753 of file mmu.c.
◆ kvm_mmu_page_fault()
| int noinline kvm_mmu_page_fault | ( | struct kvm_vcpu * | vcpu, |
| gpa_t | cr2_or_gpa, | ||
| u64 | error_code, | ||
| void * | insn, | ||
| int | insn_len | ||
| ) |
Definition at line 5830 of file mmu.c.
◆ kvm_mmu_page_get_access()
|
static |


◆ kvm_mmu_page_get_gfn()
|
static |
◆ kvm_mmu_page_set_access()
|
static |

◆ kvm_mmu_page_set_translation()
|
static |

◆ kvm_mmu_page_unlink_children()
|
static |
◆ kvm_mmu_post_init_vm()
| int kvm_mmu_post_init_vm | ( | struct kvm * | kvm | ) |
Definition at line 7279 of file mmu.c.

◆ kvm_mmu_pre_destroy_vm()
| void kvm_mmu_pre_destroy_vm | ( | struct kvm * | kvm | ) |

◆ kvm_mmu_prepare_memory_fault_exit()
|
static |
◆ kvm_mmu_prepare_zap_page()
|
static |
Definition at line 2634 of file mmu.c.
◆ kvm_mmu_remote_flush_or_zap()
|
static |

◆ kvm_mmu_reset_context()
| void kvm_mmu_reset_context | ( | struct kvm_vcpu * | vcpu | ) |
◆ kvm_mmu_slot_gfn_write_protect()
| bool kvm_mmu_slot_gfn_write_protect | ( | struct kvm * | kvm, |
| struct kvm_memory_slot * | slot, | ||
| u64 | gfn, | ||
| int | min_level | ||
| ) |
Definition at line 1414 of file mmu.c.
◆ kvm_mmu_slot_leaf_clear_dirty()
| void kvm_mmu_slot_leaf_clear_dirty | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | memslot | ||
| ) |
Definition at line 6769 of file mmu.c.

◆ kvm_mmu_slot_remove_write_access()
| void kvm_mmu_slot_remove_write_access | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | memslot, | ||
| int | start_level | ||
| ) |
Definition at line 6406 of file mmu.c.

◆ kvm_mmu_slot_try_split_huge_pages()
| void kvm_mmu_slot_try_split_huge_pages | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | memslot, | ||
| int | target_level | ||
| ) |
Definition at line 6673 of file mmu.c.

◆ kvm_mmu_sync_prev_roots()
| void kvm_mmu_sync_prev_roots | ( | struct kvm_vcpu * | vcpu | ) |
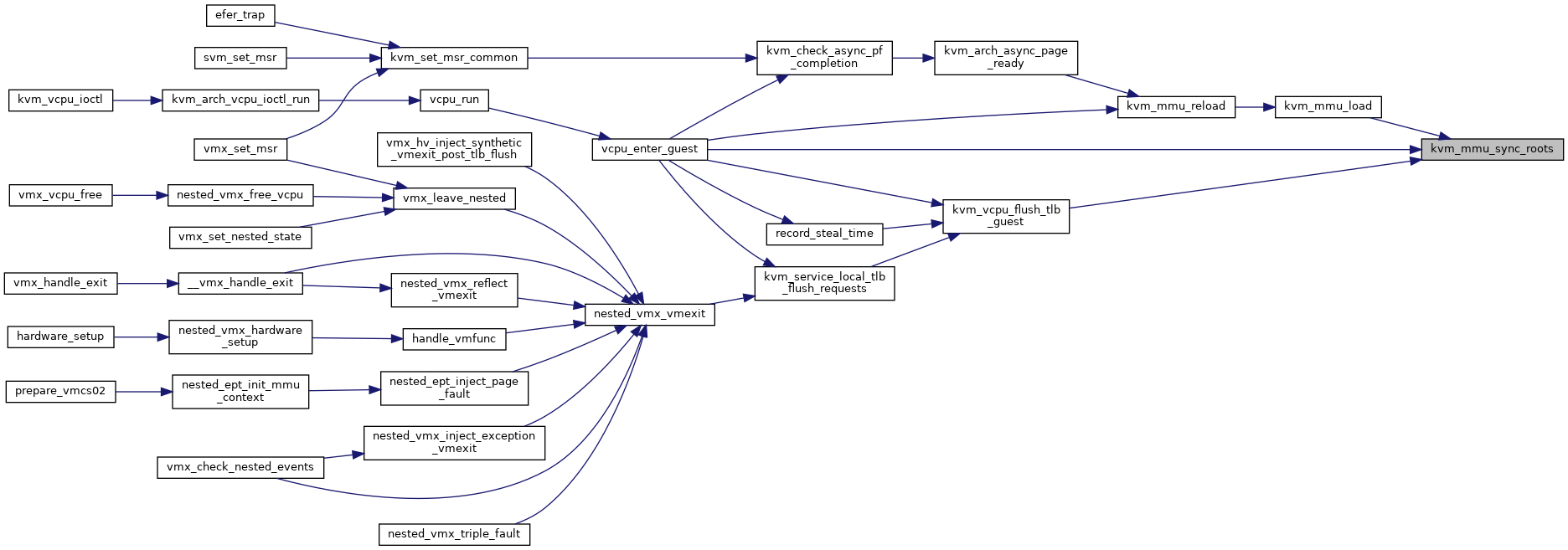
◆ kvm_mmu_sync_roots()
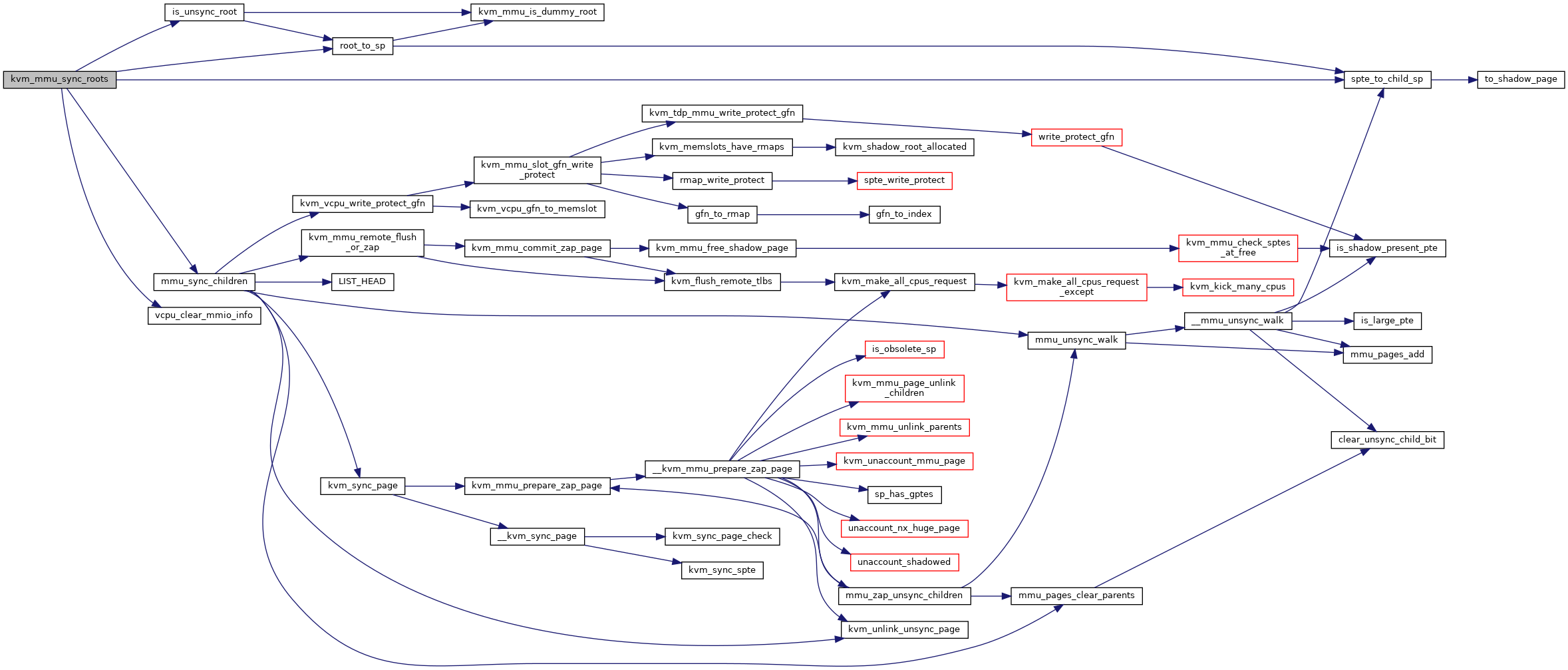
| void kvm_mmu_sync_roots | ( | struct kvm_vcpu * | vcpu | ) |
Definition at line 4021 of file mmu.c.
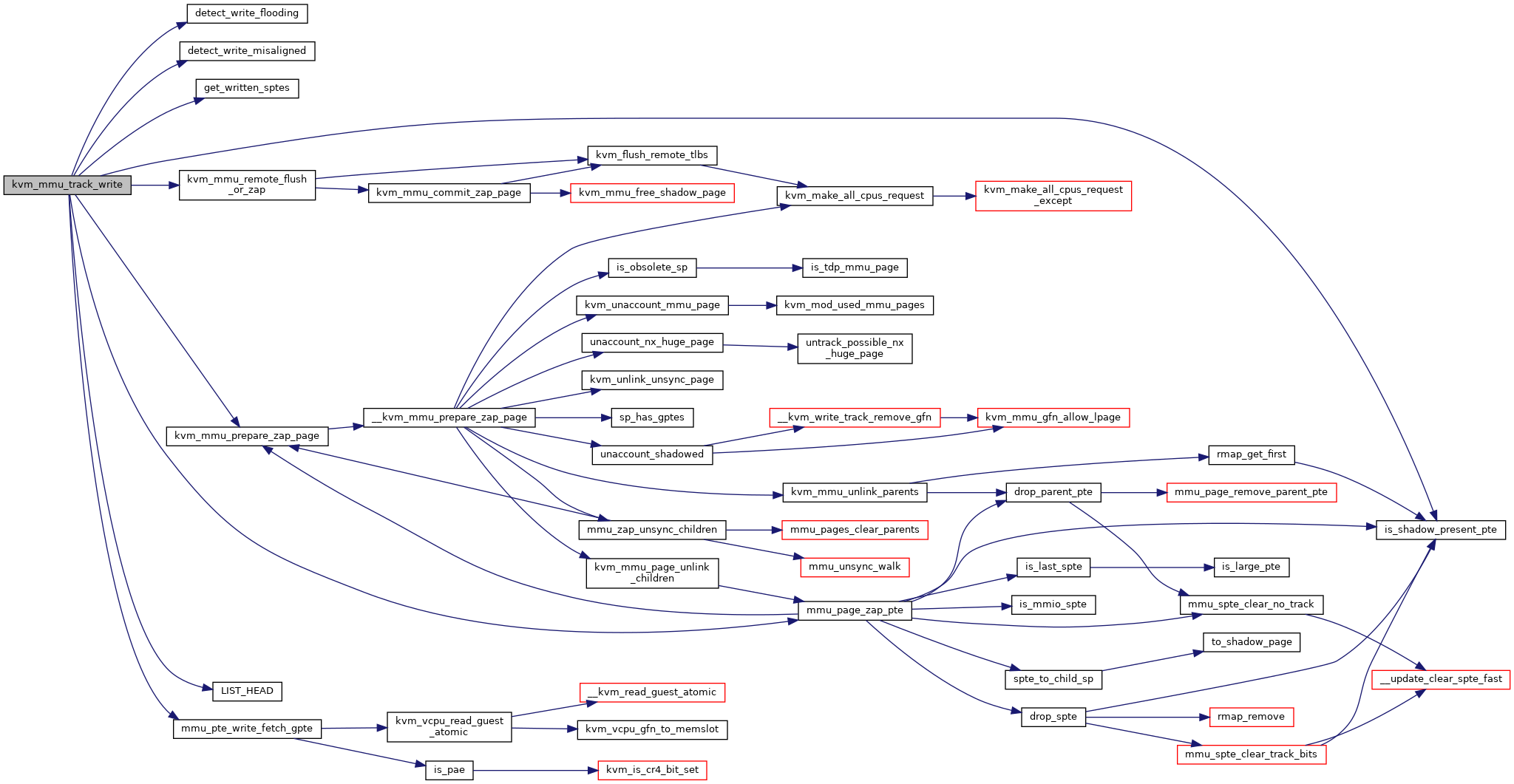
◆ kvm_mmu_track_write()
| void kvm_mmu_track_write | ( | struct kvm_vcpu * | vcpu, |
| gpa_t | gpa, | ||
| const u8 * | new, | ||
| int | bytes | ||
| ) |
Definition at line 5781 of file mmu.c.

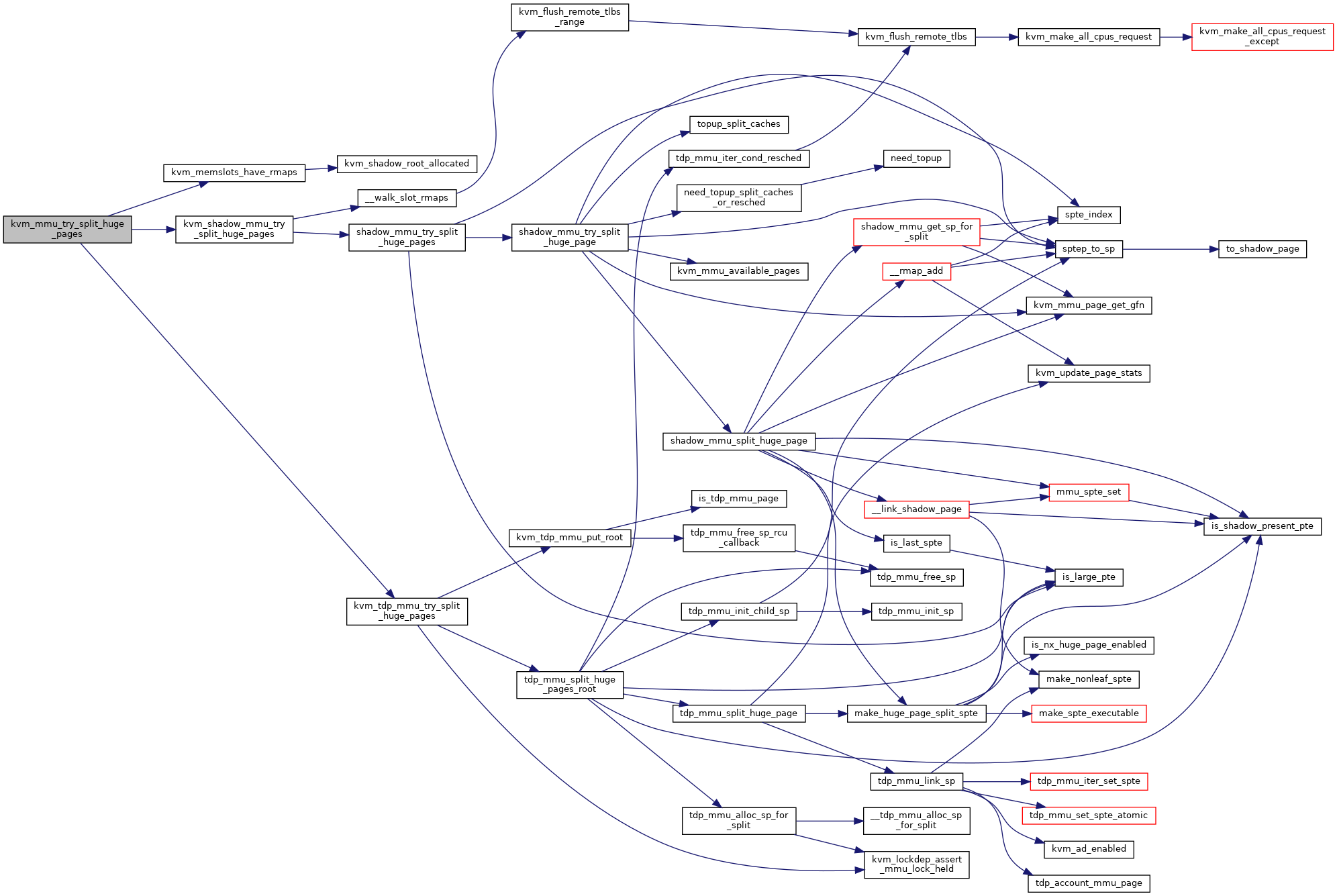
◆ kvm_mmu_try_split_huge_pages()
| void kvm_mmu_try_split_huge_pages | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | memslot, | ||
| u64 | start, | ||
| u64 | end, | ||
| int | target_level | ||
| ) |
◆ kvm_mmu_uninit_vm()
| void kvm_mmu_uninit_vm | ( | struct kvm * | kvm | ) |
Definition at line 6330 of file mmu.c.
◆ kvm_mmu_unlink_parents()
|
static |
Definition at line 2536 of file mmu.c.

◆ kvm_mmu_unload()
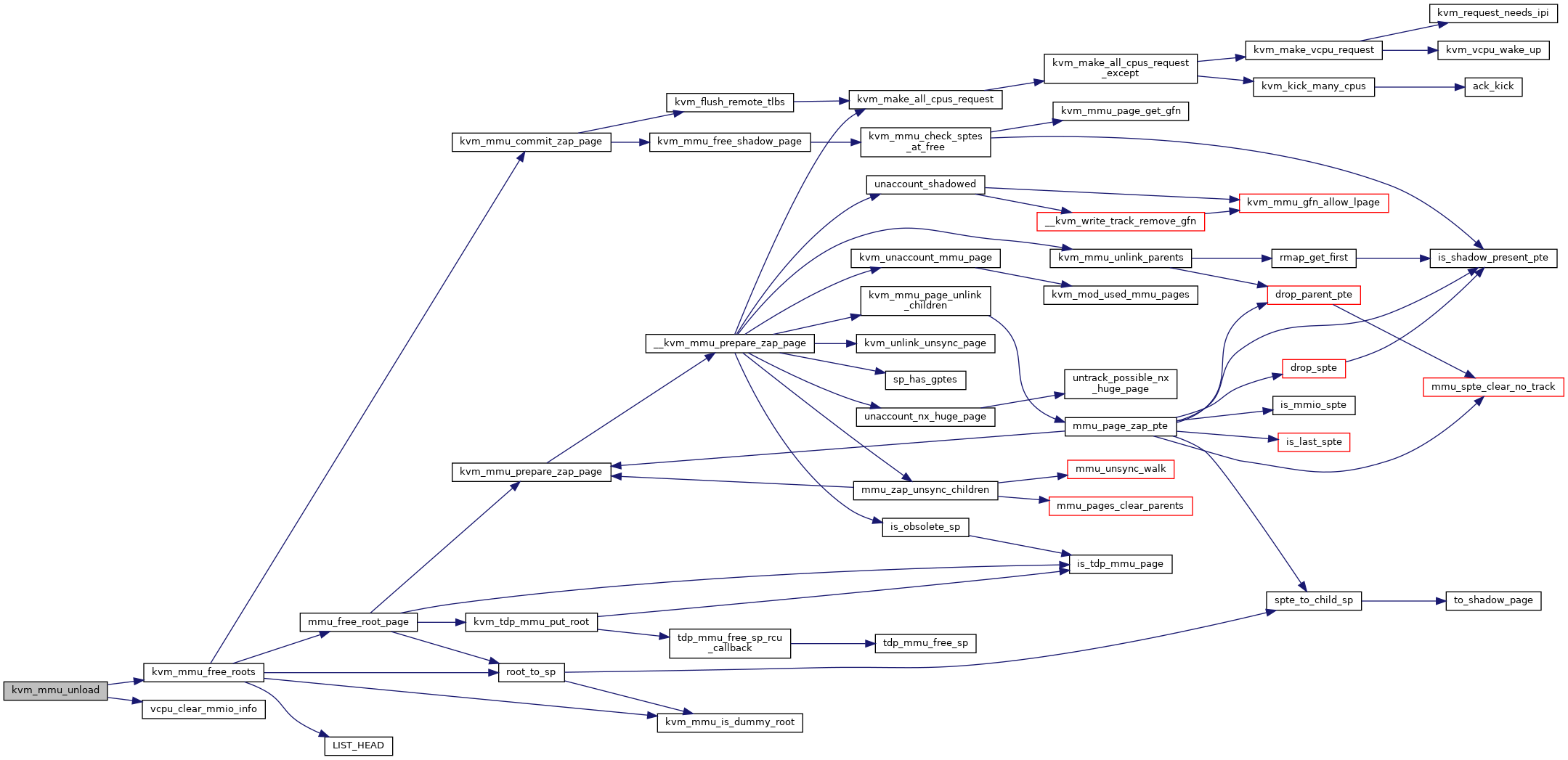
| void kvm_mmu_unload | ( | struct kvm_vcpu * | vcpu | ) |
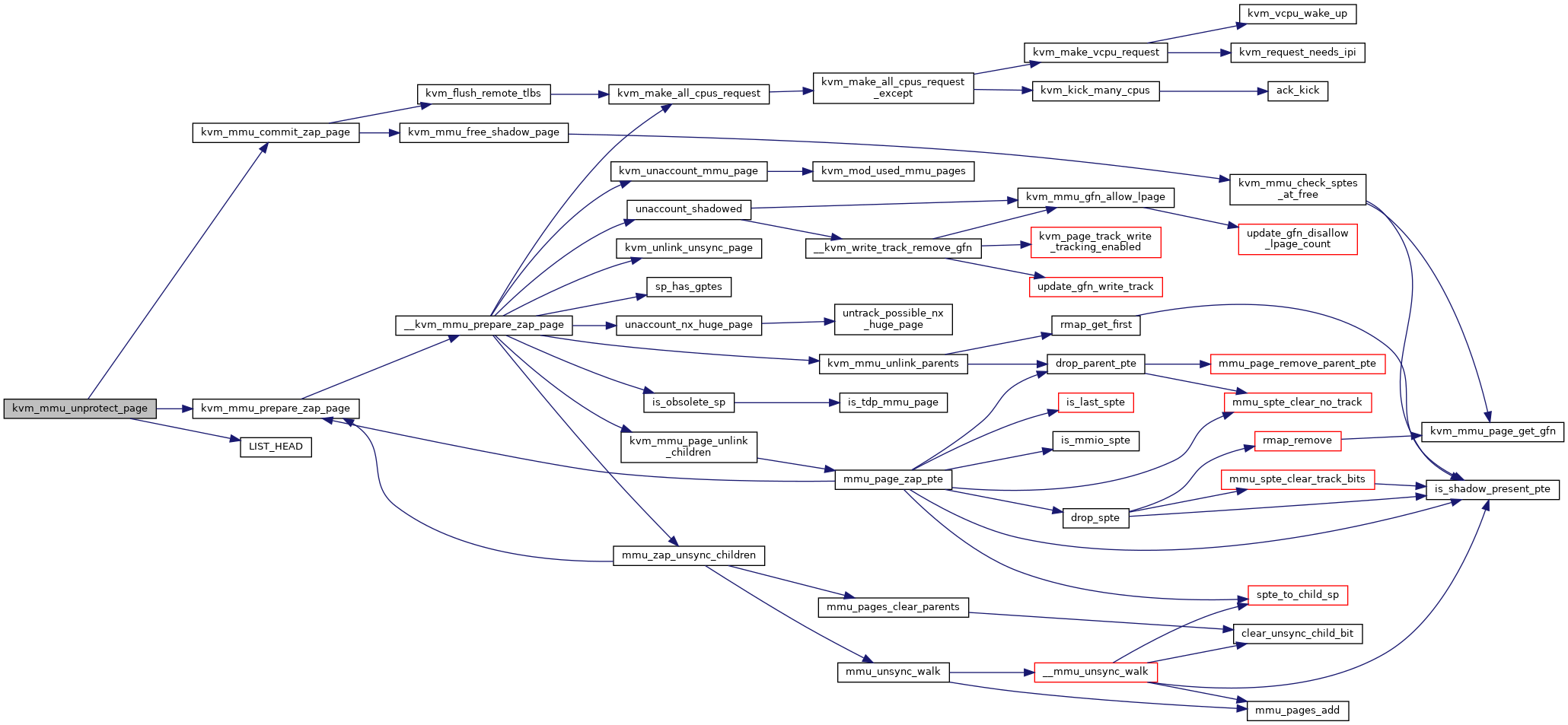
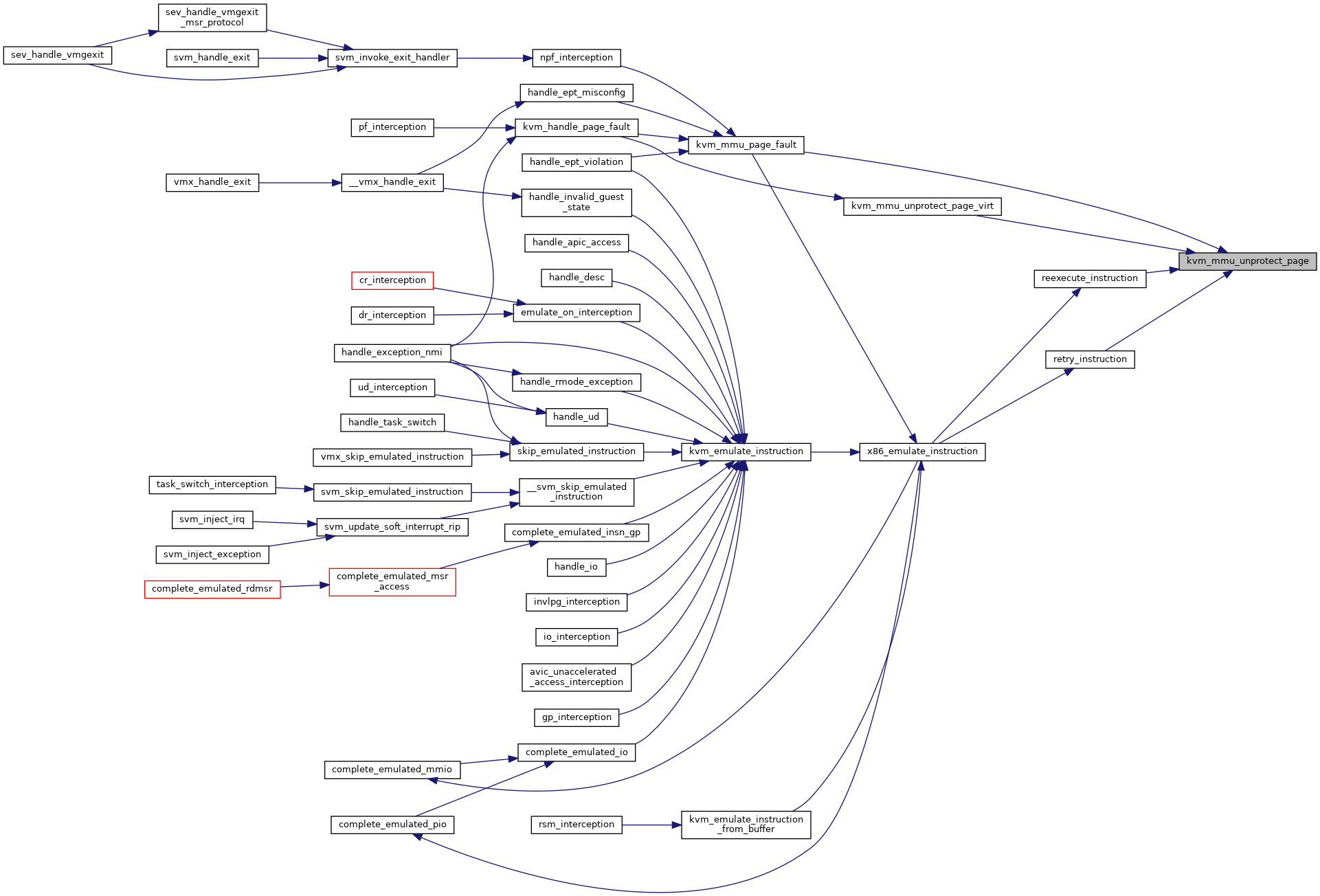
◆ kvm_mmu_unprotect_page()
| int kvm_mmu_unprotect_page | ( | struct kvm * | kvm, |
| gfn_t | gfn | ||
| ) |
◆ kvm_mmu_unprotect_page_virt()
|
static |
Definition at line 2775 of file mmu.c.

◆ kvm_mmu_vendor_module_exit()
| void kvm_mmu_vendor_module_exit | ( | void | ) |

◆ kvm_mmu_vendor_module_init()
| int kvm_mmu_vendor_module_init | ( | void | ) |
Definition at line 7026 of file mmu.c.

◆ kvm_mmu_write_protect_pt_masked()
|
static |
kvm_mmu_write_protect_pt_masked - write protect selected PT level pages @kvm: kvm instance @slot: slot to protect @gfn_offset: start of the BITS_PER_LONG pages we care about @mask: indicates which pages we should protect
Used when we do not need to care about huge page mappings.
Definition at line 1307 of file mmu.c.
◆ kvm_mmu_x86_module_init()
| void __init kvm_mmu_x86_module_init | ( | void | ) |

◆ kvm_mmu_zap_all()
|
static |
◆ kvm_mmu_zap_all_fast()
|
static |
Definition at line 6248 of file mmu.c.
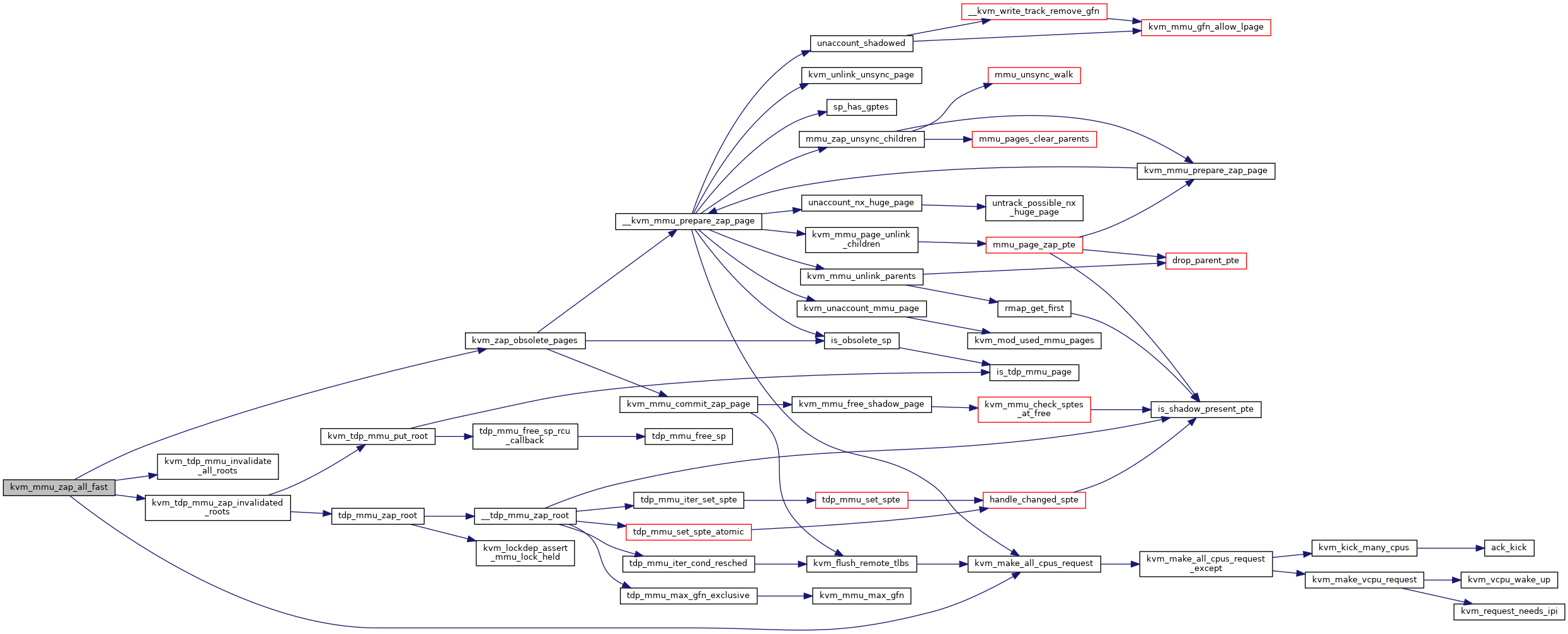

◆ kvm_mmu_zap_collapsible_spte()
|
static |
Definition at line 6704 of file mmu.c.
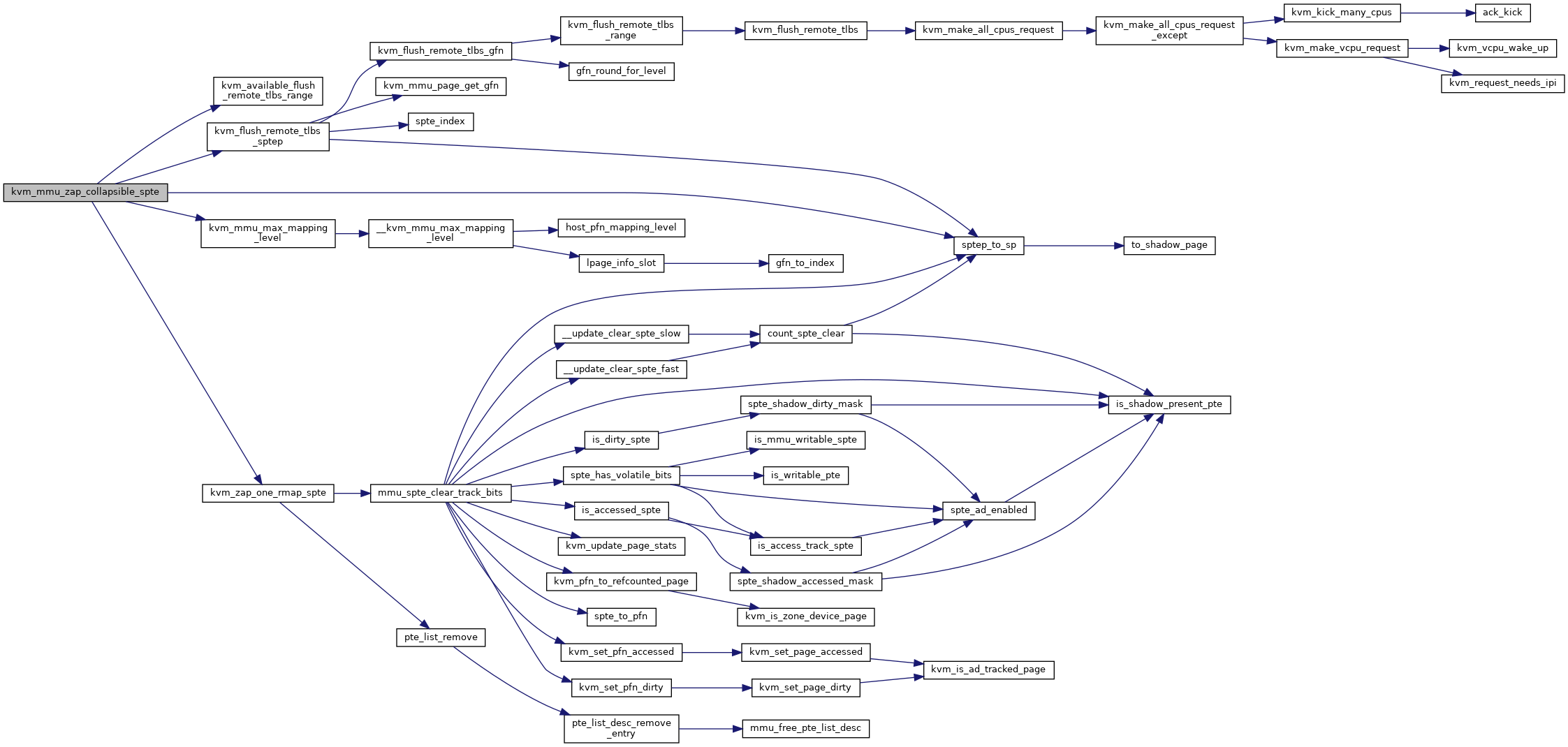

◆ kvm_mmu_zap_collapsible_sptes()
| void kvm_mmu_zap_collapsible_sptes | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot | ||
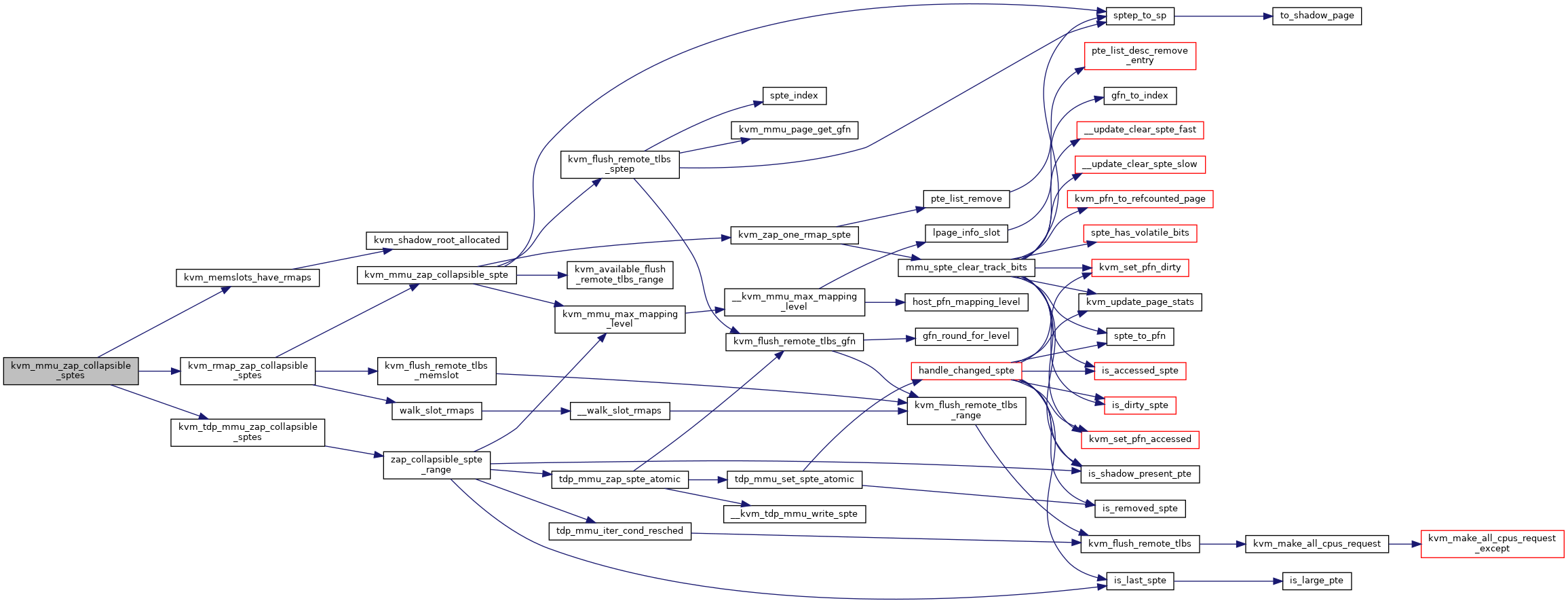
| ) |
Definition at line 6753 of file mmu.c.

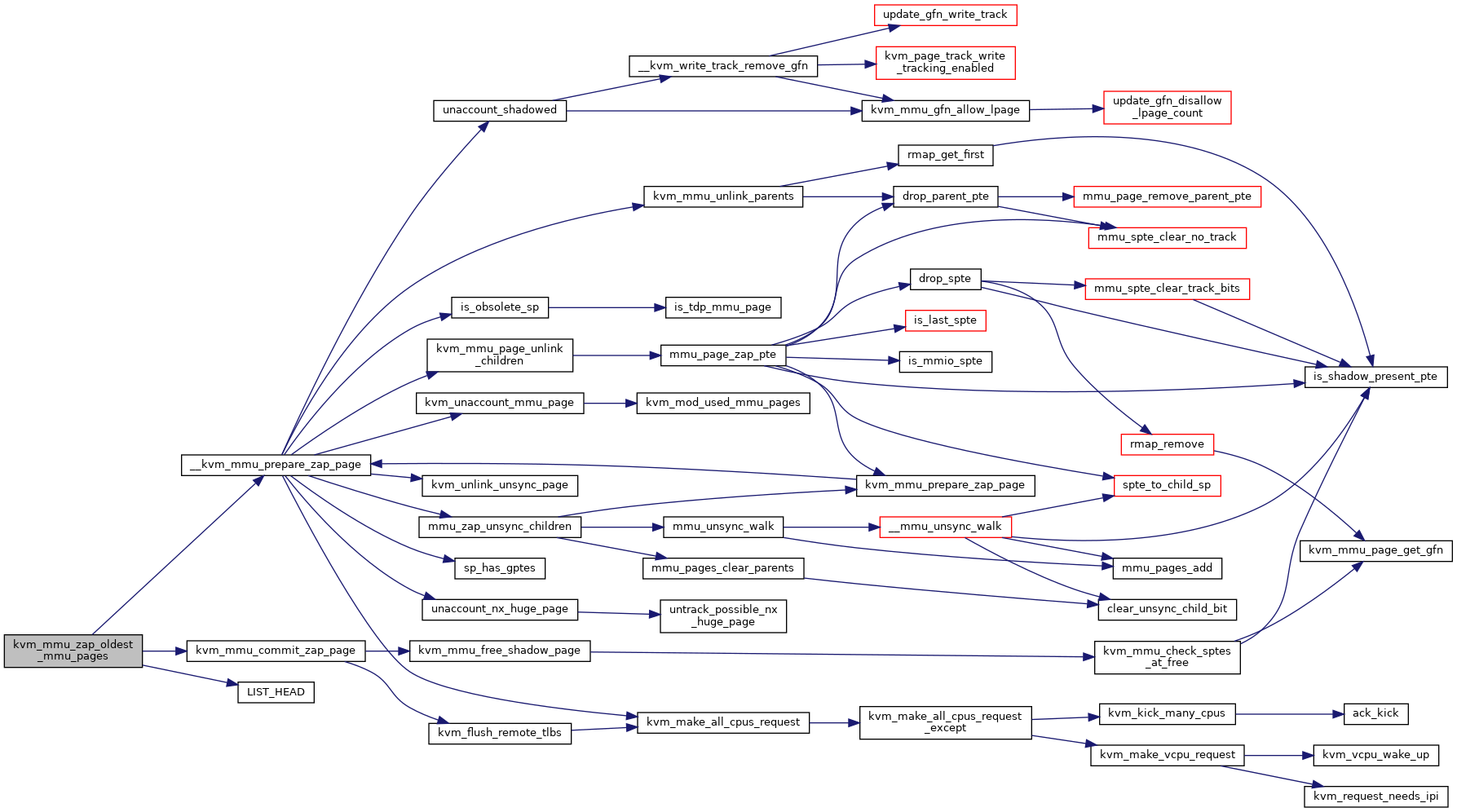
◆ kvm_mmu_zap_oldest_mmu_pages()
|
static |
◆ kvm_mod_used_mmu_pages()
|
inlinestatic |
◆ kvm_nx_huge_page_recovery_worker()
|
static |
Definition at line 7254 of file mmu.c.

◆ kvm_page_table_hashfn()
|
static |
◆ kvm_recover_nx_huge_pages()
|
static |
Definition at line 7148 of file mmu.c.

◆ kvm_rmap_zap_collapsible_sptes()
|
static |
Definition at line 6741 of file mmu.c.

◆ kvm_rmap_zap_gfn_range()
|
static |
Definition at line 6338 of file mmu.c.
◆ kvm_send_hwpoison_signal()
|
static |
Definition at line 3281 of file mmu.c.
◆ kvm_set_pte_rmap()
|
static |
Definition at line 1457 of file mmu.c.

◆ kvm_set_spte_gfn()
| bool kvm_set_spte_gfn | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1599 of file mmu.c.
◆ kvm_shadow_mmu_try_split_huge_pages()
|
static |
Definition at line 6635 of file mmu.c.

◆ kvm_sync_page()
|
static |
Definition at line 1987 of file mmu.c.
◆ kvm_sync_page_check()
|
static |

◆ kvm_sync_spte()
|
static |
◆ kvm_tdp_page_fault()
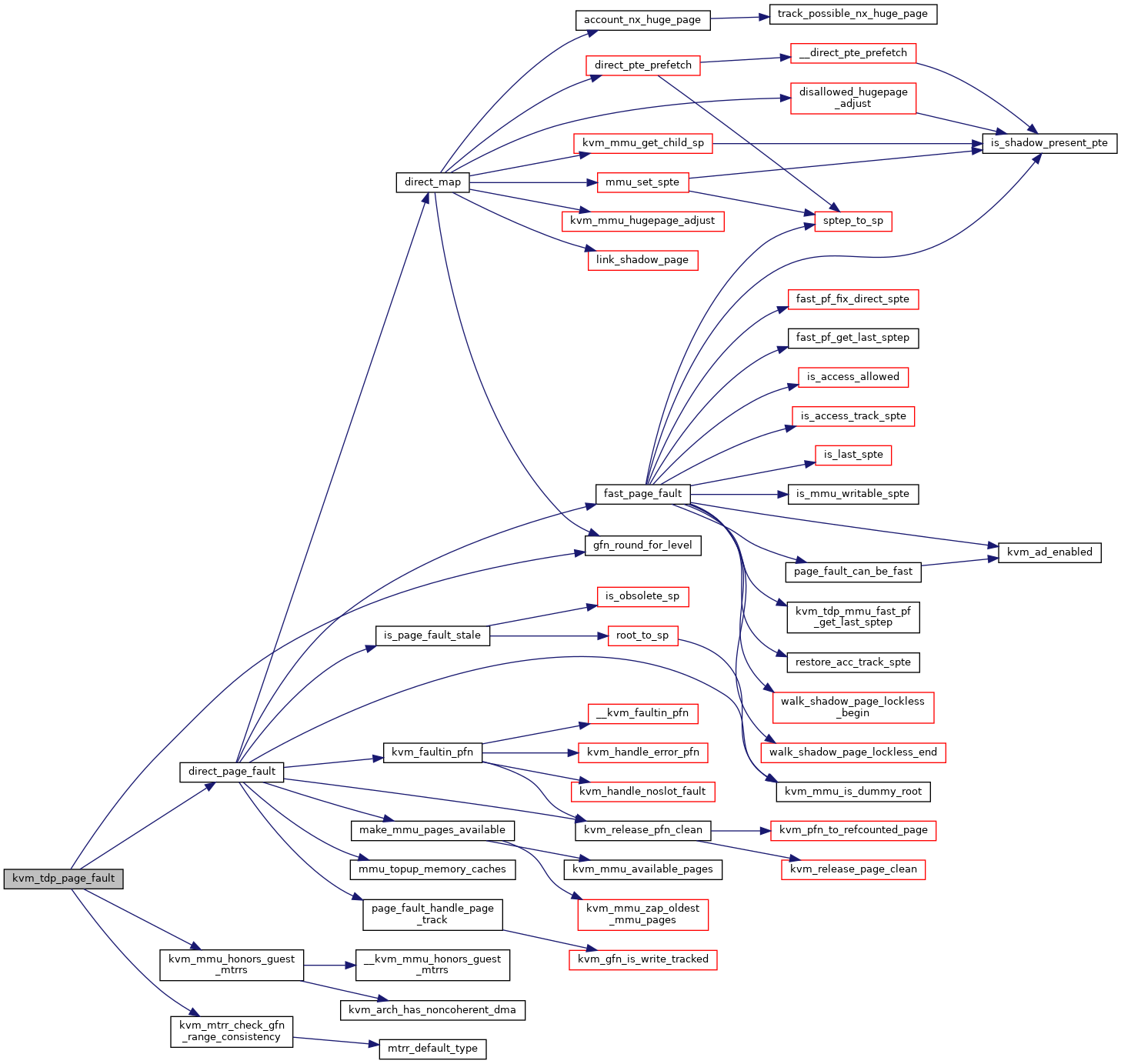
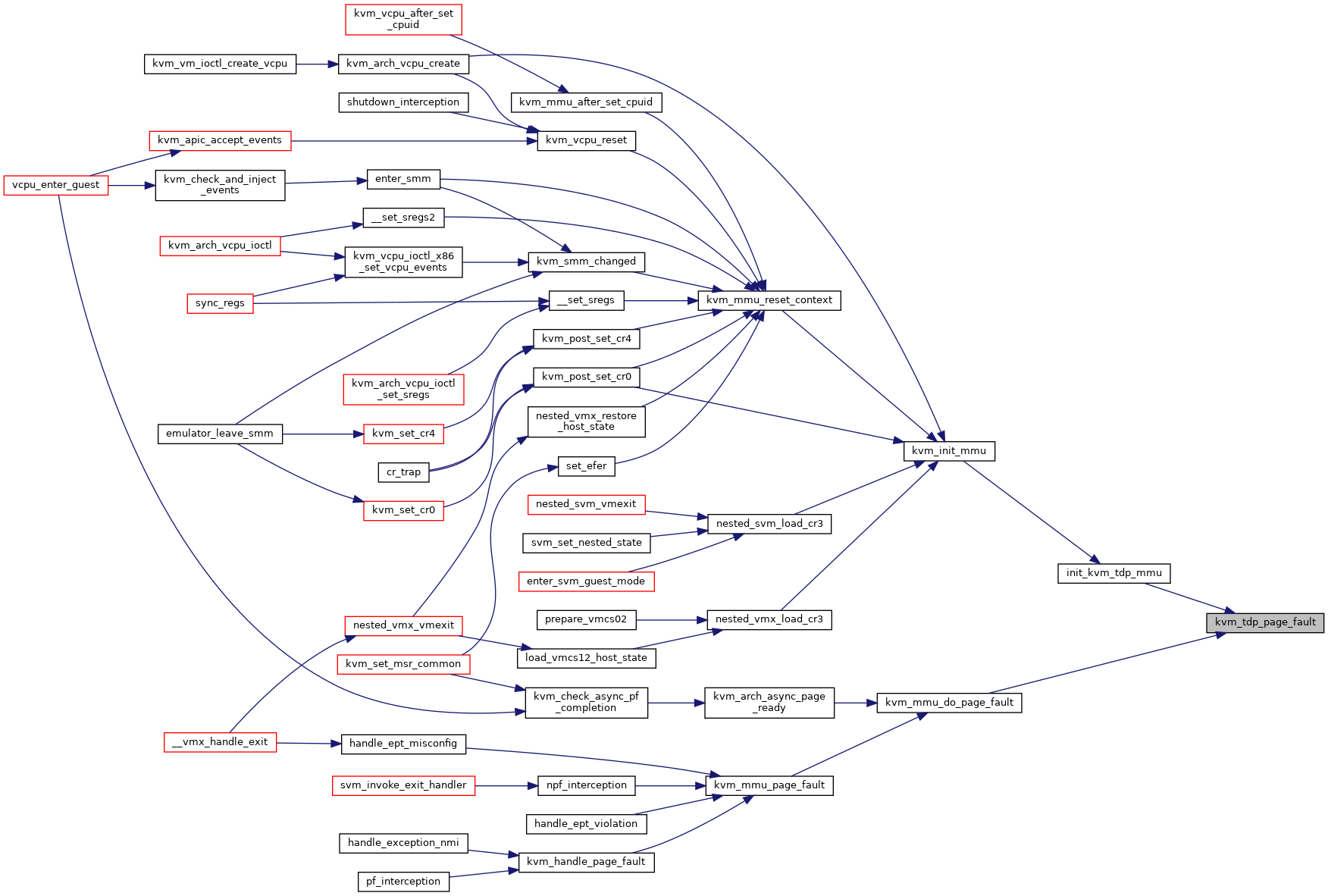
| int kvm_tdp_page_fault | ( | struct kvm_vcpu * | vcpu, |
| struct kvm_page_fault * | fault | ||
| ) |
Definition at line 4623 of file mmu.c.
◆ kvm_test_age_gfn()
| bool kvm_test_age_gfn | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1686 of file mmu.c.

◆ kvm_test_age_rmap()
|
static |


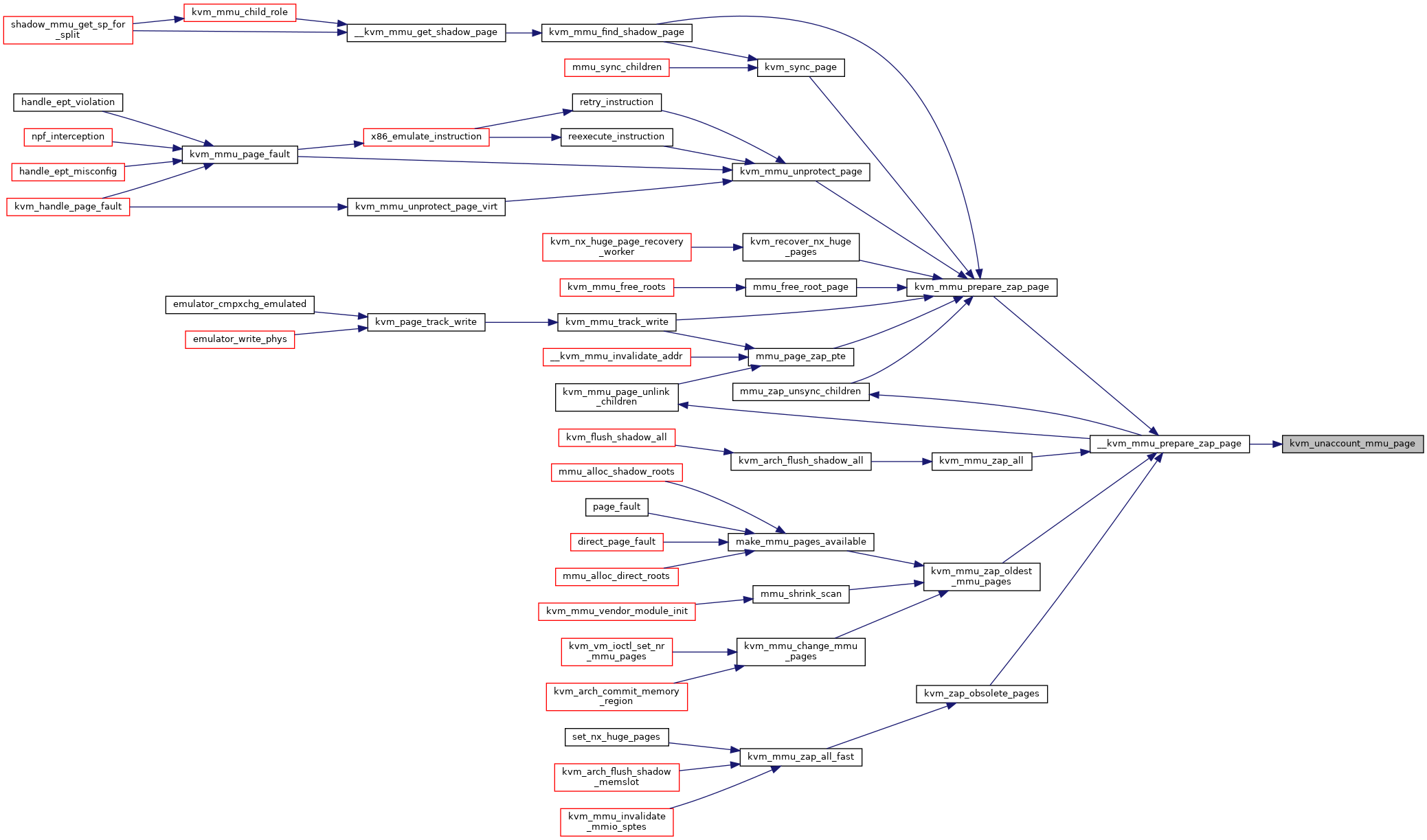
◆ kvm_unaccount_mmu_page()
|
static |

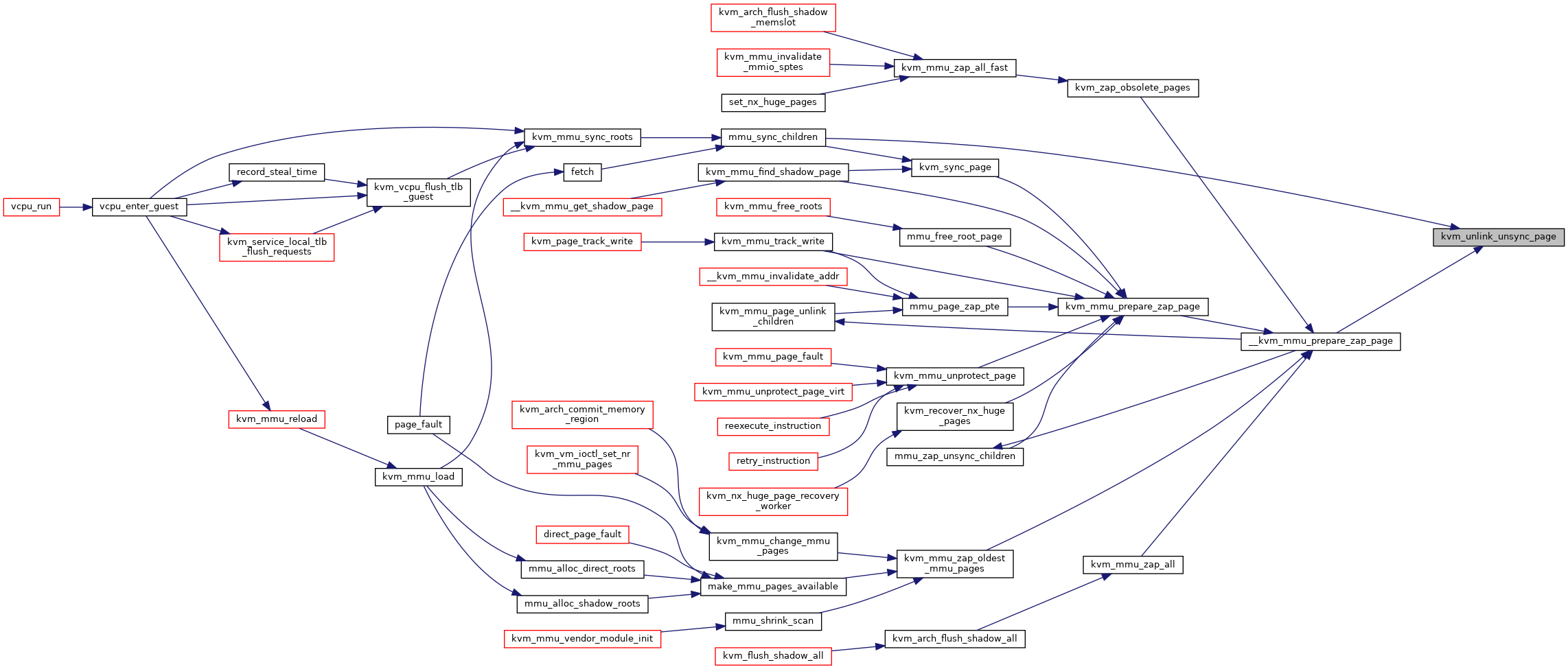
◆ kvm_unlink_unsync_page()
|
static |
◆ kvm_unmap_gfn_range()
| bool kvm_unmap_gfn_range | ( | struct kvm * | kvm, |
| struct kvm_gfn_range * | range | ||
| ) |
Definition at line 1582 of file mmu.c.
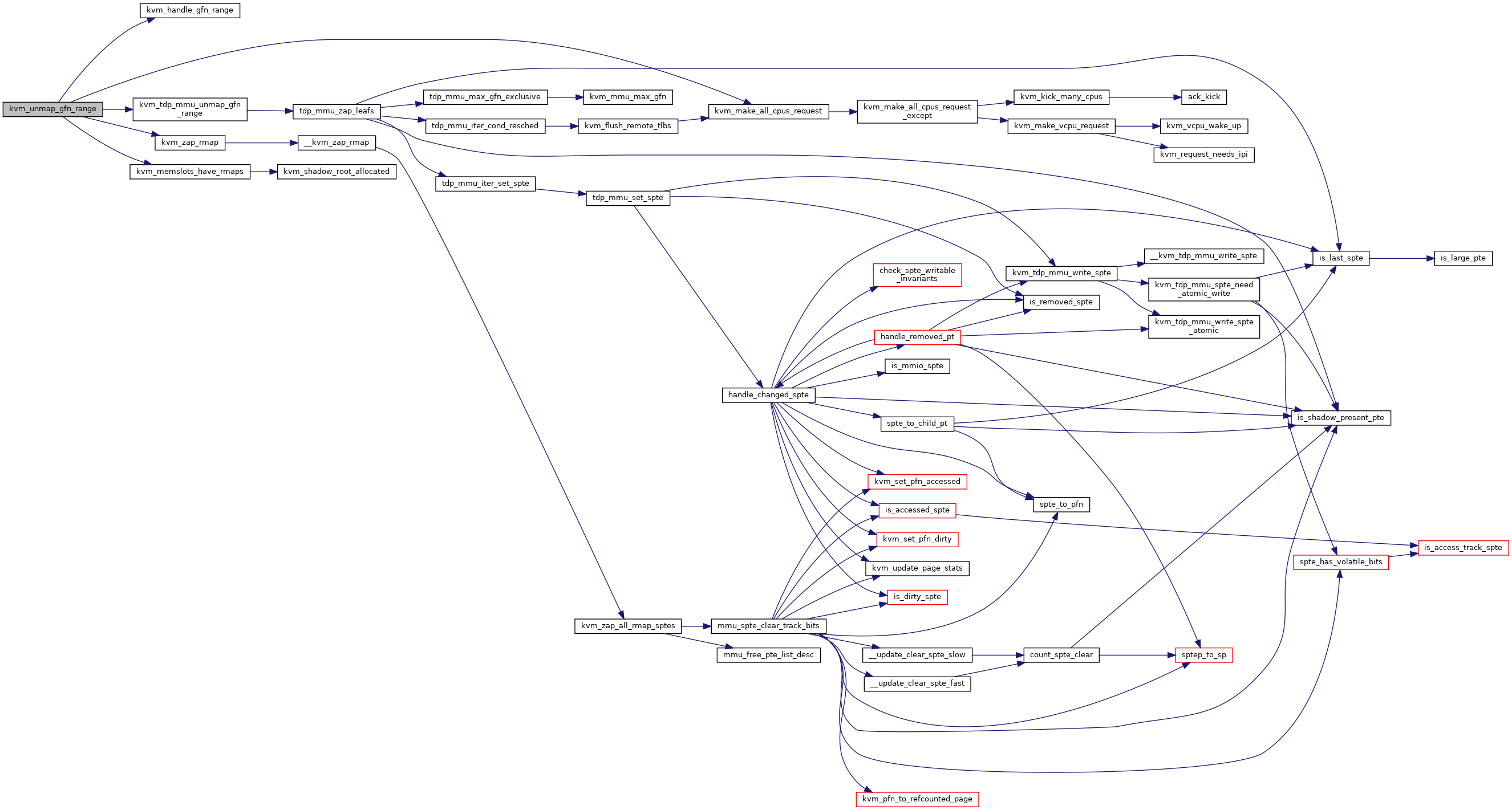
◆ kvm_unsync_page()
|
static |
Definition at line 2790 of file mmu.c.

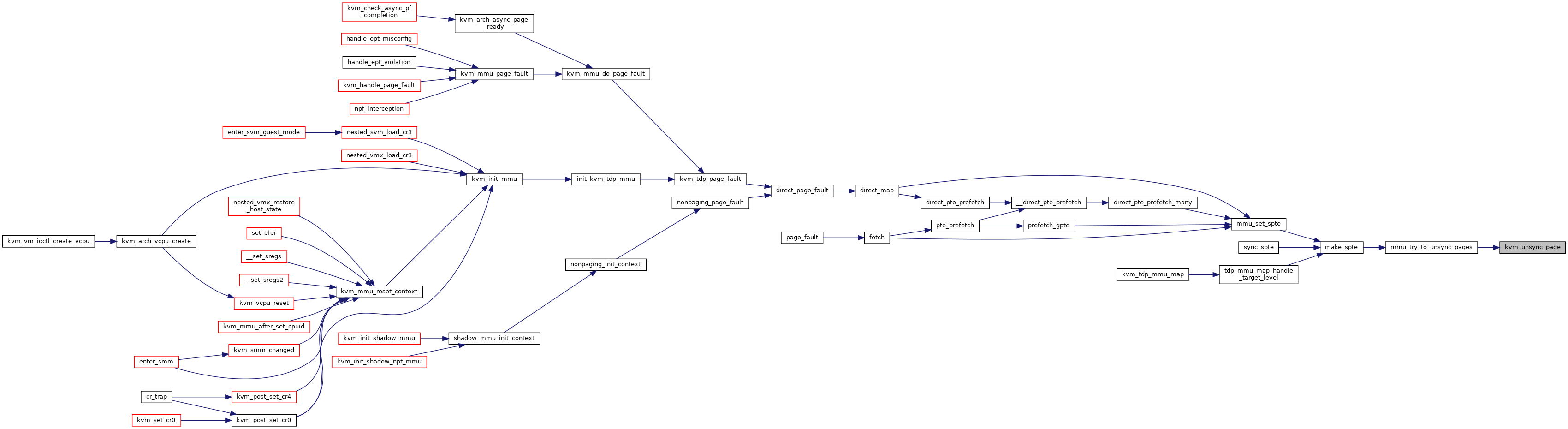
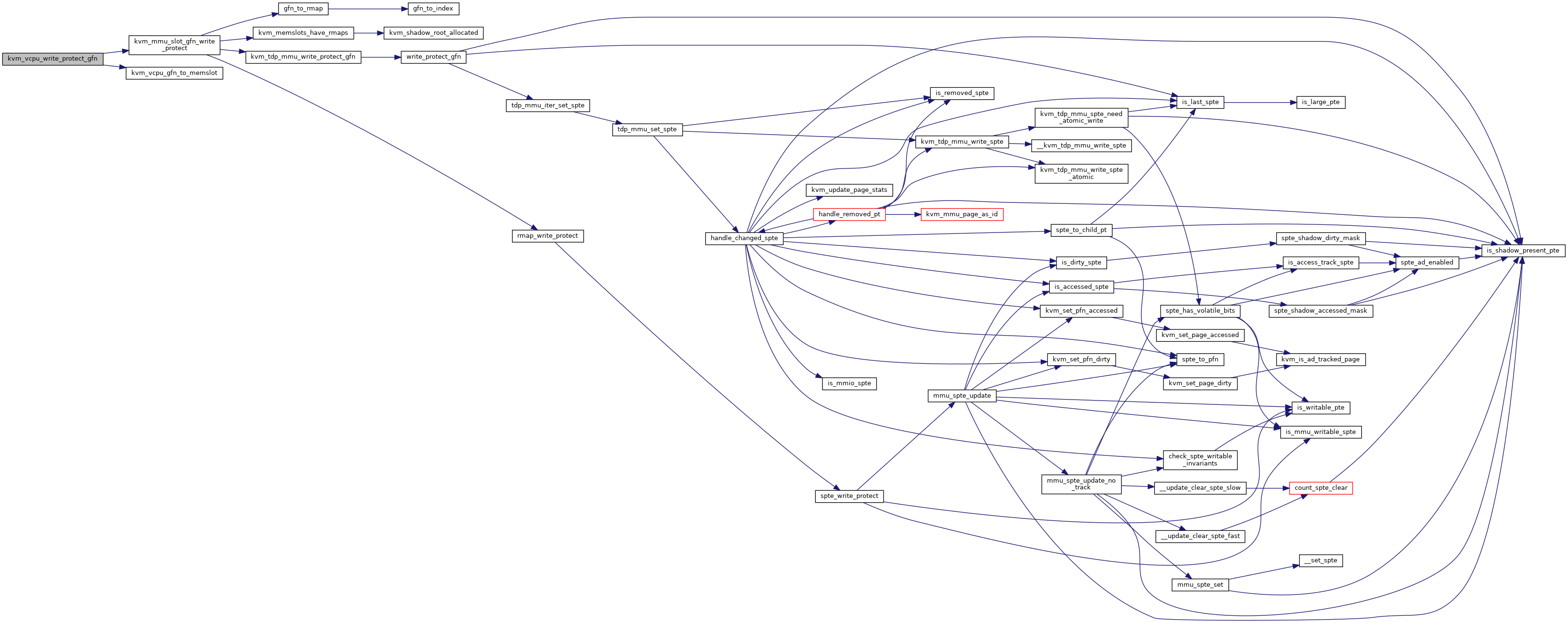
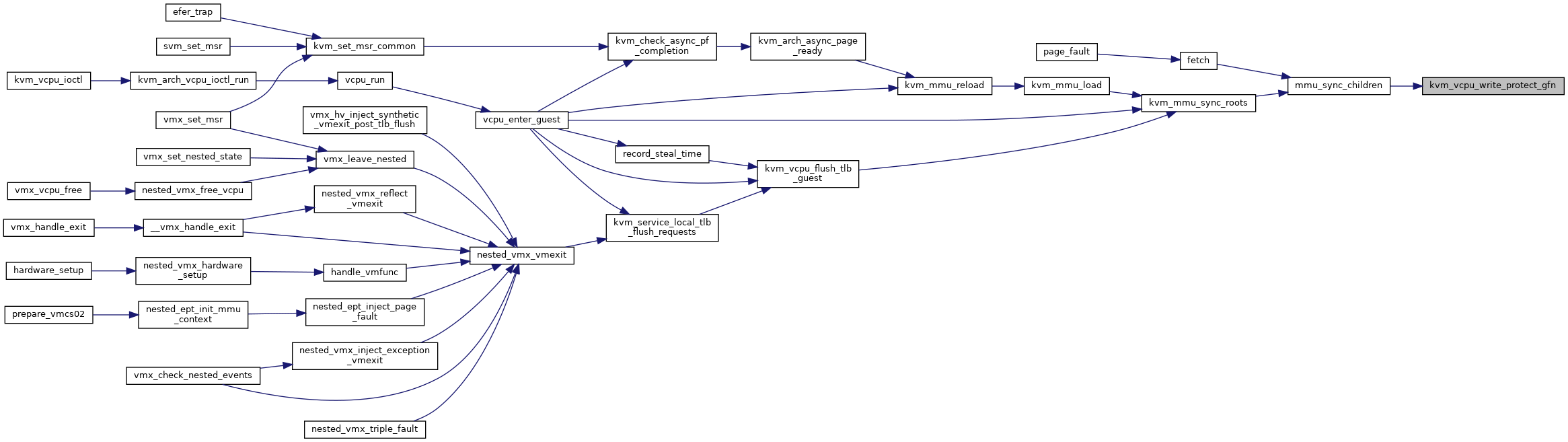
◆ kvm_vcpu_write_protect_gfn()
|
static |
◆ kvm_zap_all_rmap_sptes()
|
static |
◆ kvm_zap_gfn_range()
| void kvm_zap_gfn_range | ( | struct kvm * | kvm, |
| gfn_t | gfn_start, | ||
| gfn_t | gfn_end | ||
| ) |
Definition at line 6373 of file mmu.c.
◆ kvm_zap_obsolete_pages()
|
static |

◆ kvm_zap_one_rmap_spte()
|
static |
Definition at line 1037 of file mmu.c.

◆ kvm_zap_rmap()
|
static |

◆ link_shadow_page()
|
static |
Definition at line 2464 of file mmu.c.
◆ lpage_info_slot()
|
static |

◆ make_mmu_pages_available()
|
static |
Definition at line 2714 of file mmu.c.
◆ mark_mmio_spte()
|
static |
◆ mark_unsync()
|
static |
◆ mmio_info_in_cache()
|
static |
Definition at line 4084 of file mmu.c.

◆ mmu_alloc_direct_roots()
|
static |
Definition at line 3688 of file mmu.c.

◆ mmu_alloc_root()
|
static |


◆ mmu_alloc_shadow_roots()
|
static |
Definition at line 3796 of file mmu.c.

◆ mmu_alloc_special_roots()
|
static |

◆ mmu_destroy_caches()
|
static |

◆ mmu_first_shadow_root_alloc()
|
static |
Definition at line 3735 of file mmu.c.

◆ mmu_free_memory_caches()
|
static |
◆ mmu_free_pte_list_desc()
|
static |
◆ mmu_free_root_page()
|
static |
Definition at line 3566 of file mmu.c.
◆ mmu_free_vm_memory_caches()
|
static |
◆ mmu_page_add_parent_pte()
|
static |

◆ mmu_page_remove_parent_pte()
|
static |

◆ mmu_page_zap_pte()
|
static |
◆ mmu_pages_add()
|
static |
◆ mmu_pages_clear_parents()
|
static |

◆ mmu_pages_first()
|
static |

◆ mmu_pages_next()
|
static |

◆ mmu_pte_write_fetch_gpte()
|
static |
Definition at line 5682 of file mmu.c.


◆ mmu_set_spte()
|
static |
Definition at line 2906 of file mmu.c.
◆ mmu_shrink_count()
|
static |

◆ mmu_shrink_scan()
|
static |
Definition at line 6859 of file mmu.c.

◆ mmu_spte_age()
|
static |
◆ mmu_spte_clear_no_track()
|
static |

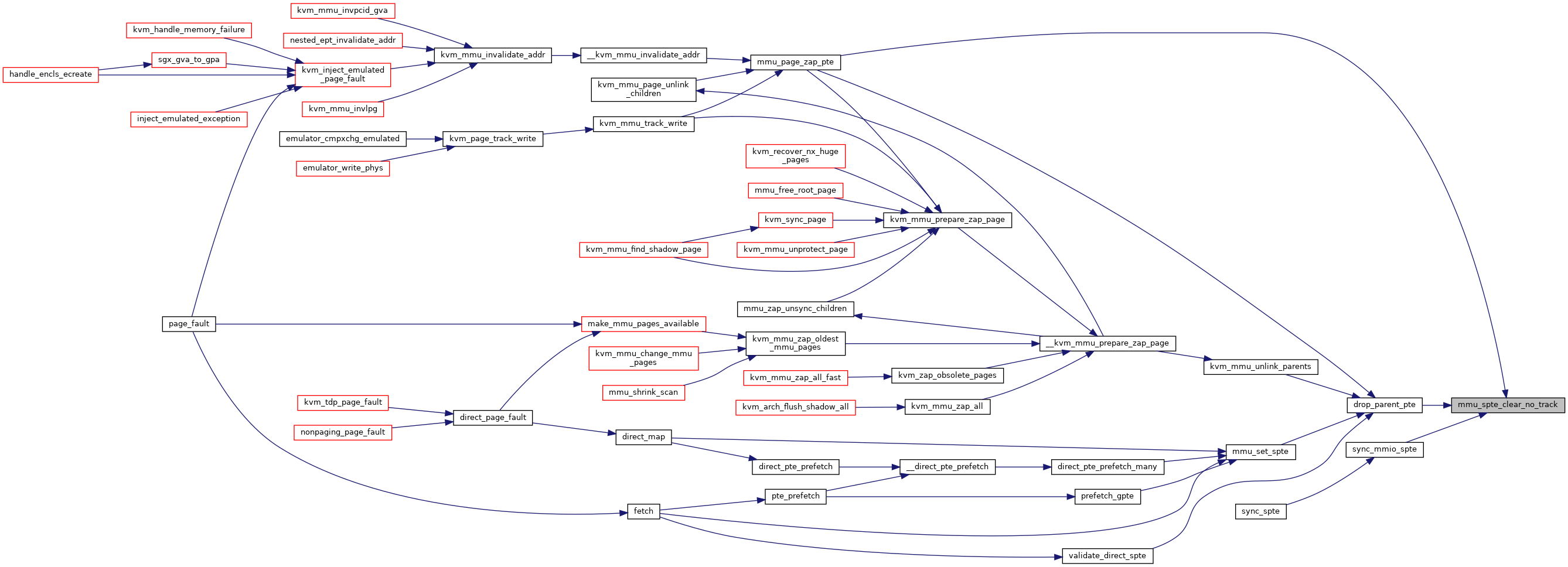
◆ mmu_spte_clear_track_bits()
|
static |
Definition at line 561 of file mmu.c.
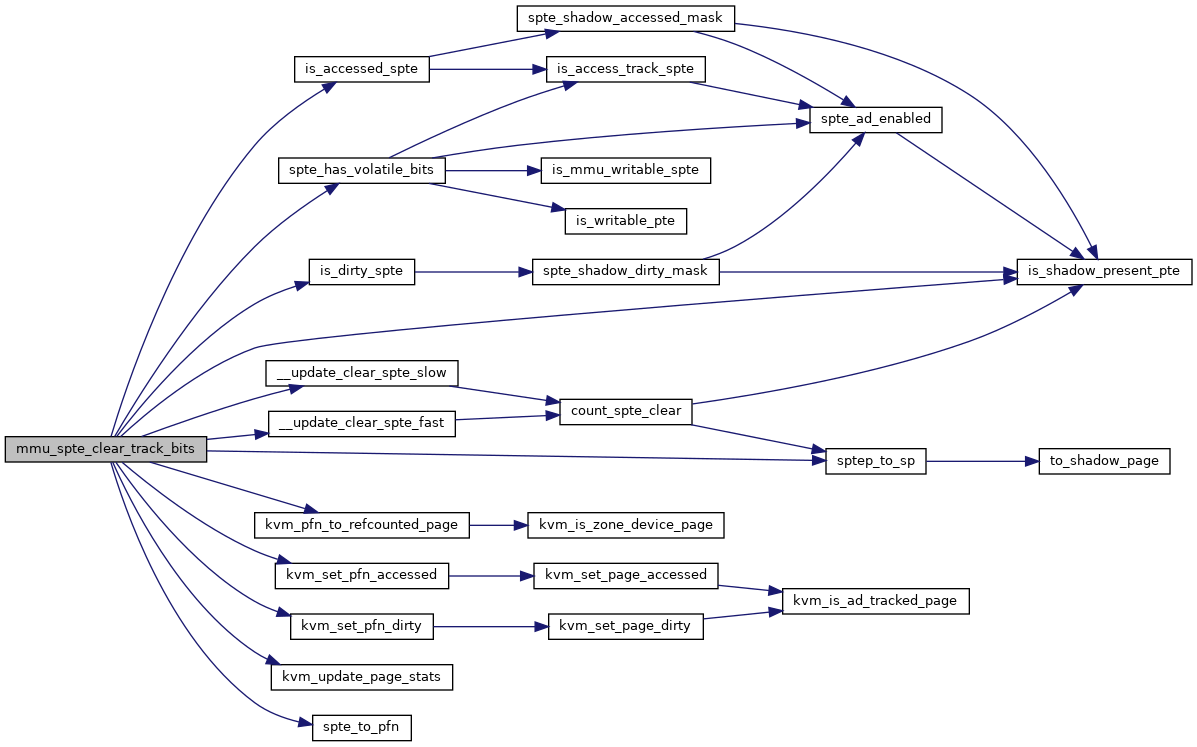
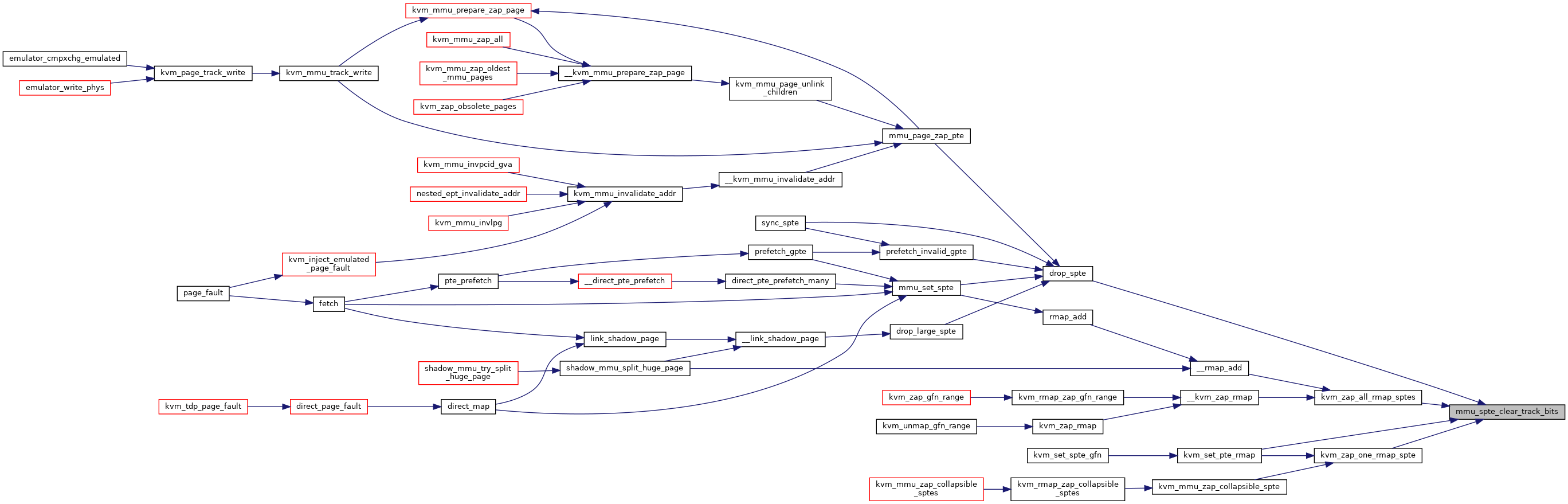
◆ mmu_spte_get_lockless()
|
static |


◆ mmu_spte_set()
|
static |
◆ mmu_spte_update()
|
static |
◆ mmu_spte_update_no_track()
|
static |
Definition at line 489 of file mmu.c.
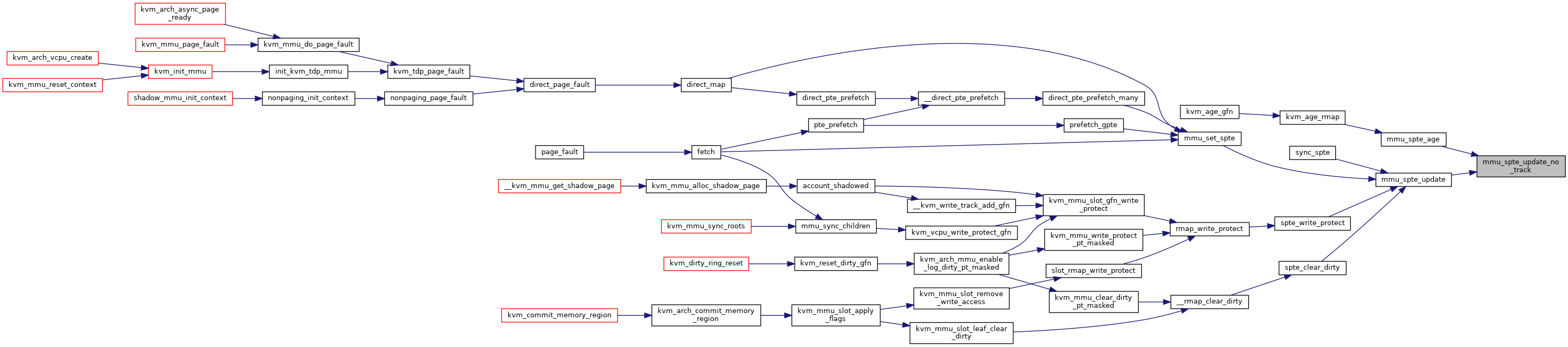
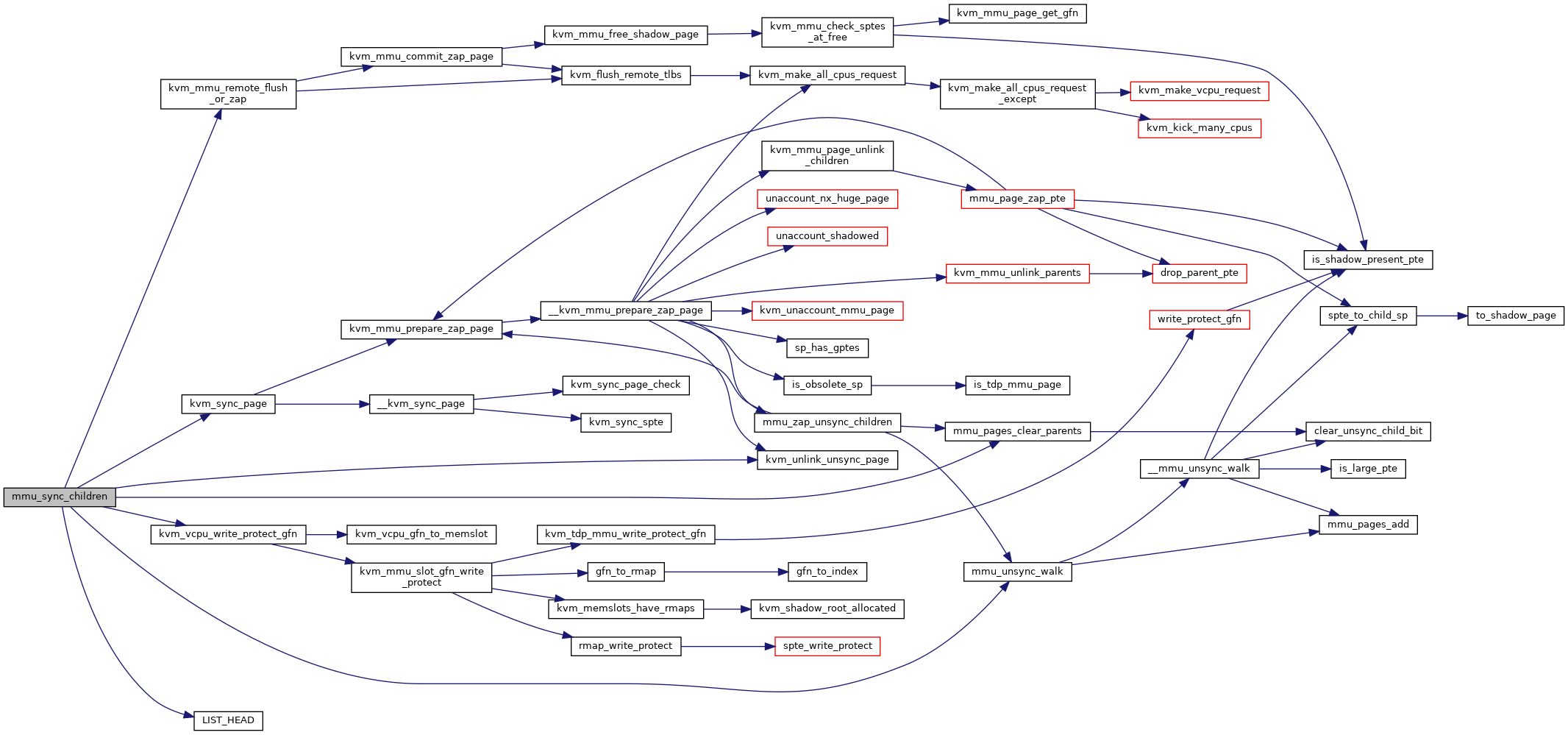
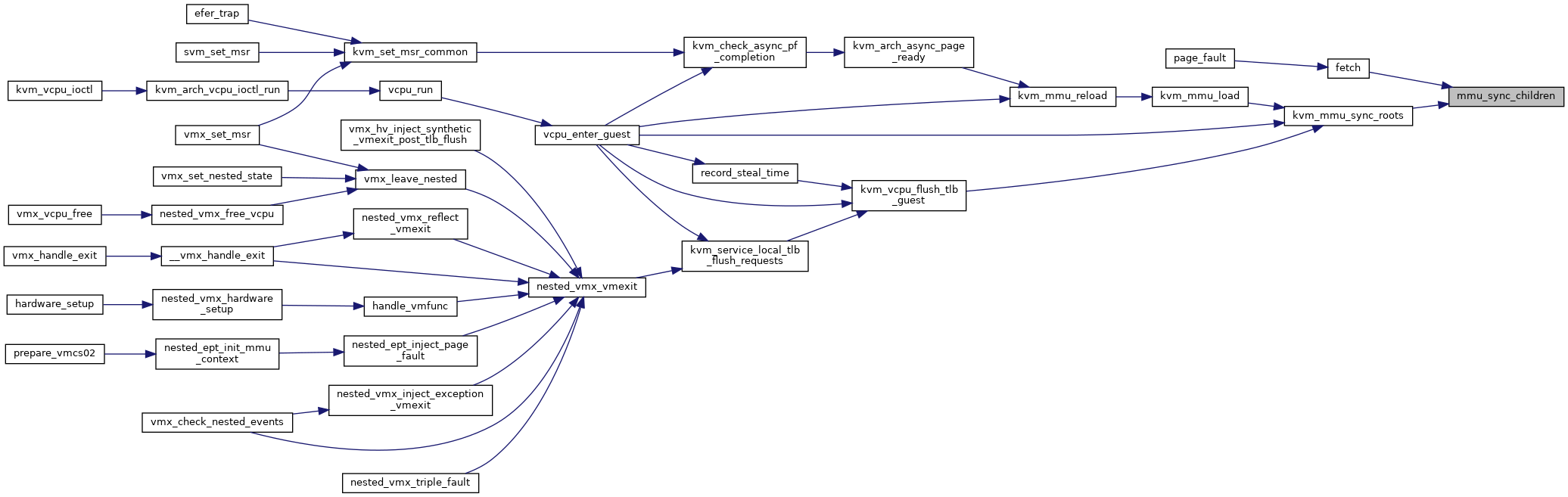
◆ mmu_sync_children()
|
static |
Definition at line 2093 of file mmu.c.
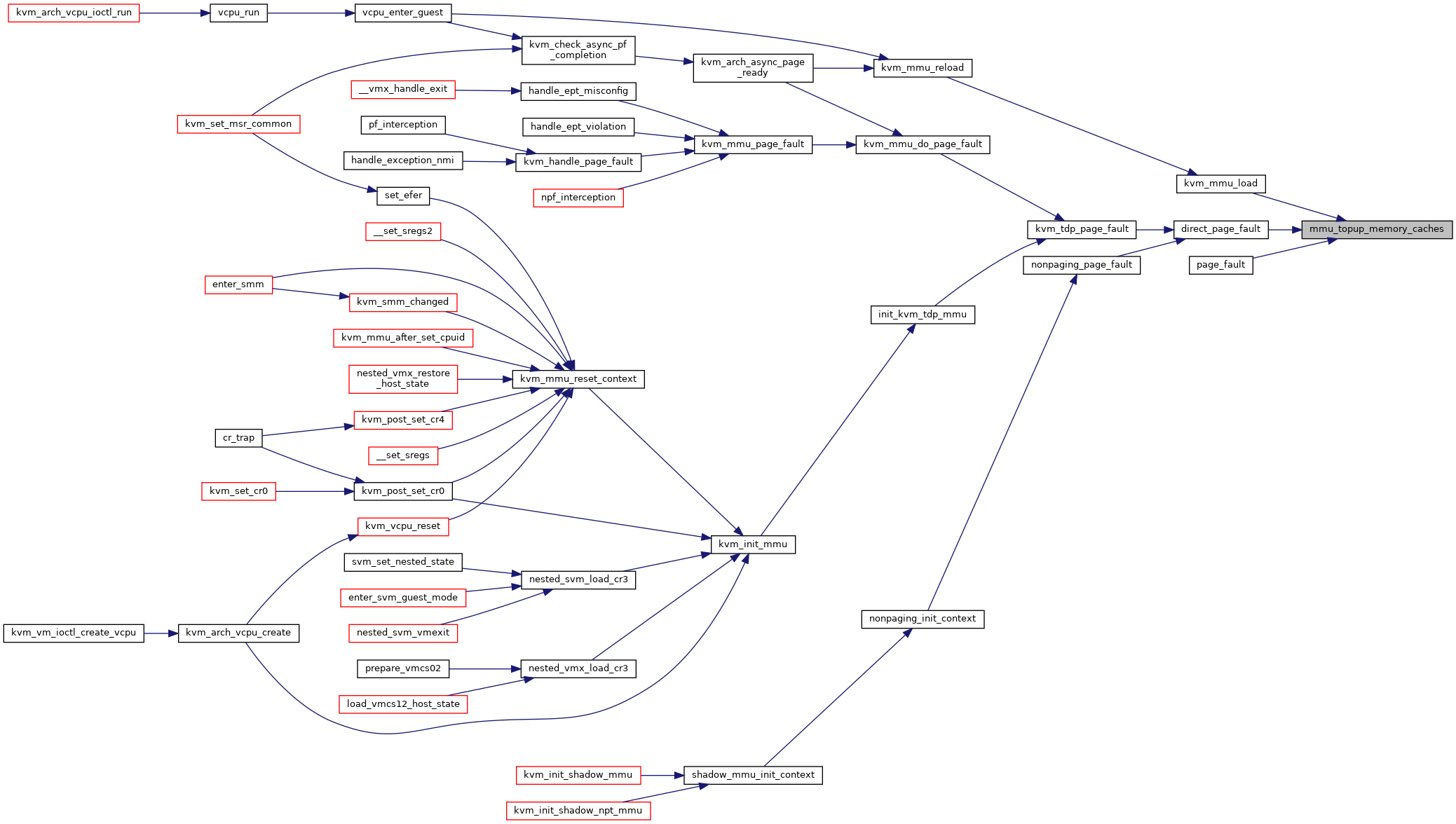
◆ mmu_topup_memory_caches()
|
static |
◆ mmu_try_to_unsync_pages()
| int mmu_try_to_unsync_pages | ( | struct kvm * | kvm, |
| const struct kvm_memory_slot * | slot, | ||
| gfn_t | gfn, | ||
| bool | can_unsync, | ||
| bool | prefetch | ||
| ) |
Definition at line 2805 of file mmu.c.

◆ mmu_unsync_walk()
|
static |
◆ mmu_zap_unsync_children()
|
static |
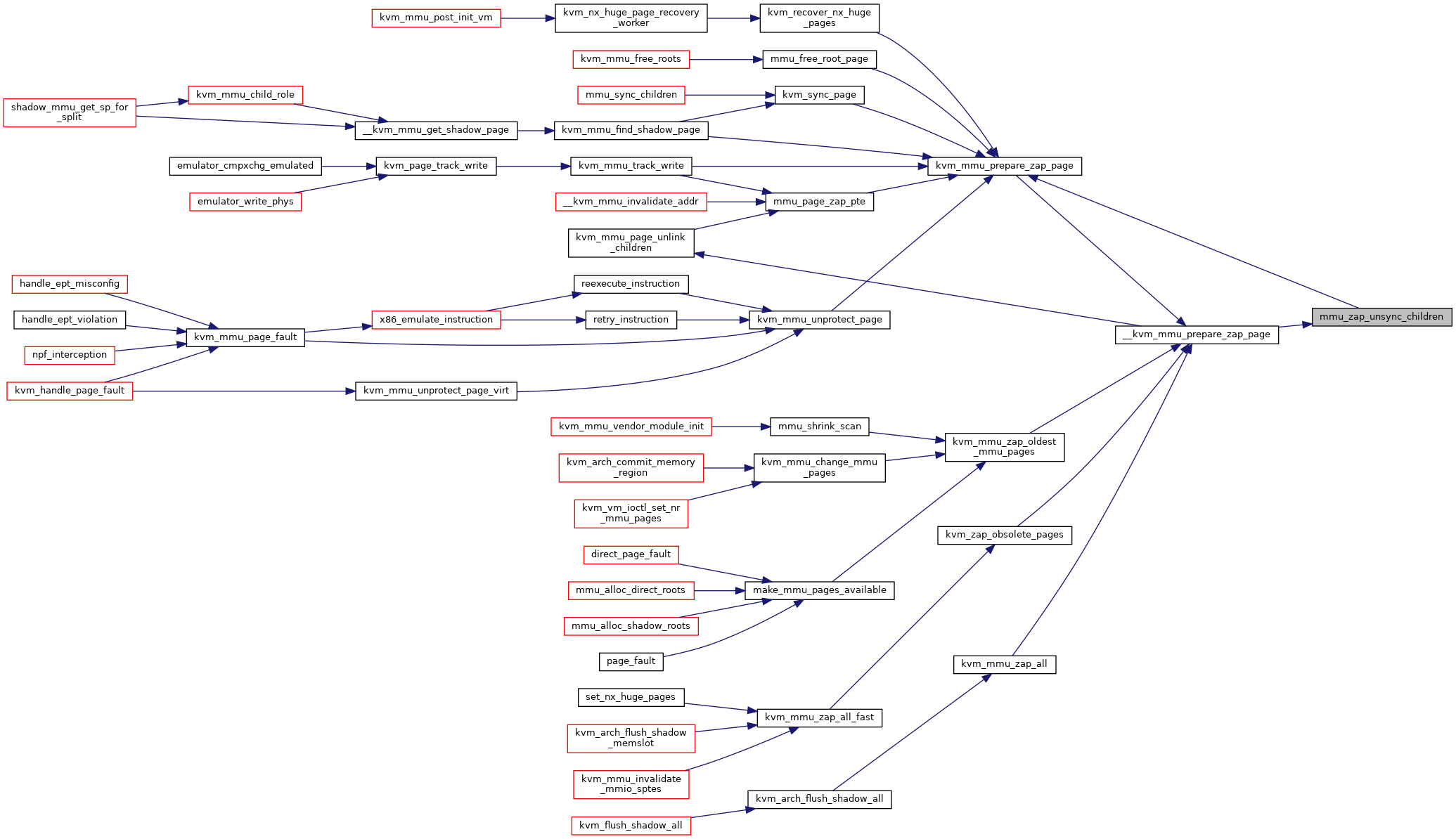
◆ module_param_cb() [1/3]
| module_param_cb | ( | nx_huge_pages | , |
| & | nx_huge_pages_ops, | ||
| & | nx_huge_pages, | ||
| 0644 | |||
| ) |
◆ module_param_cb() [2/3]
| module_param_cb | ( | nx_huge_pages_recovery_period_ms | , |
| & | nx_huge_pages_recovery_param_ops, | ||
| & | nx_huge_pages_recovery_period_ms, | ||
| 0644 | |||
| ) |
◆ module_param_cb() [3/3]
| module_param_cb | ( | nx_huge_pages_recovery_ratio | , |
| & | nx_huge_pages_recovery_param_ops, | ||
| & | nx_huge_pages_recovery_ratio, | ||
| 0644 | |||
| ) |
◆ module_param_named()
| module_param_named | ( | flush_on_reuse | , |
| force_flush_and_sync_on_reuse | , | ||
| bool | , | ||
| 0644 | |||
| ) |
◆ need_topup()
|
inlinestatic |

◆ need_topup_split_caches_or_resched()
|
static |


◆ nonpaging_gva_to_gpa()
|
static |

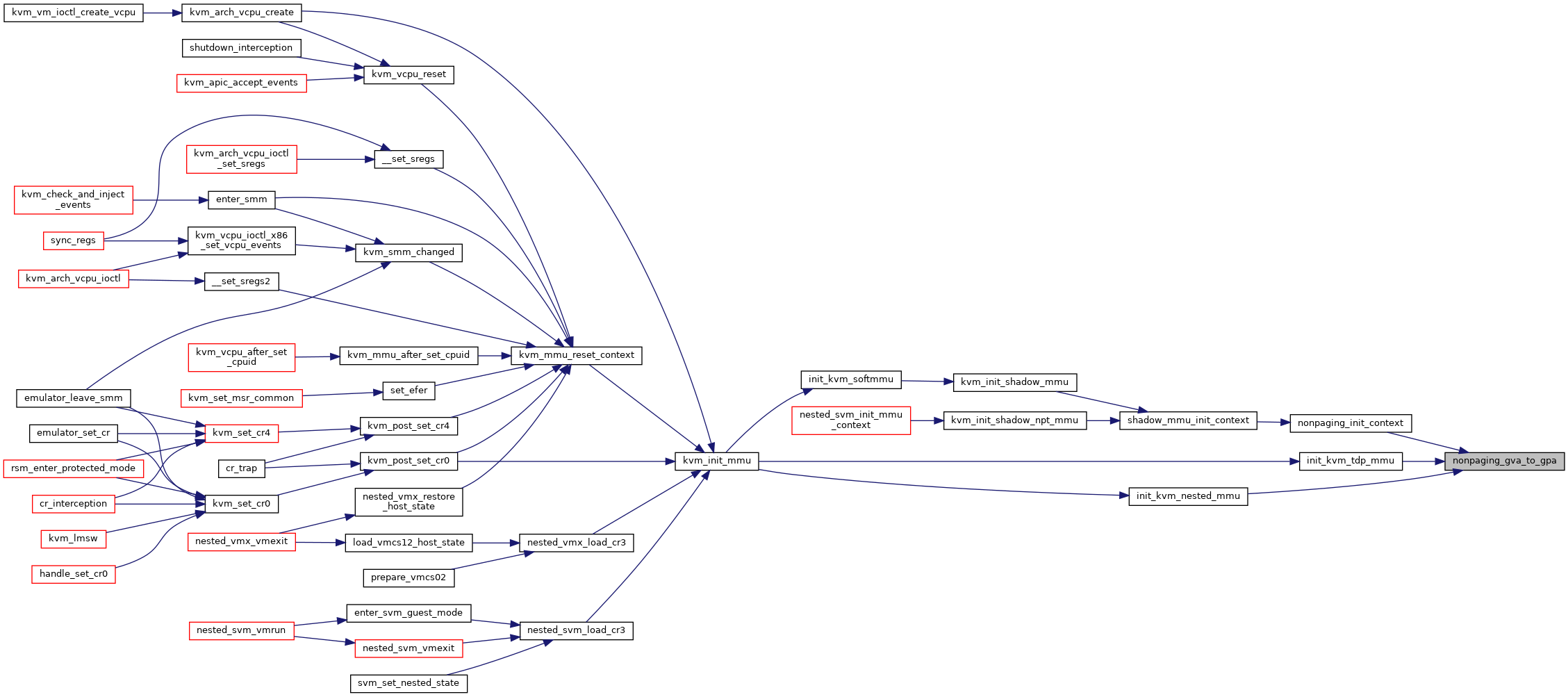
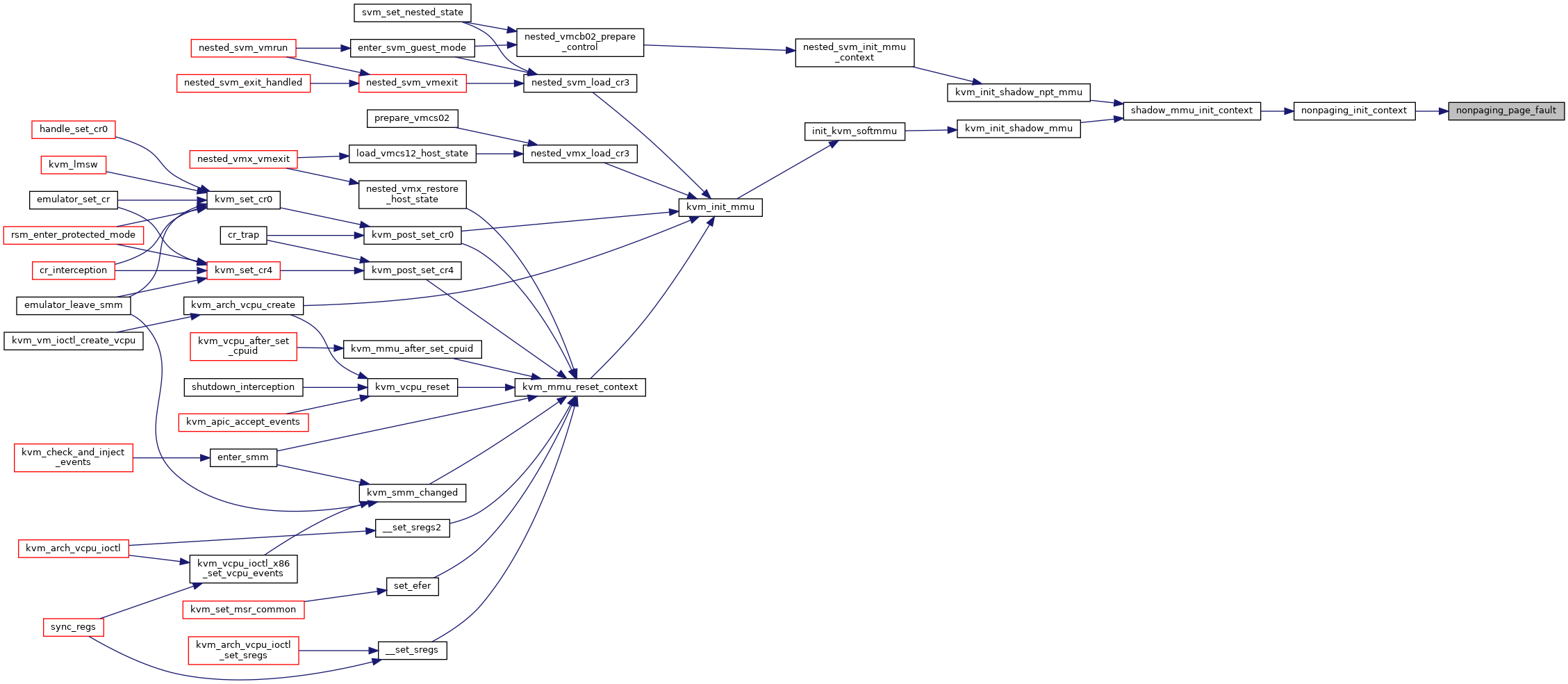
◆ nonpaging_init_context()
|
static |
Definition at line 4649 of file mmu.c.
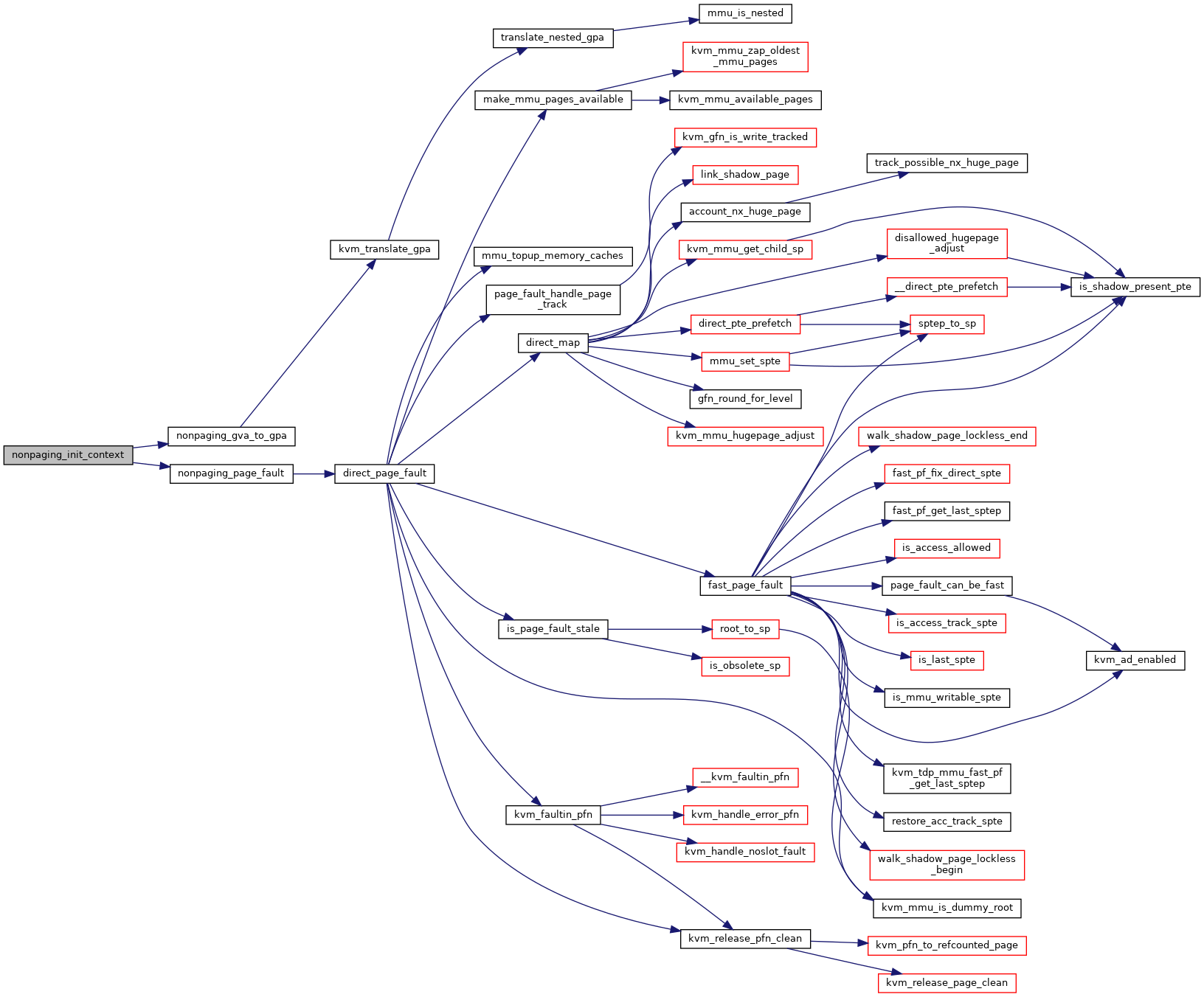
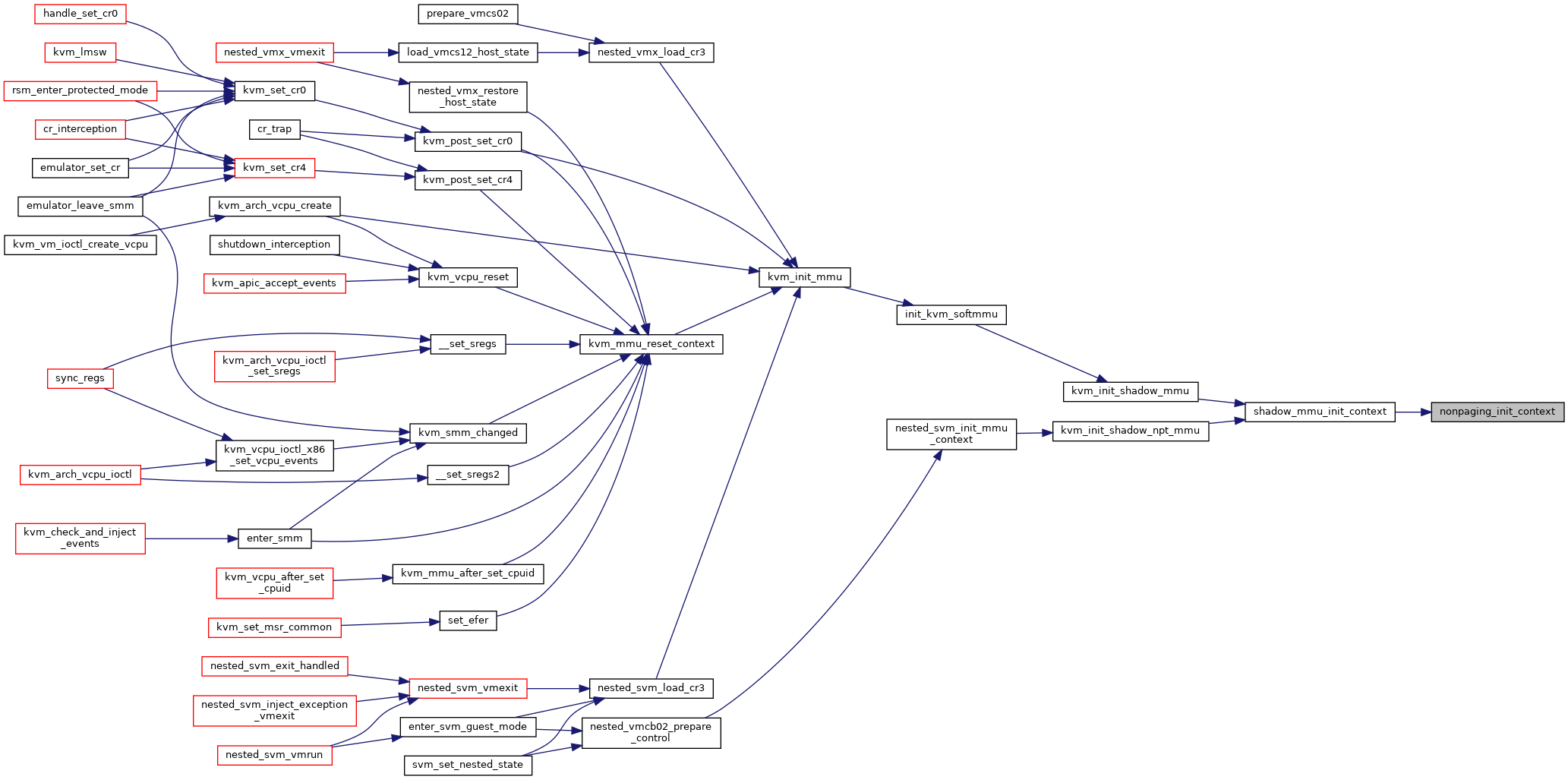
◆ nonpaging_page_fault()
|
static |
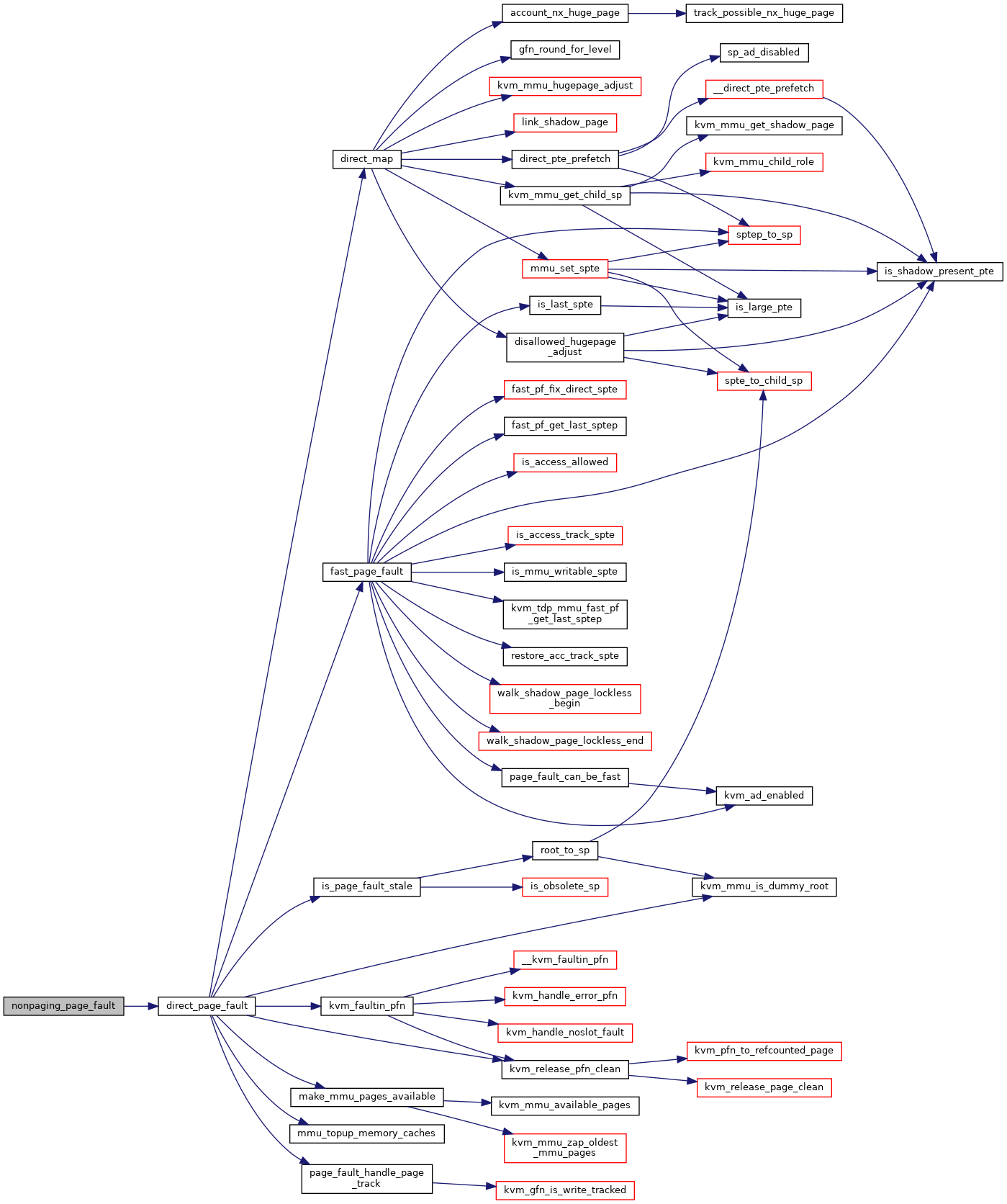
◆ page_fault_can_be_fast()
|
static |

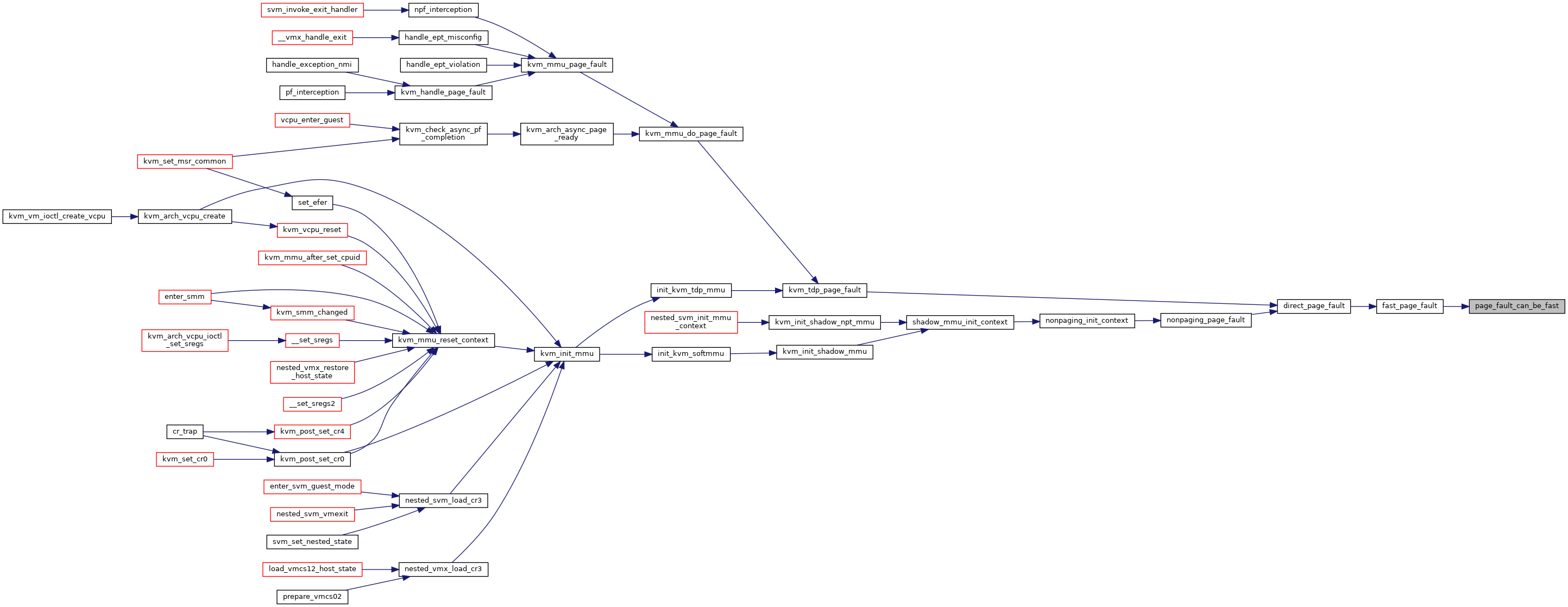
◆ page_fault_handle_page_track()
|
static |

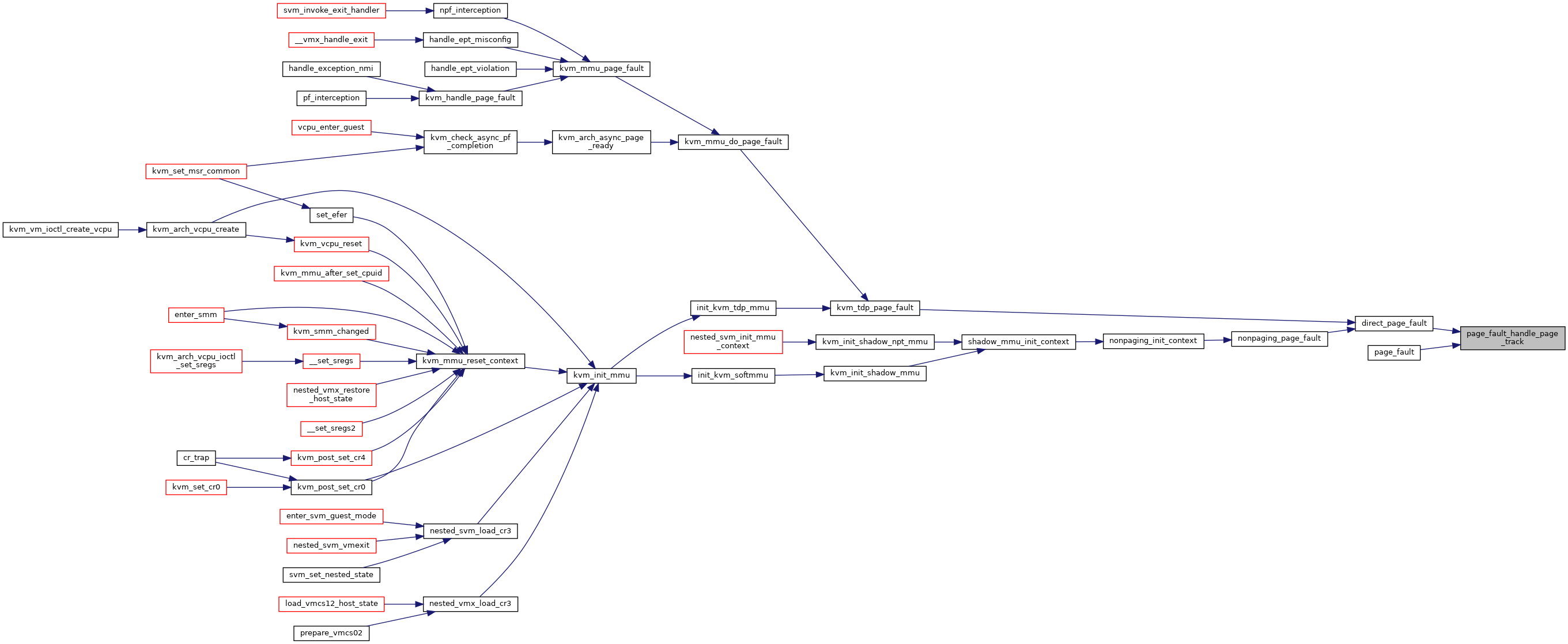
◆ paging32_init_context()
|
static |
◆ paging64_init_context()
|
static |
◆ pte_list_add()
|
static |
◆ pte_list_count()
| unsigned int pte_list_count | ( | struct kvm_rmap_head * | rmap_head | ) |
◆ pte_list_desc_remove_entry()
|
static |

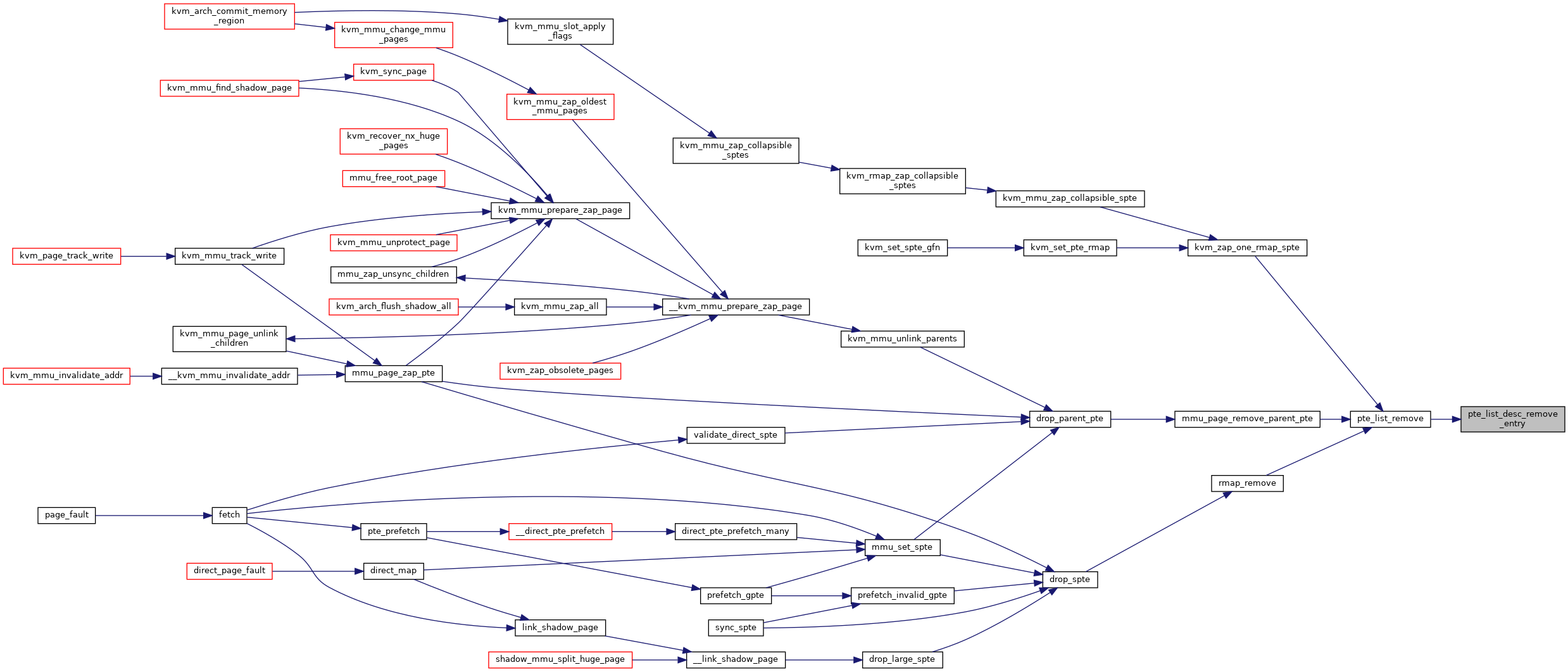
◆ pte_list_remove()
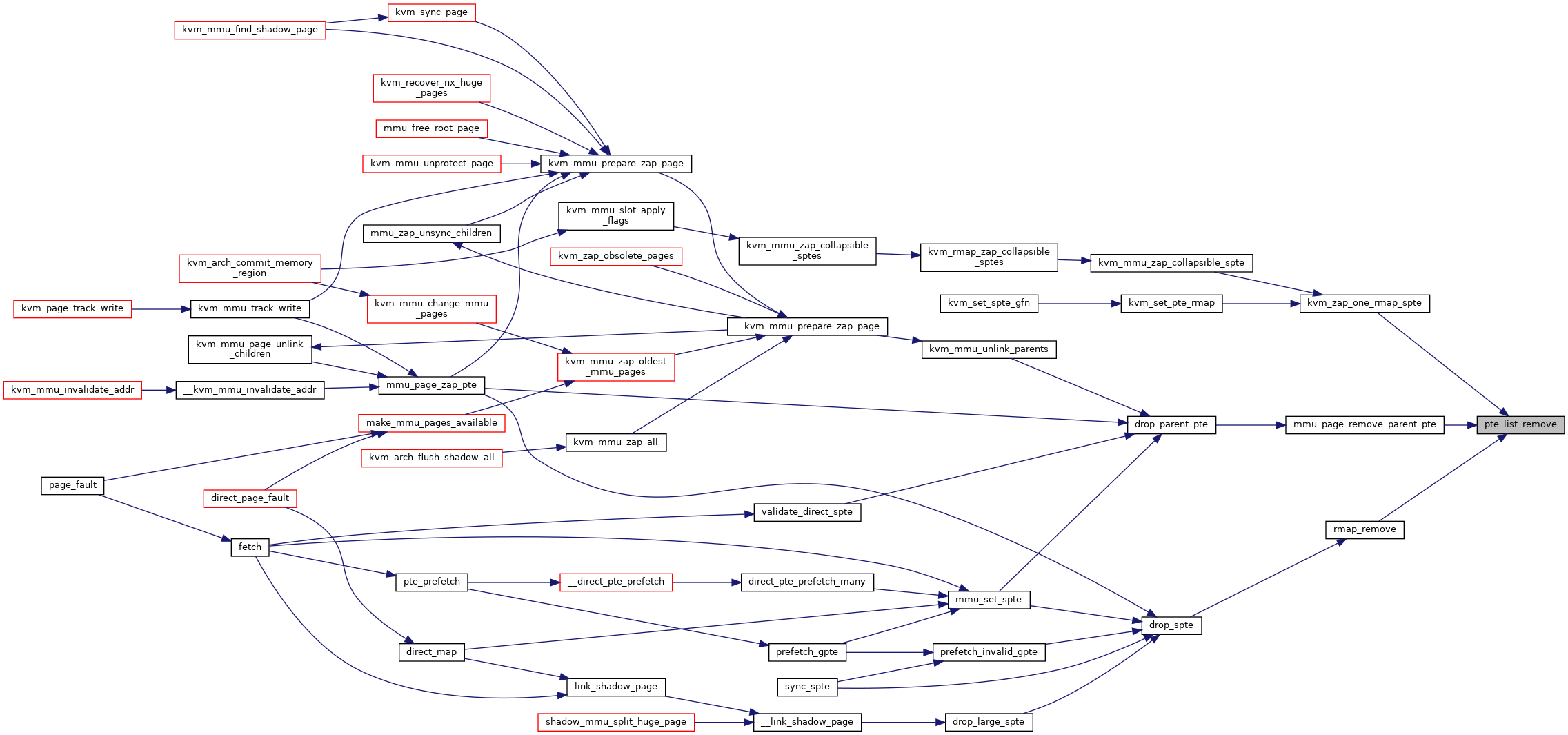
|
static |

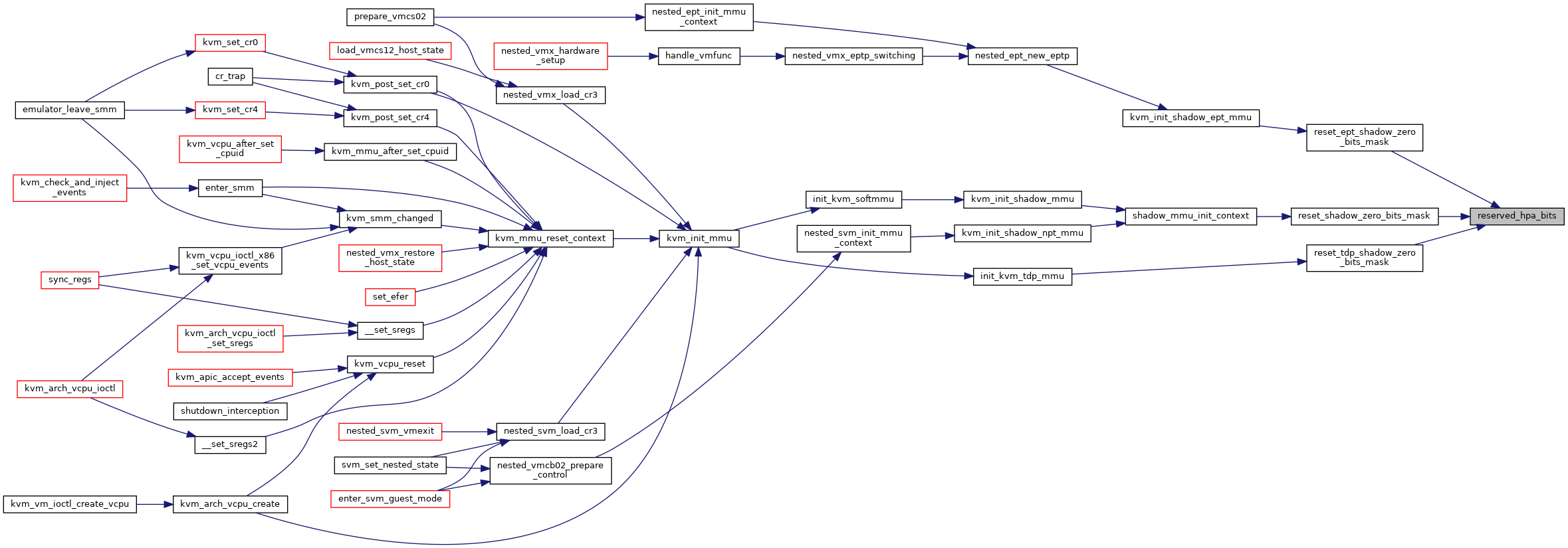
◆ reserved_hpa_bits()
|
inlinestatic |

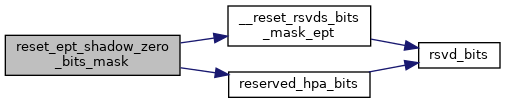
◆ reset_ept_shadow_zero_bits_mask()
|
static |
Definition at line 5062 of file mmu.c.

◆ reset_guest_paging_metadata()
|
static |
Definition at line 5219 of file mmu.c.
◆ reset_guest_rsvds_bits_mask()
|
static |
Definition at line 4917 of file mmu.c.
◆ reset_rsvds_bits_mask_ept()
|
static |


◆ reset_shadow_zero_bits_mask()
|
static |
◆ reset_tdp_shadow_zero_bits_mask()
|
static |
◆ rmap_add()
|
static |
Definition at line 1665 of file mmu.c.
◆ rmap_get_first()
|
static |

◆ rmap_get_next()
|
static |

◆ rmap_remove()
|
static |
◆ rmap_walk_init_level()
|
static |
◆ rmap_write_protect()
|
static |
◆ set_nx_huge_pages()
|
static |
◆ set_nx_huge_pages_recovery_param()
|
static |

◆ shadow_mmu_get_sp_for_split()
|
static |

◆ shadow_mmu_init_context()
|
static |
Definition at line 5360 of file mmu.c.
◆ shadow_mmu_split_huge_page()
|
static |
Definition at line 6504 of file mmu.c.

◆ shadow_mmu_try_split_huge_page()
|
static |
Definition at line 6550 of file mmu.c.

◆ shadow_mmu_try_split_huge_pages()
|
static |
Definition at line 6589 of file mmu.c.

◆ shadow_page_table_clear_flood()
|
static |
Definition at line 4227 of file mmu.c.

◆ shadow_walk_init()
|
static |


◆ shadow_walk_init_using_root()
|
static |

◆ shadow_walk_next()
|
static |


◆ shadow_walk_okay()
|
static |

◆ slot_rmap_walk_init()
|
static |
Definition at line 1520 of file mmu.c.

◆ slot_rmap_walk_next()
|
static |

◆ slot_rmap_walk_okay()
|
static |
◆ slot_rmap_write_protect()
|
static |

◆ sp_has_gptes()
|
static |
◆ spte_clear_dirty()
|
static |

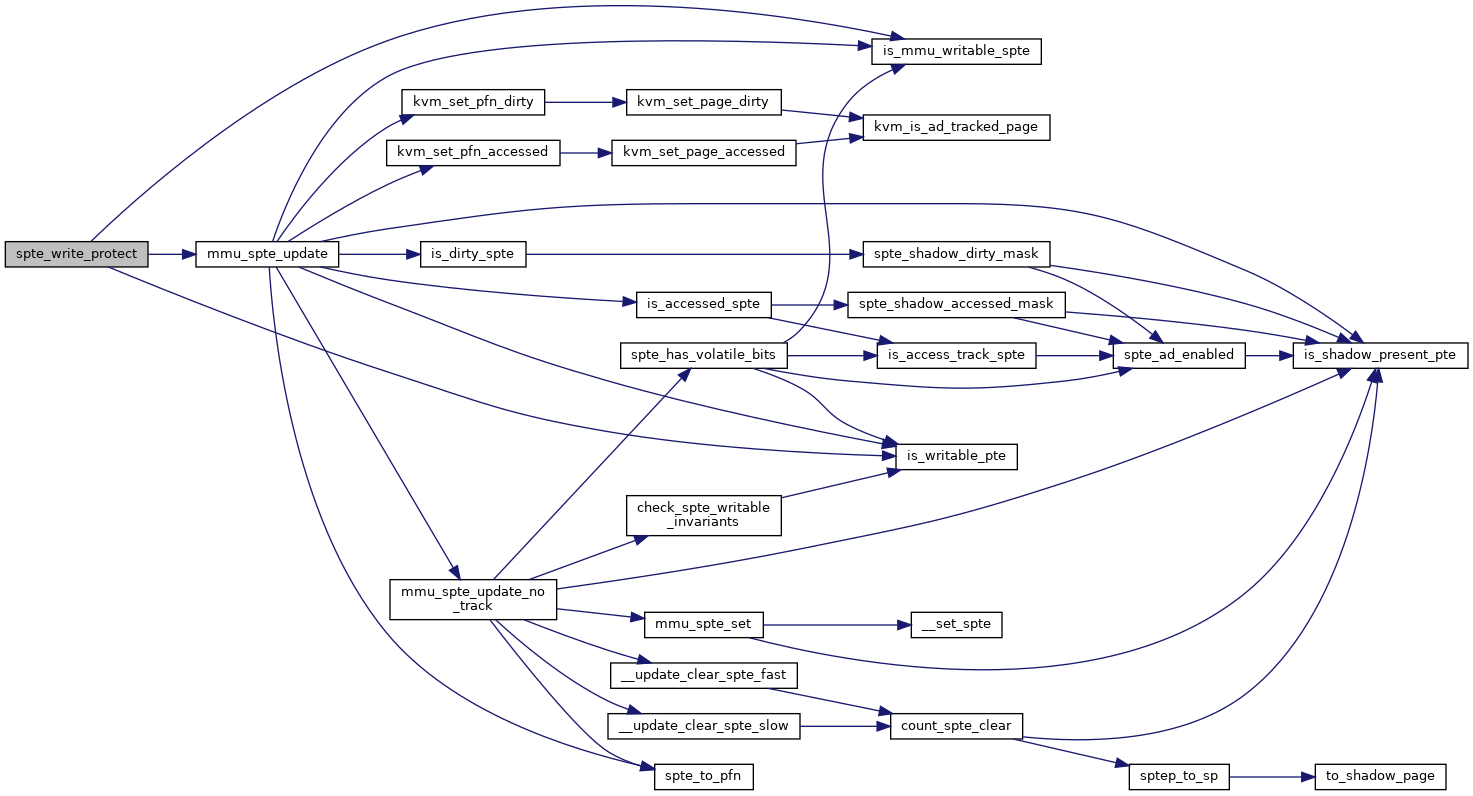
◆ spte_write_protect()
|
static |
◆ spte_wrprot_for_clear_dirty()
|
static |


◆ sync_mmio_spte()
|
static |


◆ topup_split_caches()
|
static |

◆ track_possible_nx_huge_page()
| void track_possible_nx_huge_page | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | sp | ||
| ) |
◆ unaccount_nx_huge_page()
|
static |

◆ unaccount_shadowed()
|
static |
Definition at line 875 of file mmu.c.

◆ untrack_possible_nx_huge_page()
| void untrack_possible_nx_huge_page | ( | struct kvm * | kvm, |
| struct kvm_mmu_page * | sp | ||
| ) |
◆ update_gfn_disallow_lpage_count()
|
static |
◆ update_permission_bitmask()
|
static |
◆ update_pkru_bitmask()
|
static |
◆ validate_direct_spte()
|
static |

◆ vcpu_to_role_regs()
|
static |
Definition at line 242 of file mmu.c.
◆ walk_shadow_page_lockless_begin()
|
static |
Definition at line 645 of file mmu.c.
◆ walk_shadow_page_lockless_end()
|
static |
Definition at line 664 of file mmu.c.

◆ walk_slot_rmaps()
|
static |


◆ walk_slot_rmaps_4k()
|
static |


Variable Documentation
◆ __read_mostly
◆ force_flush_and_sync_on_reuse
|
static |
◆ itlb_multihit_kvm_mitigation
|
extern |
◆ kvm_total_used_mmu_pages
◆ mmu_page_header_cache
◆ mmu_shrinker
◆ nx_huge_pages
| int __read_mostly nx_huge_pages = -1 |
◆ nx_huge_pages_ops
|
static |
◆ nx_huge_pages_recovery_param_ops
|
static |
◆ nx_huge_pages_recovery_period_ms
|
static |
◆ nx_huge_pages_recovery_ratio
|
static |
◆ nx_hugepage_mitigation_hard_disabled
◆ pte_list_desc_cache
◆ tdp_enabled
◆ tdp_mmu_allowed
|
static |